深度学习人脸关键点检测方法----综述
参考资料
一、 引言
二、 检测方法
总结
近期对人脸关键点相关方法进行了研究,在深度学习大行其道的背景之下,此博客对近期人脸关键点检测深度学习方法进行了记录和总结,希望给广大朋友一点点启发,也希望大家指出我阅读过程中的错误~
主要有如下模型:
2.1 ASM (Active Shape Models)
2.2 AAM(Active Appearance Models)
2.3 CPR(Cascaded pose regression)
2.4 DCNN
2.5 Face++版DCNN
2.6 TCDCN
2.7 MTCNN
2.8 TCNN(Tweaked Convolutional Neural Networks)
2.9 DAN(Deep Alignment Networks)
先贴参考资料,想进入主题的直接跳过
参考资料
主要参考资料:
2017-Facial feature point detection A comprehensive survey–综述
标注文献:
[1] T.F. Cootes, C.J. Taylor, D.H. Cooper, et al. Active Shape Models-Their Training and Application[J]. Computer Vision and Image Understanding, 1995, 61(1):38-59.
[2] G. J. Edwards, T. F. Cootes, C. J. Taylor. Face recognition using active appearance models[J]. Computer Vision — Eccv’, 1998, 1407(6):581-595.
[3] Cootes T F, Edwards G J, Taylor C J. Active appearance models[C]// European Conference on Computer Vision. Springer Berlin Heidelberg, 1998:484-498.
[4] Dollár P, Welinder P, Perona P. Cascaded pose regression[J]. IEEE, 2010, 238(6):1078-1085.
[5] Sun Y, Wang X, Tang X. Deep Convolutional Network Cascade for Facial Point Detection[C]// Computer Vision and Pattern Recognition. IEEE, 2013:3476-3483.
[6] Zhou E, Fan H, Cao Z, et al. Extensive Facial Landmark Localization with Coarse-to-Fine Convolutional Network Cascade[C]// IEEE International Conference on Computer Vision Workshops. IEEE, 2014:386-391.
[7] Zhang Z, Luo P, Chen C L, et al. Facial Landmark Detection by Deep Multi-task Learning[C]// European Conference on Computer Vision. 2014:94-108.
[8] Wu Y, Hassner T. Facial Landmark Detection with Tweaked Convolutional Neural Networks[J]. Computer Science, 2015.
[9] Zhang K, Zhang Z, Li Z, et al. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks[J]. IEEE Signal Processing Letters, 2016, 23(10):1499-1503.
[10] Kowalski M, Naruniec J, Trzcinski T. Deep Alignment Network: A Convolutional Neural Network for Robust Face Alignment[J]. 2017:2034-2043.
[11] Cristinacce D, Cootes T F. Feature Detection and Tracking with Constrained Local Models[C]// British Machine Vision Conference 2006, Edinburgh, Uk, September. DBLP, 2006:929-938.
[12] Lucey S, Wang Y, Cox M, et al. Efficient Constrained Local Model Fitting for Non-Rigid Face Alignment[J]. Image & Vision Computing, 2009, 27(12):1804.
[13] Wang Y, Lucey S, Cohn J F. Enforcing convexity for improved alignment with constrained local models[C]// IEEE Conference on Computer Vision & Pattern Recognition. Proc IEEE Comput Soc Conf Comput Vis Pattern Recognit, 2008:1.
[14] Saragih J M, Lucey S, Cohn J F. Deformable Model Fitting by Regularized Landmark Mean-Shift[M]. Kluwer Academic Publishers, 2011.
[15] Papandreou G, Maragos P. Adaptive and constrained algorithms for inverse compositional Active Appearance Model fitting[C]// Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on. IEEE, 2014:1-8.
[16] Matthews I, Baker S. Active Appearance Models Revisited[J]. International Journal of Computer Vision, 2004, 60(2):135-164.
[17] Amberg B, Blake A, Vetter T. On compositional Image Alignment, with an application to Active Appearance Models[C]// Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. IEEE, 2009:1714-1721.
[18] Smith B M, Zhang L, Brandt J, et al. Exemplar-Based Face Parsing[C]// Computer Vision and Pattern Recognition. IEEE, 2013:3484-3491.
[19] Zhou F, Brandt J, Lin Z. Exemplar-Based Graph Matching for Robust Facial Landmark Localization[C]// IEEE International Conference on Computer Vision. IEEE Computer Society, 2013:1025-1032.
[20] Coughlan J M, Ferreira S J. Finding Deformable Shapes Using Loopy Belief Propagation[C]// European Conference on Computer Vision. Springer-Verlag, 2002:453-468.
[21] Liang L, Wen F, Xu Y Q, et al. Accurate Face Alignment using Shape Constrained Markov Network[C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2006:1313-1319.
[22] Wei Y. Face alignment by Explicit Shape Regression[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2012:2887-2894.
[23] Xiong X, Torre F D L. Supervised Descent Method and Its Applications to Face Alignment[C]// Computer Vision and Pattern Recognition. IEEE, 2013:532-539.
[24] Tang X, Wang X, Luo P. Hierarchical face parsing via deep learning[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2012:2480-2487.
[25] Wu Y, Wang Z, Ji Q. Facial Feature Tracking Under Varying Facial Expressions and Face Poses Based on Restricted Boltzmann Machines[C]// Computer Vision and Pattern Recognition. IEEE, 2013:3452-3459.
[26] Zhang J, Shan S, Kan M, et al. Coarse-to-Fine Auto-Encoder Networks (CFAN) for Real-Time Face Alignment[C]// European Conference on Computer Vision. Springer, Cham, 2014:1-16.
[27] Wang N, Gao X, Tao D, et al. Facial Feature Point Detection: A Comprehensive Survey[J]. Neurocomputing, 2017.
[28] Learnedmiller E, Lee H, Huang G B. Learning hierarchical representations for face verification with convolutional deep belief networks[C]// Computer Vision and Pattern Recognition. IEEE, 2012:2518-2525.
相关博客:
http://blog.csdn.net/yang_xian521/article/details/7468571
http://blog.sina.com.cn/s/blog_6d8e91f401015pv5.html
http://blog.163.com/huai_jing@126/blog/static/1718619832013111525150259/
http://blog.csdn.net/cbl709/article/details/46239571
http://blog.csdn.net/colourfulcloud/article/details/9774017
http://blog.csdn.net/u011058765/article/details/53976876.
https://www.cnblogs.com/gavin-vision/p/4829016.html
http://blog.csdn.net/hjimce/article/details/50099115( face++ 2013)
http://blog.csdn.net/tinyzhao/article/details/52730553(TCDCN)
http://blog.csdn.net/qq_28618765/article/details/78128619(TCDCN)
http://blog.csdn.net/tinyzhao/article/details/53236191(MTCNN)
http://blog.csdn.net/qq_14845119/article/details/52680940(MTCNN,推荐)
http://blog.csdn.net/tinyzhao/article/details/53559373(TCNN)
http://blog.csdn.net/qq_28618765/article/details/78044098(TCNN)
http://blog.csdn.net/zjjzhaohang/article/details/78100465(DAN)
http://blog.csdn.net/shuzfan/article/details/77839176(DAN)
一、 引言
人脸关键点检测也称为人脸关键点检测、定位或者人脸对齐,是指给定人脸图像,定位出人脸面部的关键区域位置,包括眉毛、眼睛、鼻子、嘴巴、脸部轮廓等;
我们把关键点的集合称作形状(shape),形状包含了关键点的位置信息,而这个位置信息一般可以用两种形式表示,第一种是关键点的位置相对于整张图像,第二种是关键点的位置相对于人脸框(标识出人脸在整个图像中的位置)。我们把第一种形状称作绝对形状,它的取值一般介于 0 到 w or h,第二种形状我们称作相对形状,它的取值一般介于 0 到 1。这两种形状可以通过人脸框来做转换。
分类
人脸关键点检测方法大致分为三种,分别是基ASM(Active Shape Model)[1]和AAM (Active Appearnce Model)[2,3]的传统方法;基于级联形状回归的方法[4];基于深度学习的方法[5-10]。若是按照参数化与否来分,可分为参数化方法和非参数化方法,ASM、AAM和CLM[11]就属于参数化方法,而级联回归和深度学习方法属于非参数化方法。基于参数化形状模型的方法可依据其外观模型的不同,可进一步分为,基于局部的方法[12-14]和基于全局的方法[15-17];对于非参数化进一步可分为基于样例的方法[18,19]、基于图模型的方法[20,21]、基于级联回归的方法[4,22,23]和基于深度学习的方法[24-26]。更为详细的划分请参考文献[27]。目前,应用最广泛,效果精度最高的是基于深度学习的方法,因此本文主要针对深度学习在人脸关键点检测上的应用进行研究。
(后来参照Facial feature point detection A comprehensive survey,人脸关键点检测方法分为两种:参数化和非参数化,这种划分方法感觉更好一些,可以很好理解“参数”的含义)

参数模型是指数据服从某种特定概率分布,例如,高斯模型,高斯混合模型等。基于非参数模型方法是无分布的,其假设数据不是从给定的概率分布得出的。参数模型与非参数模型的区别在于前者具有固定的参数,而后者随着训练数据量的增加而增加参数的数量。基于参数模型可划分为基于局部模型(如,主动形状模型)和基于全局模型(如,主动外观模型);基于非参数模型可进一步划分为基于图模型方法、基于级联回归方法和基于深度学习方法。
基于局部模型方法独立考虑每个关键点周围的变化,然后通过从训练中学习到的全局形状来检测人脸关键点;基于全局模型方法是从整体对外观进行建模。基于图模型的方法通常设计树形结构或马尔科夫随机场来对关键点进行建模;基于级联回归的方法以从粗到细的方式直接估计关键点,并不需要对任何形状模型或外观模型进行学习和建模;基于深度学习的方法是利用神经网络非线性映射能力学习面部图像到关键点的映射。
人脸关键点定位方法中具有里程碑式的有如下五种方法:
1) 1995年,Cootes的ASM(Active Shape Model)。
2) 1998年,Cootes 的AAM(Active Appearance Model)算法。
3) 2006年,Ristinacce 的CLM(Constrained Local Model)算法。
4) 2010年,Rollar 的cascaded Regression算法。
5) 2013年,Sun开创深度学习人脸关键点检测的先河,首次将CNN应用到人脸关键点定位上。
定量评价
目前主要的衡量标准是算法所获取的关键点位置与真实关键点位置之间的偏差。在评价偏差时,由于不同人脸图像的实际大小难免会有所差异,为便于在同样的尺度下比较算法性能,需要采用一定的数据归一化策略. 目前主流的方法是基于两眼间的距离进行人脸大小的标准化,即:

其中分子 表示估计值与真实值的欧式距离,分母 表示双眼距离,即两眼中心的欧式距离。也有采用边界框对角线作为归一化因子来评价偏差,如文献[20]。
常用数据库
数据库可以分为两类:主动式捕获的数据和被动式捕获的数据。主动式捕获的数据是在实验室里,对光照变化、遮挡、头部姿态和面部表情可控的情况下,对固定人员进行照片采集。被动式捕获的数据则是在社交网站等一些环境不可控的条件下采集而得。
主动式数据
CMU Multi-PIE[20]人脸数据库是在2004年10月至2005年3月的四次会议中收集的,支持在姿态、光照和表情变化条件下识别人脸的算法的开发。 该数据库包含337个主题和超过750,000个305GB数据的图像。 共记录了六种不同的表情:中性,微笑,惊奇,斜视,厌恶和尖叫。 在15个视图和19个不同照明条件下记录受试者,这个数据库的一个子集被标记为68点或39点。
XM2VTS数据库[21]收集了295人的2360个彩色图像,声音文件和3D人脸模型,这2360个彩色图像标有68个关键点。
AR数据库[22]包含超过4000个彩色图像,对应126人(70名男性和56名女性)的脸部。图像是在可控的条件下,以不同的面部表情,光照条件和遮挡(太阳镜和围巾)拍摄的。Ding and Martinez手动为每张脸部图像标注了130个关键点。
IMM数据库[23]包含240张40个人的彩色图像(7名女性和33名男性)。 每张图像都对眉毛、眼睛、鼻子、嘴巴和下巴进行标注,共计58个标记点。
MUCT数据库[24]由276个人的3755张图像组成,每张图像有76个关键点。 这个数据库中的面孔在不同的光照、不同的年龄和不同的种族的条件下拍摄。
PUT数据库[25]采集了部分光照条件可控的100个人,且沿着俯仰角和偏航角旋转的9971张高分辨率图像(2048×1536),每张图像都标有30个关键点。
被动式数据
BioID数据库[26]记录在室内实验室环境中,但使用“真实世界”的条件。 该数据库包含23个主题的1521个灰度人脸图像,每张图像标记20个关键点。
LFW数据库[27]包含从网上收集的5724个人的13,233幅面部图像,其中1680人在数据集中有两张或更多的照片。虽然,这个数据库没有提供标记点,但可以从其余网站上获取。
AFLW(Annotated Facial Landmarks in the Wild) 数据库[28]是一个大规模、多视角和真实环境下的人脸数据库。图像是从图片分享网站Flickr上收集,该数据库共包含25,993张图像,每张图像标有21个关键点。
LFPW(Labeled Face Parts in the Wild) 数据库[29]由1400个面部图像(1100作为训练集,其他300个图像作为测试集)组成。所有数据均从google, Flickr和Yahoo上获取,每张图像标记35个关键点,但在文献中,通常采用29个关键点。
AFW(Annotated Faces in the Wild)数据库[30]包含205个图像,特点是:背景高度混乱,人脸比例和姿势都有很大的变化,每张图像均有6个关键点和边界框。
300-W(300 Faces in-the-Wild Challenge) [31]是一个混合数据库,由多个已发布数据库(LFPW,Helen,AFW和XM2VTS)的面部图像和一个新收集的数据库IBUG组成。 所有这些图像都重新标注了68个关键点。
二、 检测方法
2.1 ASM (Active Shape Models)
2.2 AAM(Active Appearance Models)
2.3 CPR(Cascaded pose regression)
2.4 DCNN
2.5 Face++版DCNN
2.6 TCDCN
2.7 MTCNN
2.8 TCNN(Tweaked Convolutional Neural Networks)
2.9 DAN(Deep Alignment Networks)
为了更好的理解人脸关键点的发展和历史,本文也简单介绍了最为经典的人脸关键点检测方法:ASM和AAM
2.1 ASM (Active Shape Models)
ASM(Active Shape Model)[1] 是由Cootes于1995年提出的经典的人脸关键点检测算法,主动形状模型即通过形状模型对目标物体进行抽象,ASM是一种基于点分布模型(Point Distribution Model, PDM)的算法。在PDM中,外形相似的物体,例如人脸、人手、心脏、肺部等的几何形状可以通过若干关键点(landmarks)的坐标依次串联形成一个形状向量来表示。ASM算法需要通过人工标定的方法先标定训练集,经过训练获得形状模型,再通过关键点的匹配实现特定物体的匹配。
ASM主要分为两步:第一步:训练。首先,构建形状模型:搜集n个训练样本(n=400);手动标记脸部关键点;将训练集中关键点的坐标串成特征向量;对形状进行归一化和对齐(对齐采用Procrustes方法);对对齐后的形状特征做PCA处理。接着,为每个关键点构建局部特征。目的是在每次迭代搜索过程中每个关键点可以寻找新的位置。局部特征一般用梯度特征,以防光照变化。有的方法沿着边缘的法线方向提取,有的方法在关键点附近的矩形区域提取。第二步:搜索。首先:计算眼睛(或者眼睛和嘴巴)的位置,做简单的尺度和旋转变化,对齐人脸;接着,在对齐后的各个点附近搜索,匹配每个局部关键点(常采用马氏距离),得到初步形状;再用平均人脸(形状模型)修正匹配结果;迭代直到收敛。
ASM 算法的优点在于模型简单直接,架构清晰明确,易于理解和应用,而且对轮廓形状有着较强的约束,但是其近似于穷举搜索的关键点定位方式在一定程度上限制了其运算效率。
2.2 AAM(Active Appearance Models)
1998年,Cootes对ASM进行改进,不仅采用形状约束,而且又加入整个脸部区域的纹理特征,提出了AAM算法[2]。AAM于ASM一样,主要分为两个阶段,模型建立阶段和模型匹配阶段。其中模型建立阶段包括对训练样本分别建立形状模型(Shape Model)和纹理模型(Texture Model),然后将两个模型进行结合,形成AAM模型。
2.3 CPR(Cascaded pose regression)
2010年,Dollar提出CPR(Cascaded Pose Regression, 级联姿势回归)[4],CPR通过一系列回归器将一个指定的初始预测值逐步细化,每一个回归器都依靠前一个回归器的输出来执行简单的图像操作,整个系统可自动的从训练样本中学习。
人脸关键点检测的目的是估计向量 ,其中K表示关键点的个数,由于每个关键点有横纵两个坐标,所以S得长度为2K。CPR检测流程如图所示,一共有T个阶段,在每个阶段中首先进行特征提取,得到 ,这里使用的是shape-indexed features,也可以使用诸如HOG、SIFT等人工设计的特征,或者其他可学习特征(learning based features),然后通过训练得到的回归器R来估计增量ΔS( update vector),把ΔS加到前一个阶段的S上得到新的S,这样通过不断的迭代即可以得到最终的S(shape)。
2.4 DCNN
2013年,Sun等人[5]首次将CNN应用到人脸关键点检测,提出一种级联的CNN(拥有三个层级)——DCNN(Deep Convolutional Network),此种方法属于级联回归方法。作者通过精心设计拥有三个层级的级联卷积神经网络,不仅改善初始不当导致陷入局部最优的问题,而且借助于CNN强大的特征提取能力,获得更为精准的关键点检测。
如图所示,DCNN由三个Level构成。Level-1 由3个CNN组成;Level-2由10个CNN组成(每个关键点采用两个CNN);Level-3同样由10个CNN组成。
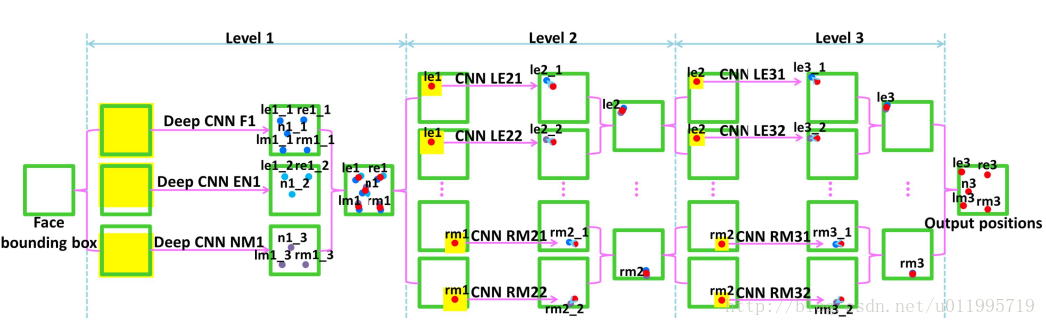
Level-1分3个CNN,分别是F1(Face 1)、EN1(Eye,Nose)、NM1(Nose,Mouth);F1输入尺寸为39*39,输出5个关键点的坐标;EN1输入尺寸为39*31,输出是3个关键点的坐标;NM11输入尺寸为39*31,输出是3个关键点。Level-1的输出是由三个CNN输出取平均得到。
Level-2,由10个CNN构成,输入尺寸均为15*15,每两个组成一对,一对CNN对一个关键点进行预测,预测结果同样是采取平均。
Level-3与Level-2一样,由10个CNN构成,输入尺寸均为15*15,每两个组成一对。Level-2和Level-3是对Level-1得到的粗定位进行微调,得到精细的关键点定位。
Level-1之所以比Level-2和Level-3的输入要大,是因为作者认为,由于人脸检测器的原因,边界框的相对位置可能会在大范围内变化,再加上面部姿态的变化,最终导致输入图像的多样性,因此在Level-1应该需要有足够大的输入尺寸。Level-1与Level-2和Level-3还有一点不同之处在于,Level-1采用的是局部权值共享(Locally Sharing Weights),作者认为传统的全局权值共享是考虑到,某一特征可能在图像中任何位置出现,所以采用全局权值共享。然而,对于类似人脸这样具有固定空间结构的图像而言,全局权值共享就不奏效了。因为眼睛就是在上面,鼻子就是在中间,嘴巴就是在下面的。所以作者借鉴文献[28]中的思想,采用局部权值共享,作者通过实验证明了局部权值共享给网络带来性能提升。
DCNN采用级联回归的思想,从粗到精的逐步得到精确的关键点位置,不仅设计了三级级联的卷积神经网络,还引入局部权值共享机制,从而提升网络的定位性能。最终在数据集BioID和LFPW上均获得当时最优结果。速度方面,采用3.3GHz的CPU,每0.12秒检测一张图片的5个关键点。
2.5 Face++版DCNN
2013年,Face++在DCNN模型上进行改进,提出从粗到精的人脸关键点检测算法[6],实现了68个人脸关键点的高精度定位。该算法将人脸关键点分为内部关键点和轮廓关键点,内部关键点包含眉毛、眼睛、鼻子、嘴巴共计51个关键点,轮廓关键点包含17个关键点。
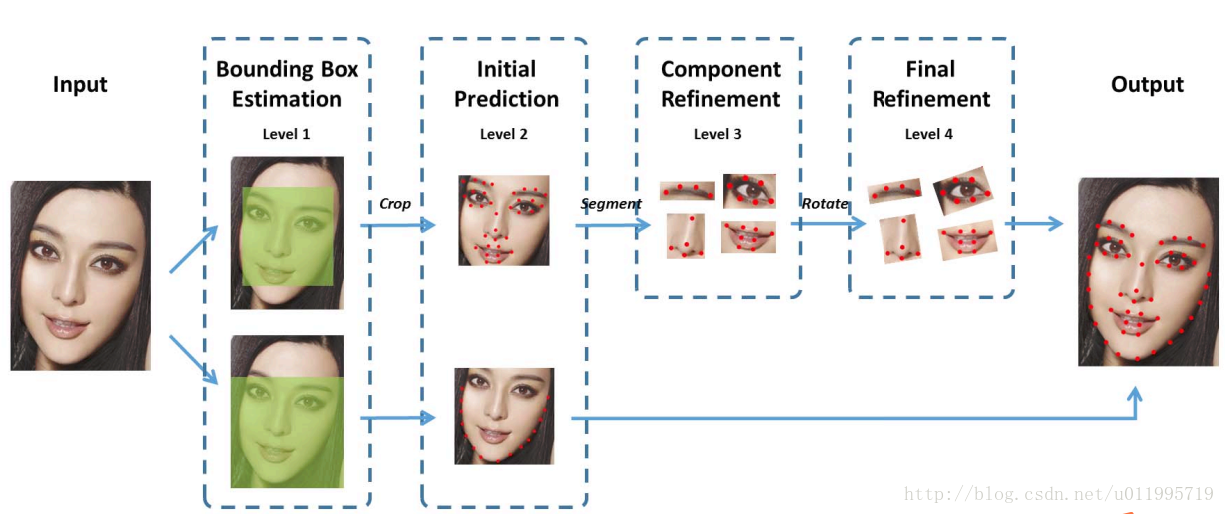
针对内部关键点和外部关键点,该算法并行的采用两个级联的CNN进行关键点检测,网络结构如图所示。
针对内部51个关键点,采用四个层级的级联网络进行检测。其中,Level-1主要作用是获得面部器官的边界框;Level-2的输出是51个关键点预测位置,这里起到一个粗定位作用,目的是为了给Level-3进行初始化;Level-3会依据不同器官进行从粗到精的定位;Level-4的输入是将Level-3的输出进行一定的旋转,最终将51个关键点的位置进行输出。针对外部17个关键点,仅采用两个层级的级联网络进行检测。Level-1与内部关键点检测的作用一样,主要是获得轮廓的bounding box;Level-2直接预测17个关键点,没有从粗到精定位的过程,因为轮廓关键点的区域较大,若加上Level-3和Level-4,会比较耗时间 。最终面部68个关键点由两个级联CNN的输出进行叠加得到。
算法主要创新点由以下三点:(1)把人脸的关键点定位问题,划分为内部关键点和轮廓关键点分开预测,有效的避免了loss不均衡问题;(2)在内部关键点检测部分,并未像DCNN那样每个关键点采用两个CNN进行预测,而是每个器官采用一个CNN进行预测,从而减少计算量;(3)相比于DCNN,没有直接采用人脸检测器返回的结果作为输入,而是增加一个边界框检测层(Level-1),可以大大提高关键点粗定位网络的精度。
Face++版DCNN首次利用卷积神经网络进行68个人脸关键点检测,针对以往人脸关键点检测受人脸检测器影响的问题,作者设计Level-1卷积神经网络进一步提取人脸边界框,为人脸关键点检测获得更为准确的人脸位置信息,最终在当年300-W挑战赛上获得领先成绩。
2.6 TCDCN
网络输出为40*40的灰度图,经过CNN最终得到2*2*64的特征图,再通过一层含100个神经元的全连接层输出最终提取得到的共享特征。该特征为所有任务共同享用,对于关键点检测问题,就采用线性回归模型;对于分类问题,就采用逻辑回归。
在传统MLT中,各任务重要程度是一致的,其目标方程如下:
其中,f(xti;wt)f(xit;wt) 表示 xtixit与权值矩阵 wtwt相乘之后输入到函数 f(⋅)f(⋅), l(⋅)l(⋅)表示损失函数,Φ(wt)Φ(wt) 是正则项。可以看到对于各任务t而言,其重要性是相同的,但是在多任务学习中,往往不同任务的学习难易程度不同,若采用相同的损失权重,会导致学习任务难以收敛。文章针对多任务学习中,不同学习难度问题进行了优化,提出带权值的目标函数:
其中,第一项表示主任务的损失函数,即人脸关键点检测的损失函数,第二项表示其余各子任务的损失函数,其中λaλa 表示任务a的重要性。针对人脸关键点检测任务,本文结合了四个子任务,分别是:性别、是否带眼镜、是否微笑和脸部的姿势,目标函数为:
其中,第一项是平方和误差,表示人脸关键点损失函数,第二项是分类任务,采用的是交叉熵误差,第三项即正则项。
针对多任务学习的另外一个问题——各任务收敛速度不同,本文提出一种新的提前停止(Early Stopping)方法。当某个子任务达到最好表现以后,这个子任务就对主任务已经没有帮助,就可以停止这个任务。文章给出自动停止子任务的计算公式,如下:
其中,EatrEtra 表示训练的误差,EavalEvala 表示验证的误差, εε为阈值,第一项表示训练误差的趋势,第二项表示泛化误差与训练误差之比,当两项之积大于阈值 ,则该任务停止。
TCDCN采用多任务学习方法对人脸关键点进行检测,针对多任务学习在人脸关键点检测任务中的两个主要问题——不同任务学习难易程度不同以及不同任务收敛速度不同,分别提出了新目标函数和提前停止策略加以改进,最终在AFLW和AFW数据集上获得领先的结果。同时对比于级联CNN方法,在Intel Core i5 cpu上,级联CNN需要0.12s,而TCDCN仅需要17ms,速度提升七倍有余。
代码链接: https://github.com/zhzhanp/TCDCN-face-alignment
2.7 MTCNN
2016年,Zhang等人提出一种多任务级联卷积神经网络(MTCNN, Multi-task Cascaded Convolutional Networks)[9]用以同时处理人脸检测和人脸关键点定位问题。作者认为人脸检测和人脸关键点检测两个任务之间往往存在着潜在的联系,然而大多数方法都未将两个任务有效的结合起来,本文为了充分利用两任务之间潜在的联系,提出一种多任务级联的人脸检测框架,将人脸检测和人脸关键点检测同时进行。
MTCNN包含三个级联的多任务卷积神经网络,分别是Proposal Network (P-Net)、Refine Network (R-Net)、Output Network (O-Net),每个多任务卷积神经网络均有三个学习任务,分别是人脸分类、边框回归和关键点定位。网络结构如图所示:
TCNN实现人脸检测和关键点定位分为三个阶段。首先由P-Net获得了人脸区域的候选窗口和边界框的回归向量,并用该边界框做回归,对候选窗口进行校准,然后通过非极大值抑制(NMS)来合并高度重叠的候选框。然后将P-Net得出的候选框作为输入,输入到R-Net,R-Net同样通过边界框回归和NMS来去掉那些false-positive区域,得到更为准确的候选框;最后,利用O-Net输出5个关键点的位置。
在具体训练过程中,作者就多任务学习的损失函数计算方式进行相应改进。在多任务学习中,当不同类型的训练图像输入到网络时,有些任务时是不进行学习的,因此相应的损失应为0。例如,当训练图像为背景(Non-face)时,边界框和关键点的loss应为0,文中提供计算公式自动确定loss的选取,公式为:
其中, αjαj表示任务的重要程度,在P-Net和R-Net中,αdet=1αdet=1,αbox=0.5,αlandmark=0.5αbox=0.5,αlandmark=0.5 ,在O-Net中,由于要对关键点进行检测,所以相应的增大任务的重要性,αdet=1αdet=1,αbox=0.5αbox=0.5 , αlandmark=1αlandmark=1 。 作为样本类型指示器。
为了提升网络性能,需要挑选出困难样本(Hard Sample),传统方法是通过研究训练好的模型进行挑选,而本文提出一种能在训练过程中进行挑选困难的在线挑选方法。方法为,在mini-batch中,对每个样本的损失进行排序,挑选前70%较大的损失对应的样本作为困难样本,同时在反向传播时,忽略那30%的样本,因为那30%样本对更新作用不大。
实验结果表明,MTCNN在人脸检测数据集FDDB 和WIDER FACE以及人脸关键点定位数据集LFPW均获得当时最佳成绩。在运行时间方面,采用2.60GHz的CPU可以达到16fps,采用Nvidia Titan Black可达99fps。
代码实现:
Matlab:https://github.com/kpzhang93/MTCNN_face_detection_alignment
Caffe:https://github.com/dlunion/mtcnn
Python:https://github.com/DuinoDu/mtcnn
2.8 TCNN(Tweaked Convolutional Neural Networks)
2016年,Wu等人研究了CNN在人脸关键点定位任务中到底学习到的是什么样的特征,在采用GMM(Gaussian Mixture Model, 混合高斯模型)对不同层的特征进行聚类分析,发现网络进行的是层次的,由粗到精的特征定位,越深层提取到的特征越能反应出人脸关键点的位置。针对这一发现,提出了TCNN(Tweaked Convolutional Neural Networks)[8],其网络结构如图所示:
上图为Vanilla CNN,针对FC5得到的特征进行K个类别聚类,将训练图像按照所分类别进行划分,用以训练所对应的FC6K 。测试时,图片首先经过Vanilla CNN提取特征,即FC5的输出。将FC5输出的特征与K个聚类中心进行比较,将FC5输出的特征划分至相应的类别中,然后选择与之相应的FC6进行连接,最终得到输出。
作者通过对Vanilla CNN中间层特征聚类分析得出的结论是什么呢?又是如何通过中间层聚类分析得出灵感从而设计TCNN呢?
作者对Vanilla CNN中间各层特征进行聚类分析,并统计出关键点在各层之间的变化程度,如图所示:
从图中可知,越深层提取到的特征越紧密,因此越深层提取到的特征越能反应出人脸关键点的位置。作者在采用K=64时,对所划分簇的样本进行平均后绘图如下:
从图上可发现,每一个簇的样本反应了头部的某种姿态,甚至出现了表情和性别的差异。因此可推知,人脸关键点的位置常常和人脸的属性相关联。因此为了得到更准确的关键点定位,作者使用具有相似特征的图片训练对应的回归器,最终在人脸关键点检测数据集AFLW,AFW和300W上均获得当时最佳效果。
2.9 DAN(Deep Alignment Networks)
2017年,Kowalski等人提出一种新的级联深度神经网络——DAN(Deep Alignment Network)[10],以往级联神经网络输入的是图像的某一部分,与以往不同,DAN各阶段网络的输入均为整张图片。当网络均采用整张图片作为输入时,DAN可以有效的克服头部姿态以及初始化带来的问题,从而得到更好的检测效果。之所以DAN能将整张图片作为输入,是因为其加入了关键点热图(Landmark Heatmaps),关键点热图的使用是本文的主要创新点。DAN基本框架如图所示:
DAN包含多个阶段,每一个阶段含三个输入和一个输出,输入分别是被矫正过的图片、关键点热图和由全连接层生成的特征图,输出是面部形状(Face Shape)。其中,CONNECTION LAYER的作用是将本阶段得输出进行一系列变换,生成下一阶段所需要的三个输入,具体操作如下图所示:
从第一阶段开始讲起,第一阶段的输入仅有原始图片和S0。面部关键点的初始化即为S0,S0是由所有关键点取平均得到,第一阶段输出S1。对于第二阶段,首先,S1经第一阶段的CONNECTION LAYERS进行转换,分别得到转换后图片T2(I)、S1所对应的热图H2和第一阶段fc1层输出,这三个正是第二阶段的输入。如此周而复始,直到最后一个阶段输出SN。文中给出在数据集IBUG上,经过第一阶段后的T2(I)、T2(S1)和特征图,如图所示:
从图中发现,DAN要做的“变换”,就是把图片给矫正了,第一行数据尤为明显,那么DAN对姿态变换具有很好的适应能力,或许就得益于这个“变换”。至于DAN采用何种“变换”,需要到代码中具体探究。
接下来看一看,St是如何由St-1以及该阶段CNN得到,先看St计算公式:
其中 ΔStΔSt是由CNN输出的,各阶段CNN网络结构如图所示:
该CNN的输入均是经过了“变换”——Tt(⋅)Tt(⋅) 的操作,因此得到的偏移量ΔStΔSt 是在新特征空间下的偏移量,在经过偏移之后应经过一个反变换 T−1t(⋅)Tt−1(⋅)还原到原始空间。而这里提到的新特征空间,或许是将图像进行了“矫正”,使得网络更好的处理图像。
关键点热度图的计算就是一个中心衰减,关键点处值最大,越远则值越小,公式如下:
为什么需要从fc1层生成一张特征图?文中提到“Such a connection allows any information learned by the preceding stage to be transferred to the consecutive stage.”其实就是人为给CNN增加上一阶段信息。
总而言之,DAN是一个级联思想的关键点检测方法,通过引入关键点热图作为补充,DAN可以从整张图片进行提取特征,从而获得更为精确的定位。
代码实现:
Theano:https://github.com/MarekKowalski/DeepAlignmentNetwork
总结
自2013年Sun等人在人脸关键点检测任务中使用深度学习获得良好效果以来,众多学者将目光从传统方法转移到基于深度学习方法,并在近年提出多种有效的深度学习模型,均取得人脸关键点检测任务的突破,如DCNN到Face++版DCNN,TCDCN到MTCNN等。本文对近年取得突破性进展的深度学习模型进行分析,在此统计其优缺点如表所示:
胡思乱想:
1. Coarse-to-Fine
从ASM、AAM到CPR(级联回归),都讲究 Coarse-to-Fine——从粗到精的这么一个过程,到了现在的深度学习方法,同样讲究从粗到精;因此可以知道从粗到精是目前不可抛弃的,所以可以考虑如何设计从粗到精;
2. 人脸检测器得影响
之前有提到,倘若采用不同的人脸检测器进行人脸检测,再输入到关键点检测模型,效果会不好,可以这么理解,换了一个人脸检测器,也就相当于换了一个样本生成器,倘若样本生成器差异很大,生成的样本与训练时的样本差异比较大,那么神经网络就GG了~~
从这里可以看出:人脸检测器对关键点检测很重要!为了避免不同人脸检测器带来的影响,可以考虑在关键点检测模型里边做一个“人脸检测器”,不管从哪里来的图片,都经过同一个“人脸检测器”再输入到后面的关键点检测去,这样效果就会好了。
例如 Face++版DCNN,先进行了一个bounding box estimation;
例如MTCNN,先用了两个模型对人脸进行检测! 先由P-Net 和R-Net来获得人脸候选框,然后再进行关键点定位。
再如DAN,对人脸进行了“矫正”,再检测;
如果想“搞”些新idea,可以从以上两点出发,
1.级联的CNN从粗到精;
2.一定要有“自己的人脸检测器”
当然,多任务也可以借鉴。
此博客只是抛砖引玉,希望大家提出问题和建议~~
欢迎转载,请注明出处:
http://blog.csdn.net/u011995719/article/details/78890333

 浙公网安备 33010602011771号
浙公网安备 33010602011771号