yolov5代码解读中遇到的原理性问题解决
1、为什么通过添加nbs变量来扩大batch_size,而不是直接扩大batch_size的大小?
首先,增大batch_size有三点好处:
(1)内存的利用率提高了,大矩阵乘法的并行化效率提高;
(2)跑完一次epoch(全数据集)所需迭代次数减少,对于相同的数据量的处理速度进一步加快;
(3)一定范围内,batch_size越大,其确定的下降方向就越准,引起训练震荡越小;
当然,有好处就有坏处,坏处也有三点:
(1)服务器内存扛不住;
(2)虽然所需迭代次数减少了,但是想达到相同的精度时间开销,参数的修正更加缓慢;
(3)batch_size增大到一定的程度,其确定的下降方向已经基本不再变化;
总体来说,batch_size的设置应该参考以下几点:
(1)batch数太小,而类别又比较多的时候,真的可能会导致loss函数震荡而不收敛,尤其是在你的网络比较复杂的时候。
(2)随着batch_size增大,处理相同的数据量的速度越快。
(3)随着batch_size增大,达到相同精度所需要的epoch数量越来越多。
(4)由于上述两种因素的矛盾, batch_size增大到某个时候,达到时间上的最优。
(5)由于最终收敛精度会陷入不同的局部极值,因此 batch_size 增大到某些时候,达到最终收敛精度上的最优。
(6)过大的batch_size的结果是网络很容易收敛到一些不好的局部最优点。同样太小的batch也存在一些问题,比如训练速度很慢,训练不容易收敛等。
(7)具体的batch_size的选取和训练集的样本数目相关。
综上所述,yolov5中设置nbs来增加batch_size既继承了大batch的优点,又避免了内存爆炸及训练震荡的问题。
(参考博客:https://blog.csdn.net/zqx951102/article/details/88918948)
2、学习率衰减采用余弦退火方式?
提示:这里可以添加要学的内容
例如:
引入学习率衰减的定义(训练神经网络时一般需要调整学习率,随着epoch的增加,学习率不断衰减),学习率如果太大,容易发生震荡,此时需要调小学习率,如果学习率太小,则训练的时间太长。学习率衰减yolov5中采用余弦退火方式。(参考博客:https://zhuanlan.zhihu.com/p/93624972)
严格的说,余弦退火策略不应该算是学习率衰减策略,因为它使得学习率按照周期变化,其定义方式如下:
optimizer_CosineLR = torch.optim.SGD(net.parameters(), lr=0.1) CosineLR = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_CosineLR, T_max=150, eta_min=0)
其包含的参数和余弦知识一致,参数T_max表示余弦函数周期;eta_min表示学习率的最小值,默认它是0表示学习率至少为正值。确定一个余弦函数需要知道最值和周期,其中周期就是T_max,最值是初试学习率。下图展示了不同周期下的余弦学习率更新曲线:
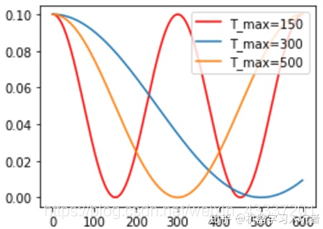
3、mAP@0.5:0.95代表什么?
首先,mAP表示:mean Average Precision(对每一类分别计算AP<平均精确度>,然后做mean平均)
AP是Precision-Recall Curve(PRC)下面的面积:
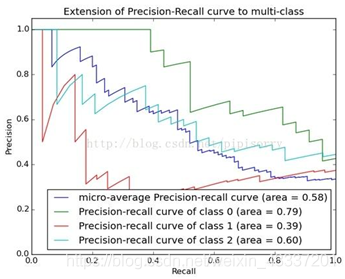
https://blog.csdn.net/weixin_43337201/article/details/108421137

 浙公网安备 33010602011771号
浙公网安备 33010602011771号