yolov1,v2,v3的比较 小哼哼
因为这周要做ppt,只阅读yolov3的文章感觉还是不够,故作此次记录去比较yolo发展的不同,加强记忆辣。
一.网络结构的不同
 图1 YOLOv1的网络架构,24卷积层+2FC(全连接层)
图1 YOLOv1的网络架构,24卷积层+2FC(全连接层) 图2 YOLOv2的网络架构,22卷积层,global average pooling替代了FC(全连接层)
图2 YOLOv2的网络架构,22卷积层,global average pooling替代了FC(全连接层)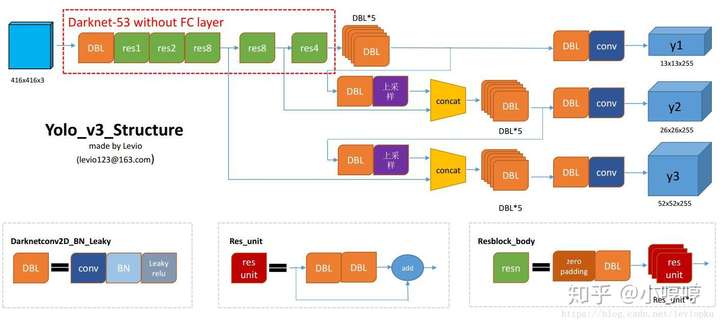 图3 YOLOv3网络结构 Darknet-53 106个卷积层
图3 YOLOv3网络结构 Darknet-53 106个卷积层
首先,从网络结构上说,YOLOv1是卷积层、迟化层和全连接层的组合;
YOLOv2在v1的基础上,去掉了全连接层,在每一个卷积层后边都添加了一个批一化层(batch normalization),并且对每一批数据都做了归一化的预处理,这两个改变就可以提升了算法的速度;
YOLOv3在网络结构上采用的是Darknet-53,在v2的基础上每隔两层增加了一个residual networks(残差网络),即short cut层,使用这种办法对于训练很深层的网络呢,可以解决梯度消失或者梯度爆炸的问题。残差网络的作用:https://blog.csdn.net/qq_34886403/article/details/83961424
二.训练误差
 图 4 YOLOV1
图 4 YOLOV1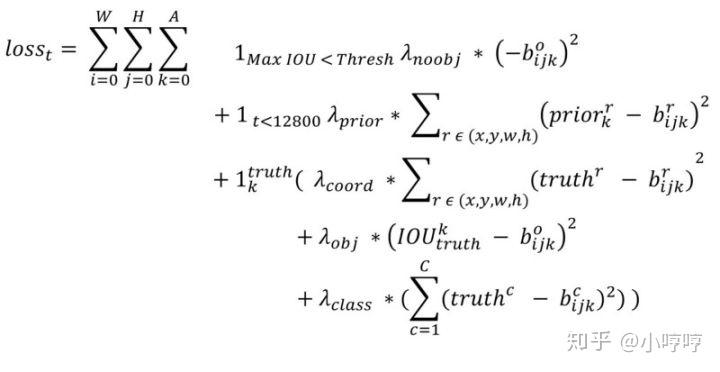 图5 YOLOv2
图5 YOLOv2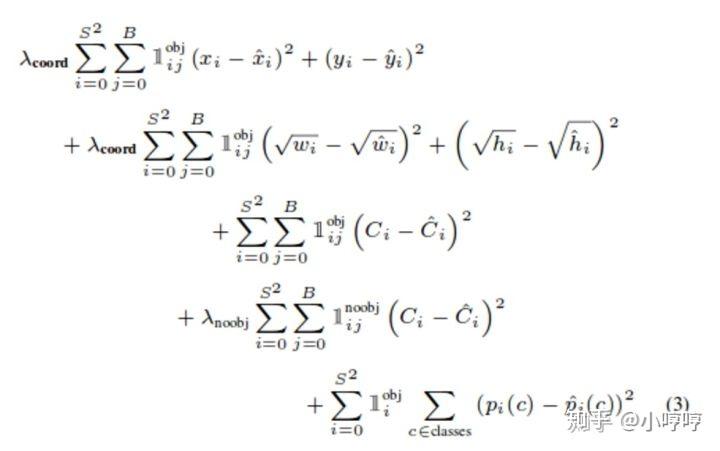 图 6 YOLOv3
图 6 YOLOv3
对于yolov3来说,坐标误差是和YOLOv1一样的,但是对于后三项,即IOU误差和分类误差来说,yolov3使用的是二元交叉熵误差来替代。以下是二元交叉熵的知识:小飞鱼:损失函数——交叉熵损失函数。交叉熵可以用在神经网络中的分类问题,结合交叉熵当损失函数时,在模型效果差的时候学习速度比较快,在模型效果好的时候学习速度变慢。
三.细节的不同
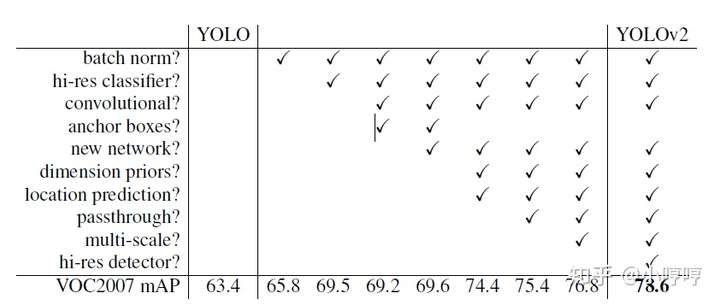 图7 YOLOv1-->YOLOv2
图7 YOLOv1-->YOLOv2
上图呢是对yolov1做了相对应的改变时,同一数据集上mAP的改变量。(等比完了再说说啥是AP)
加了BN层,mAP可以提高2.4%;加了高分辨率分类器,可以提高3.7%;加了卷积层和锚框,虽然mAP略降一点(0.3%),但是其他的性能会提高;使用维度优先和定位预测,又可以增加4.8%;增加passthrought,又可增加1%,最后增加高精度检测器,又可以增加1.4%。
v1的缺陷:虽然使用了B个边界框,但是最后只输出一个检测的结果,这就出现一张图片只能够检测一个物体的情况。
再者呢,YOLOv1最后两层是全连接层,参数冗余。在检测时,YOLO 训练模型只支持与训练图像相同的输入分辨率。其它分辨率需要缩放成此固定分辨率;由此呢就迎来了YOLOv2的出生!
BN层也就是batch normalization层,YOLOv2在输入数据时就先做了一次归一化处理,然后后期每一层卷积层之后都增加了一个BN(批归一化层)也就是把数据都限制在了相似的范围之内,可以加快训练的速度。也有防止过拟合的作用,v2加入BN之后,也删除了dropout,且发现神经网络并没有出现过拟合。可以参考:
https://blog.csdn.net/CHNguoshiwushuang/article/details/80411361
YOLOv3和YOLOv2区别
1.锚框使用Kmeans聚类的方法,一共九个锚框,每个尺寸的特征图呢使用3个锚框。
2.loss后面三项用二分类交叉熵代替原始的误差和平方。
3.多尺度预测,增加对细粒度物体的检测力度。
4.大量使用残差网络,对训练更深度的神经网络而言,可以消除梯度消失或梯度爆炸的问题。
遇到的小问题之一:
锚框如何使用?
在没有锚框时,把物体分给物体中心所在的grid cell中判别;
有了锚框之后,把物体分给物体中心所在的grid cell,并且还分给了和物体对象形状交并比最高的一个锚框。

原文:https://zhuanlan.zhihu.com/p/73606306?from_voters_page=true

 浙公网安备 33010602011771号
浙公网安备 33010602011771号