opencv的cascade分类器源码分析
1. 概述
CascadeClassifier为OpenCV中cv namespace下用来做目标检测的级联分类器的一个类。该类中封装的目标检测机制,简而言之是滑动窗口机制+级联分类器的方式。OpenCV的早期版本中仅支持haar特征的目标检测,分别在2.2和2.4.0(包含)之后开始支持LBP和HOG特征的目标检测。
2. 支持的特征
对于Haar、LBP和HOG,CascadeClassifier都有自己想对他们说的话:
1) Haar:因为之前从OpenCV1.0以来,一直都是只有用haar特征的级联分类器训练和检测(当时的检测函数称为cvHaarDetectObjects,训练得到的也是特征和node放在一起的xml),所以在之后当CascadeClassifier出现并统一三种特征到同一种机制和数据结构下时,没有放弃原来的C代码编写的haar检测,仍保留了原来的检测部分。另外,Haar在检测中无论是特征计算环节还是判断环节都是三种特征中最简洁的,但是笔者的经验中他的训练环节却往往是耗时最长的。
2) LBP:LBP在2.2中作为人脸检测的一种方法和Haar并列出现,他的单个点的检测方法(将在下面看到具体讨论)是三者中较为复杂的一个,所以当检测的点数相同时,如果不考虑特征计算时间,仅计算判断环节,他的时间是最长的。
3) HOG:在2.4.0中才开始出现在该类中的HOG检测,其实并不是OpenCV的新生力量,因为在较早的版本中HOG特征已经开始作为单独的行人检测模块出现。比较起来,虽然HOG在行人检测和这里的检测中同样是滑窗机制,但是一个是级联adaboost,另一个是SVM;而且HOG特征为了加入CascadeClassifier支持的特征行列改变了自身的特征计算方式:不再有相邻cell之间的影响,并且采用在Haar和LBP上都可行的积分图计算,放弃了曾经的HOGCache方式,虽然后者的加速性能远高于前者,而简单的HOG特征也使得他的分类效果有所下降(如果用SVM分类器对相同样本产生的两种HOG特征做分类,没有了相邻cell影响的计算方式下的HOG特征不那么容易完成分类)。这些是HOG为了加入CascadeClassifier而做出的牺牲,不过你肯定也想得到OpenCV保留了原有的HOG计算和检测机制。另外,HOG在特征计算环节是最耗时的,但他的判断环节和Haar一样的简洁。
关于三种特征在三个环节的耗时有下表:
|
|
Train |
Detect |
|
|
|
|
Feature Extract |
Judge |
|
Haar |
H |
L |
L |
|
LBP |
L |
L |
H |
|
HOG |
L |
H |
L |
3. 内部结构
从CascadeClassifier开始,以功能和结构来整体介绍内部的组织和功能划分。
CascadeClassifer中的数据结构包括Data和FeatureEvaluator两个主要部分。Data中存储的是从训练获得的xml文件中载入的分类器数据;而FeatureEvaluator中是关于特征的载入、存储和计算。在此之外还有检测框架的逻辑部分,是在Data和Featureevaluator之上的一层逻辑。
3.1 Data结构
先来看Data的结构,如下图:
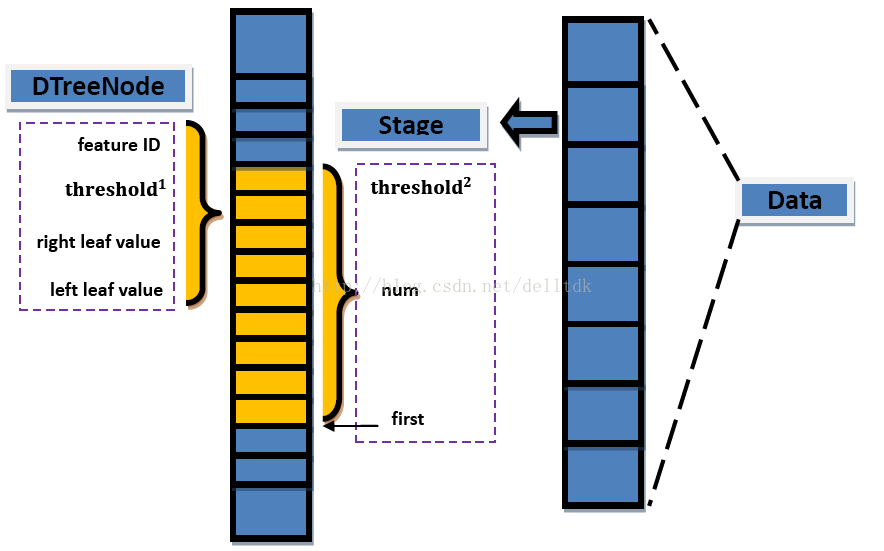
首先,在Data中存储着一系列的DTreeNode,该结构体中记录的是一个弱分类器。其中,feature ID表明它计算的是怎样的一个特征,threshold1是它的阈值,据此判断某个特征值应当属于left还是right,后面的left leafvalue和right leaf value是左右叶节点的值。这里需要结合Stage的判断环节来理解:
假设某个stage(也就是一个强分类器)中包含有num个弱分类器(也就是num个DTreeNode),按照下面的过程计算stage对某个采样图像im的结果。
1) 初始化sum = 0
2) for i = 1:num
计算
if f > threshold1
sum = sum + leftVal
else
sum = sum + rightVal
end
3) if sum > threshold2
output = 1
else
output = 0
其中,ID、threshold1、leftVal和rightVal是第i个弱分类器中的变量,featureExtract表示对im提取第ID个特征值,是该强分类器中的阈值,当结果为正时,输出output=1,否则为0.
另外,可以从上图看到stage结构中仅仅保存了第一个弱分类器的下标first、弱分类器数量num和自身的阈值threshold2,所有弱分类器或者说所有节点都是连续存储在一个vector内的。
3.2 FeatureEvaluator
如果Data结构主要是在载入时保存分类器内部的数据,FeatureEvaluator则是负责特征计算环节。这是一个基类,在此之上衍生了HaarEvaluator、LBPEvaluator和HOGEvaluator三种特征各自的特征计算结构。每个Evaluator中都保存了一个vector<Feature>,这是在read环节中从分类器中载入的特征池(feature pool),前面提到的feature ID对应的就是在这个vector内的下标。三种Evaluator中的Feature定义有所不同,因为计算特征所需的信息不同,具体如下:
Haar——Feature中保存的是3个包含权重的rect,如果要计算下图的特征,

对应的rect为[(R2,-3),(R1,1)]和[(R1,1),(R2,-1)]。这里的R1对应于上图中的红色矩形,R2对应绿色矩形,圆括号内的第二个值为对应的权重。所有Haar特征的描述只需要至多3个加权矩形即可描述,所以HaarEvaluator的Feature中保存的是三个加权矩形;
LBP——Feature中仅保存一个rect,这里需要指出的是,LBP特征计算的不是一个3x3大小的区域中每个点与中心点的大小关系,而是一个3x3个相同大小的矩形区域之间的对比关系,这也是为什么LBP特征计算过程也用到积分图方法的原因。如下图所示,

Feature中保存的就是红色的矩形位置,而我们要先提取上图中9个矩形内的所有像素点的和,然后比较外围8个矩形内的值和中间矩形内的值的关系,从而得到LBP特征。
HOG——与LBP中类似,Feature中同样仅一个rect,HOG特征是在2x2个rect大小的范围内提取出的,也就是说给出的rect是HOG计算过程中4个block里的左上角的block。
除此之外,Evaluator中还有另外一个很重要的数据结构——数据指针。这个结构在三种Evaluator中同样不同,但他们所指向的都是积分图中的一个值。在Haar和LBP中是先计算一个整图的积分图,而HOG中则是计算梯度方向和梯度幅值,然后按照梯度方向划分的区间将梯度幅值图映射成n个积分图。每个特征的计算过程中要维护一系列指向积分图中的指针,通过访问积分图快速计算某个矩形内的像素值的和,从而加速特征计算环节。这里暂不详细展开。
3.3 检测框架逻辑
这里的检测框架简而言之就是一个多尺度缩放+滑动窗口遍历搜索的框架。在CascadeClassifier中包含detectMultiScale和detectSingleScale成员函数,分别对应多尺度和单尺度检测,其中多尺度检测中会调用单尺度的方法。
分类器仅能够对某一固定size的采样图像做判断,给出当前的采样图像是否为真实目标的“非正即负”的结果(size是由训练数据决定的)。要找到某个图像中的目标位置,就要以size大小的采样窗口对图像逐行逐列地扫描,然后对每个采样图像判断是否为正,将结果以矩形位置保存下来就获得了目标的位置。但是这仅仅是单尺度检测,也就是说,一个以40x40大小训练数据训练获得的分类器只能检测当前图像里40x40大小的目标,要检测80x80大小的目标该如何做呢?可以把原图像缩放到原来的1/2,这样原图中80x80大小的目标就变成40x40了,再做一次上面的扫描检测过程,并且将得到的矩形换算到原图中对应的位置,从而检测到了80x80大小的目标。实际上,我们每次对原图进行固定步长的缩放,形成一个图像金字塔,对图像金字塔的每一层都扫描检测,这就是多尺度检测的框架。
4. 模块功能
CascadeClassifier的使用中只要调用两个外部接口,一个是read,另一个是detectMultiScale。
4.1 CascadeClassifier::read
4.1.1 分类器的XML形式
read的过程就是对类的成员变量进行初始化的过程,经过这一步,Data结构按照之前已经讨论的逻辑被填充。
先来看一下一个分类器的xml文件是怎样组织的。

整体上它包括stageType、featureType、height、width、stageParams、featureParams、stages、features几个节点。
这里的参数内容就不展开了,主要来看一下stage结构和feature在xml里是怎样保存的,这样训练结束后你可以自己打开这个文件看一下就明白训练了一个什么分类器出来了。
下面是一个stage的内部结构,maxWeakCount是stage包含的弱分类器个数,stageThreshold是该stage的阈值,也就是上面我们提到过的。接下来就是5个弱分类器了,每个弱分类器中包括internalNodes和leafValues两个节点。前者分别是left和right标记、feature ID和threshold1。
这里可以解释一下featureID到底是指在哪里的ID了。下图是分类器中的features节点中保存的该分类器使用到的各种特征值,feature ID就是在这些中的ID,就是在这些之中的顺序位置。图中的特征是一个HOG特征,rect节点中的前四个数字代表我们提到的矩形,而最后的1表示要提取的特征值是block中提取的36维向量中的哪一个。当然,Haar和LBP特征的feature节点与此不同,不过也是类似的结构。

4.1.2 读取的过程
清楚了分类器的xml形式之后,就要从文件中读取内容至cascadeClassifier中了。可以把这部分分为Data的读取和features的读取两部分。
bool CascadeClassifier::read(constFileNode& root)
{
if( !data.read(root) )//Data的读取
return false;
featureEvaluator = FeatureEvaluator::create(data.featureType);
FileNode fn= root[CC_FEATURES];
if( fn.empty() )
return false;
return featureEvaluator->read(fn);//features的读取
}
4.1.2.1 Data的读取
先来看看Data的读取,这里以HOG特征的分类器为例,并且跳过stage的参数读取部分,直接来看如何在Data中建立stage结构的。
// load stages
fn = root[CC_STAGES];
if( fn.empty() )
return false;
stages.reserve(fn.size());//先给vector<Stage>分配空间出来
classifiers.clear();
nodes.clear();
FileNodeIteratorit =fn.begin(),it_end= fn.end();
for( int si = 0; it != it_end; si++, ++it )//遍历stages
{
//进入单个stage中
FileNodefns = *it;
Stagestage;//stage结构中包含threshold、ntrees和first三个变量
stage.threshold = (float)fns[CC_STAGE_THRESHOLD]-THRESHOLD_EPS;
fns= fns[CC_WEAK_CLASSIFIERS];
if(fns.empty())
returnfalse;
stage.ntrees = (int)fns.size();
stage.first = (int)classifiers.size();//ntrees和first指出该stage中包含的树的数目和起始位置
stages.push_back(stage);//stage被保存在stage的vector(也就是stages)中
classifiers.reserve(stages[si].first +stages[si].ntrees);//相应地扩展classifiers的空间,它存储的是这些stage中的weak classifiers,也就是weak trees
FileNodeIteratorit1 =fns.begin(),it1_end= fns.end();//遍历weak classifier
for( ; it1 != it1_end;++it1 )// weaktrees
{
FileNodefnw = *it1;
FileNodeinternalNodes =fnw[CC_INTERNAL_NODES];
FileNodeleafValues =fnw[CC_LEAF_VALUES];
if(internalNodes.empty()||leafValues.empty())
returnfalse;
DTreetree;
tree.nodeCount = (int)internalNodes.size()/nodeStep;//一个节点包含nodeStep个值,计算得到当前的弱分类器中包含几个节点,无论在哪种特征的分类器中这个值其实都可以默认为1
classifiers.push_back(tree);//一个弱分类器或者说一个weak tree中只包含一个int变量,用它在classifiers中的位置和自身来指出它所包含的node个数
nodes.reserve(nodes.size() +tree.nodeCount);
leaves.reserve(leaves.size() +leafValues.size());//扩展存储node和leaves的vector结构空间
if(subsetSize > 0 )//关于subsetSize的内容都是只在LBP分类器中使用
subsets.reserve(subsets.size() +tree.nodeCount*subsetSize);
FileNodeIteratorinternalNodesIter =internalNodes.begin(),internalNodesEnd= internalNodes.end();
//开始访问节点内部
for(; internalNodesIter != internalNodesEnd; )//nodes
{
DTreeNodenode;//一个node中包含left、right、threshold和featureIdx四个变量。其中left和right是其对应的代号,left=0,right=-1;featureIdx指的是整个分类器中使用的特征池中某个特征的ID,比如共有108个特征,那么featureIdx就在0~107之间;threshold是上面提到的。同时可以看到这里的HOG分类器中每个弱分类器仅包含一个node,也就是仅对某一个特征做判断,而不是多个特征的集合
node.left = (int)*internalNodesIter; ++internalNodesIter;
node.right = (int)*internalNodesIter; ++internalNodesIter;
node.featureIdx = (int)*internalNodesIter; ++internalNodesIter;
if(subsetSize > 0 )
{
for(intj = 0; j < subsetSize;j++, ++internalNodesIter)
subsets.push_back((int)*internalNodesIter);
node.threshold = 0.f;
}
else
{
node.threshold = (float)*internalNodesIter; ++internalNodesIter;
}
nodes.push_back(node);//得到的node将保存在它的vector结构nodes中
}
internalNodesIter=leafValues.begin(),internalNodesEnd =leafValues.end();
for(; internalNodesIter != internalNodesEnd; ++internalNodesIter)// leaves
leaves.push_back((float)*internalNodesIter);//leaves中保存相应每个node的left leaf和right leaf的值,因为每个weak tree只有一个node也就分别只有一个left leaf和right leaf,这些将保存在leaves中
}
}
通过stage树的建立可以看出最终是获取stages、classifiers、nodes和leaves四个vector变量。其中的nodes和leaves共同组成一系列有序节点,而classifiers中的变量则是在这些节点中查询来构成一个由弱分类器组,它仅仅是把这些弱分类器组合在一起,最后stages中每一个stage也就是一个强分类器,它在classifiers中查询得到自己所属的弱分类器都有哪些,从而构成一个强分类器的基础。
4.1.2.2 features的读取
特征的读取最终将保留在featureEvaluator中的vector<Feature>中。所以先来看一下Feature的定义,仍旧以HOG特征为例:
struct Feature
{
Feature();
float calc( int offset )const;
void updatePtrs( const vector<Mat>&_hist,constMat &_normSum);
bool read( const FileNode&node);
enum { CELL_NUM = 4, BIN_NUM= 9 };
Rectrect[CELL_NUM];
int featComponent; //componentindex from 0 to 35
const float* pF[4]; //for feature calculation
const float* pN[4]; //for normalization calculation
};
其中的CELL_NUM和BIN_NUM分别是HOG特征提取的过程中block内cell个数和梯度方向划分的区间个数。也就是说,在一个block内将提取出CELL_NUM*BIN_NUM维度的HOG特征向量。rect[CELL_NUM]保存的是block的四个矩形位置,featComponent表明该特征是36维HOG特征中的哪一个值。而之后的pF与pN是重点:首先我们假设featComponent=10,那就是说要提取的特征值是该rect描述的block内提取的HOG特征的第10个值,而第一个cell中会产生9个值,那么第10个值就是第二个cell中的第一个值。通过原图计算梯度和按照区间划分的梯度积分图之后,共产生9个积分图,那么pF应当指向第1个积分图内rect描述的block内的第二个cell矩形位置的四个点。
在featureEvaluator的read中,将对所有features遍历填充到vector<Feature>中。
在下面的代码中只是读取了参数,并没有更新pF和pN指针,因为我们还没有获得梯度积分图。
bool HOGEvaluator::Feature :: read(const FileNode&node )
{
FileNodernode =node[CC_RECT];//rect节点下包括一个矩形和一个特征类型号featComponent
FileNodeIteratorit =rnode.begin();
it>> rect[0].x>> rect[0].y>> rect[0].width>> rect[0].height>> featComponent;//featComponent范围在[0,35],36类特征中的一个
rect[1].x =rect[0].x +rect[0].width;
rect[1].y =rect[0].y;
rect[2].x =rect[0].x;
rect[2].y =rect[0].y +rect[0].height;
rect[3].x =rect[0].x +rect[0].width;
rect[3].y =rect[0].y +rect[0].height;
rect[1].width =rect[2].width =rect[3].width =rect[0].width;
rect[1].height =rect[2].height =rect[3].height =rect[0].height;
//xml中的rect存储的矩形信息与4个矩形之间的关系如下图4所示
return true;
}
4.2 CascadeClassifier::detectMultiScale
这里的代码的伪码可以简单写成如下:
vector<Rect> results;
for( doublefactor = 1; ;factor*= scaleFactor )
{
MatscaledImage(scaledImageSize,CV_8U,imageBuffer.data);
resize( grayImage,scaledImage,scaledImageSize,0, 0, CV_INTER_LINEAR );
detectSingleScale( scaledImage,results );
}
groupRectangles( results );
简单来说,多尺度检测只是尺度缩放形成图像金字塔然后在每个尺度上检测之后将结果进行合并的过程。
在detectSingleScale中,使用OpenCV中的并行计算机制,以CascadeClassifierInvoker类对整图扫描检测。detectSingleScale的检测过程仍以伪码表达如下:
// detectSingleScale
featureEvaluator->setImage(image,data.origWinSize )
//CascadeClassifierInvoker
for( int y = 0; y <height; y +=yStep )
for(int x = 0; x <width; x +=xStep )
{
doublegypWeight;
int result=classifier->runAt(evaluator,Point(x, y), gypWeight);
results.push_back(R(x,y,W,H,scale));// R(x,y,W,H,scale)表示在scale尺度下检测到的矩形(x,y,W,H)映射到原图上时的矩形
}
可以看到上面的代码中最重要的两部分分别是setImage和runAt。
4.2.1 setImage
前面提到过,features的read部分仅仅把特征的参数读取进入vector<Feature>中,并没有对指针们初始化,这正是setImage要做的工作。仍以HOG为例,setImage的伪码如下:
vector<Mat> hist;
Mat norm;
integralHistogram( image,hist, norm );
for( featIdx= 0;featIdx < featCount;featIdx++ )
{
featuresPtr[featIdx].updatePtrs( hist, norm );
}
integralHistogram的过程如下:首先计算image每个像素点的梯度幅值和梯度方向,梯度方向的区间为0~360°,划分为9个区间,按照梯度方向所属区间统计每个区间内image的梯度幅值的积分图。也就是说,对于hist中的第一个Mat来说,先把所有梯度方向在0~40°之外的像素点的幅值置为0,然后计算梯度幅值图的积分图,保存为hist[0];第二个Mat对应40~80°的区间……这样,得到一个包含9个Mat的hist,而norm则是9个Mat对应像素点的和。
接下来就是要根据hist和norm来更新每个Feature中的指针了,因为我们已经知道自己要计算的是一个在什么位置上的矩形、在那个区间上的特征,所以只要把指针更新到hist中的那个Mat上即可。注意,这里并没有涉及到滑动窗口机制。
这样在计算某个HOG特征值时,我们只要计算下面的式子即可:
HOG(i) = (pF[0]+pF[3]-pF[1]-pF[2] )/( pN[0]+pN[3]-pN[1]-pN[2] )
4.2.2 runAt
runAt函数调用了其他方法,但它的伪码可以如下:
setWindow( hist, cvPoint(x,y) );
for(intstageIdx= 0; stageIdx <nstages;stageIdx++ )
{
stage= cascadeStages[stageIdx];//当前stage
sum= 0.0;
int ntrees = stage.ntrees;
for( int i = 0; i < ntrees; i++, nodeOfs++,leafOfs+= 2 )
{
node= cascadeNodes[nodeOfs];//当前node
doublevalue =featureEvaluator(node.featureIdx);//计算vector<Feature>中的第featureIdx个特征的值
sum+= cascadeLeaves[ value< node.threshold? leafOfs : leafOfs+ 1 ];//根据node中的threshold得到左叶子或者右叶子的值,加到该stage中的总和
}
if( sum < stage.threshold )//如果总和大于stage的threshold则通过,小于则退出,并返回当前stage的相反数
return-stageIdx;
}
setWindow是根据当前的位置(x,y)计算Feature中的指针应当在积分图上的偏移量,可以看到这里才是滑动窗口机制实现的真正部分,而不是在setImage中,setImage只是给出各个特征对应的指针相对位置,而不是真实位置。
后面在stage和node中的遍历和检测,正是体现弱分类器、强分类器和级联分类器的概念。当stage中有一个不满足时,立即退出不再进入下一级,这是级联分类器的概念;弱分类器的判定仅仅给出一个分数,若干个弱分类器的分数的和作为强分类器的判定依据,这是强弱分类器的概念。
4.3 LBP的判定
这里的HOG的例子,与Haar很相似,只是特征计算环节有所不同,在判定环节都是根据某个阈值来判断,但是LBP除了在特征计算环节不同以外,在判定环节也大不相同。训练获得的LBP分类器的node中包含8个数存储在subset中,与node的存储很类似。然后在判定阶段按照下式
t = subset[c>>5]& (1 << (c & 31))
其中c是提取得到的LBP特征值。当t为0时,结果为左叶,为1时,结果为右叶。
4.4 groupRectangles
最终的结果由于在多尺度上获得,因而矩形之间难免有重合、重叠和包含的关系,由于缩放尺度可能相对于目标大小比较小,导致同一个目标在多个尺度上被检测出来,所以有必要进行合并。OpenCV的合并规则中有按照权重合并的,也有以MeanShift方法合并的,最简单的一种是直接按照位置和大小关系合并。首先将所有矩形按照大小位置合并成不同的类别,然后将同一类别中的矩形合并成同一个矩形,当不满足给出的阈值条件时,该矩形不会被保存下来。这一部分不是检测的核心,不做详细讨论。
5. 保留的Haar支持
之前已经说过,老版本的OpenCV中只支持Haar特征的分类器训练和检测,所以有大量性能表现优秀的老版本Haar分类器已经训练获得,如果新版本的CascadeClassifier不能支持这些分类器,那是非常遗憾的事。所以CascadeClassifier中在做新版本分类器载入之后,如果失败将会按照老版本的分类器再做一次载入,并且保存到odlCascade指针中。在做检测时,如果oldCascade不为空,则按照老版本的Haar分类器做检测。这个过程完全是以C风格的代码完成,是对OpenCV2.2之前版本的继承。
原文:https://blog.csdn.net/u011783201/article/details/52184300

 浙公网安备 33010602011771号
浙公网安备 33010602011771号