

python爬虫:将本人博客园文章转化为MarkDown格式
本周又和大家见面了,首先说一下两周之后要进行研究生的期末考试,所以这次可能是考试之前的最后一更,我要忙着复习了,还请大家见谅,一般情况下我都是每周更新一篇技术原创。
好了,废话不多说,咱们进入今天的主题。由于我在简书也有自己的基地,所以每次在博客园文章更新完,还要在简书进行更新。由于简书文章的编辑格式是MarkDown,所以前几次更新修改格式都是非常麻烦,浪费时间,尤其是有了图片之后。于是,为了不让自己的时间浪费在这么无聊的事情上,我就用学到的爬虫知识,对我写的文章进行格式的转化(当然我只是按照我文章的格式进行解析的,不具有通用性,之后可以完善通用性)。

咱们就按照我写的上面文章Scrapy爬取美女图片第四集 突破反爬虫(上)为例,进行格式的转化。
来到这个界面:

你会发现文章中主要包含这几种特殊对象: 段落文本(有颜色和无颜色之分),图片(主要是提取图片链接),代码框中的代码。所以咱们需要对这几种对象进行分别提取和转化。
老规矩,打开firebug,输入链接,这次不仅需要观察HTML结构,还要观察网络这个选项,捕获这个get请求,会发现很大的不同。
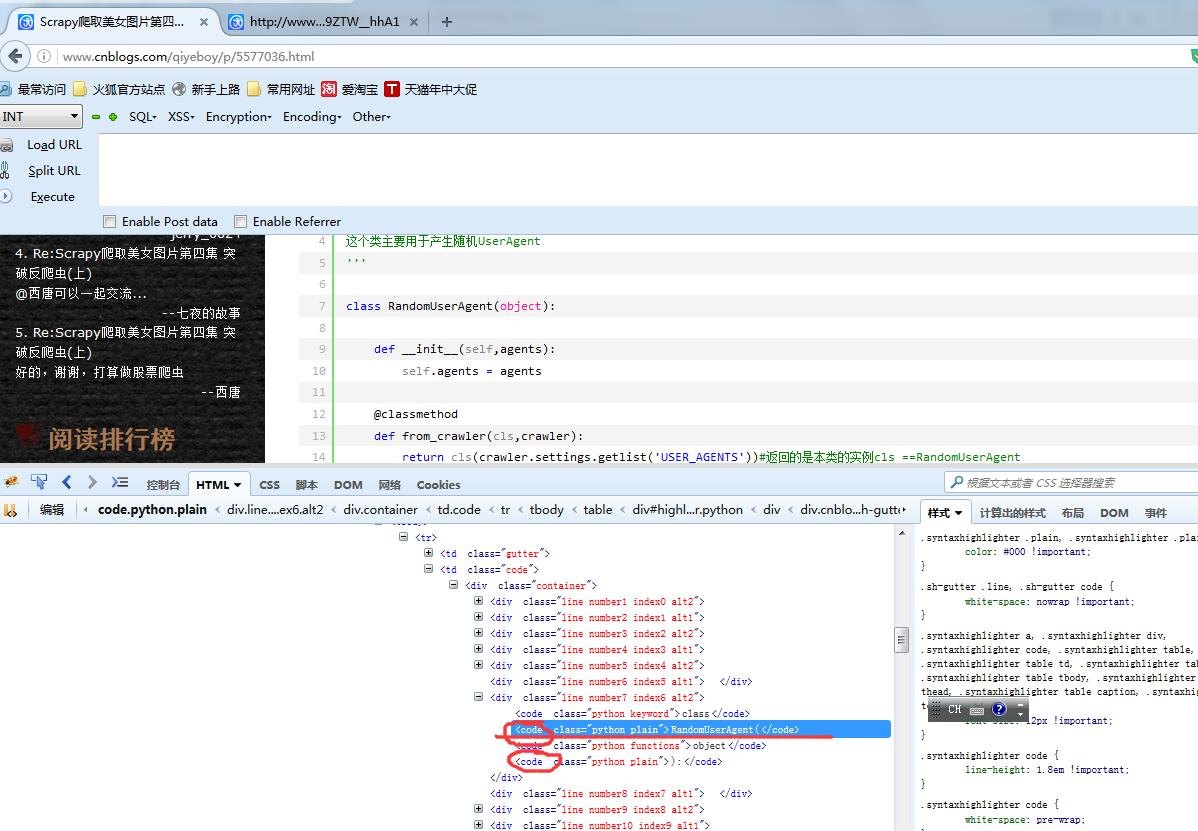
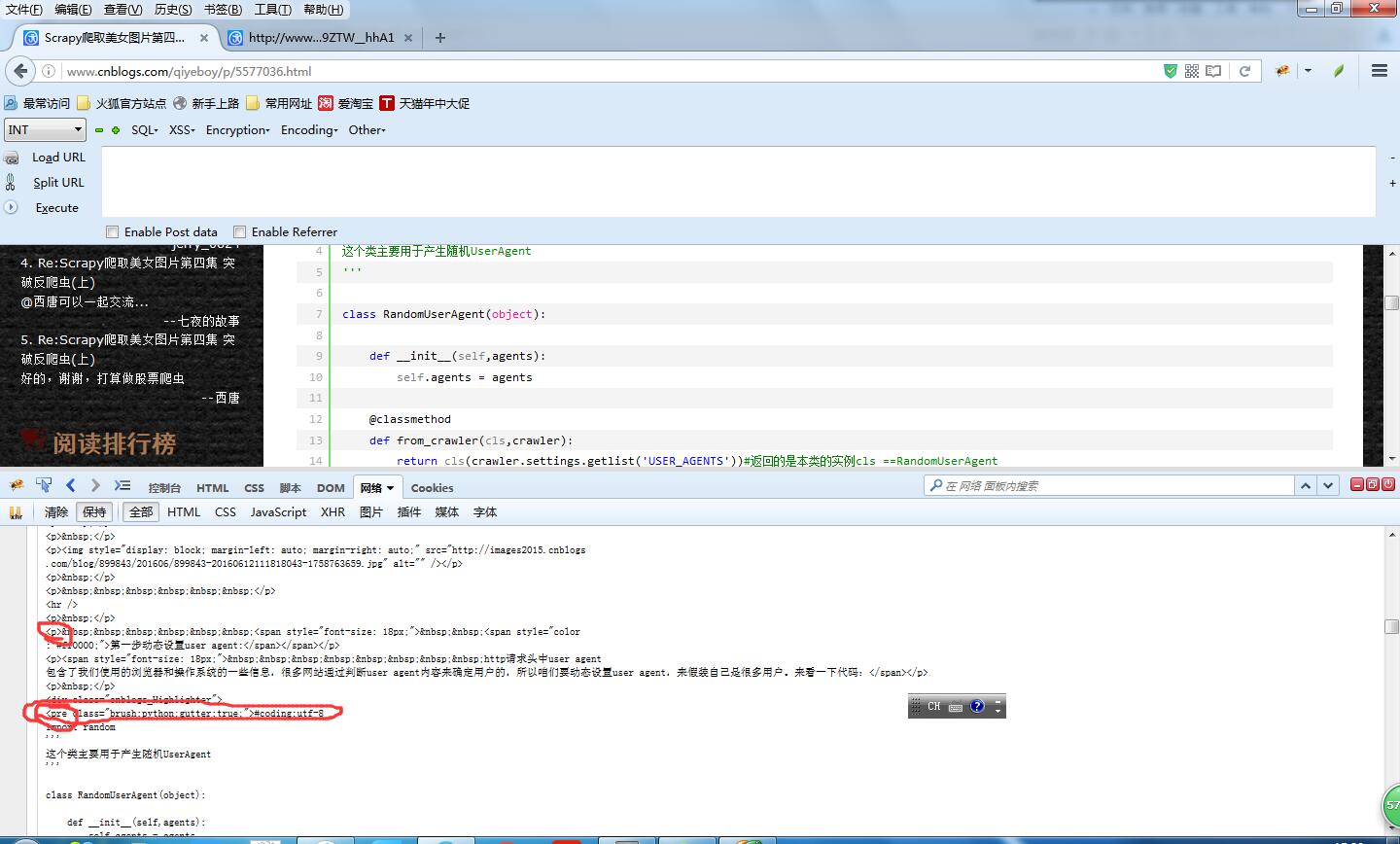
同样是表现的代码内容,发现网络请求返回的标签和最后生成的标签是不一样的。这就是通过javascript动态修改html。那咱们该以什么为准呢?当然是以网络请求的格式为准,因为在实际的网络访问中就是获取的这个内容。
通过上面的可以看到代码都是由pre标签进行包裹,其他内容都是由p标签进行包裹。所以为了统一格式,先将获取到的pre标签换成p标签,并添加code属性进行区分。当然用到的还是bs4这个神器。直接看一下代码:
1 2 3 4 5 | soup = BeautifulSoup(response)#,'html.parser',from_encoding='utf-8'pres = soup.findAll('pre')for pre in pres: pre.name ='p' pre['code']='yes' |
首先提取其中图片的链接,并按照标签的顺序添加到list中存储:
1 2 3 4 5 6 | ps = soup.findAll('p')for p in ps: img = p.img if img !=None: self.content={'tag':'img','content':img['src']} self.papers.append(self.content) |
接着提取code的代码内容,并按照标签的顺序添加到list中存储:
1 2 3 | if p.get('code')=='yes': self.content={'tag':'code','content':p.text.replace(' :','').strip()} self.papers.append(self.content) |
然后将正常段落中的颜色部分进行标注,我习惯是将加颜色的文字,最后转化为加粗形式。从格式中看到,加颜色的字体使用span标签进行包裹的。
咱们将标签进行替换和标注,以便后续处理。
1 2 3 4 5 6 7 8 9 | elif p.span != None: spans = p.findAll('span')#找到所有的span标签 for span in spans: # print span.text if span.get('style').find('color')!=-1: # del span['style'] # span.name='color' if span.string!=None: span.string = 'c_start'+span.string+'c_end' #对有颜色的文本进行标注 |
有时候会发现,文本中有链接,咱们还要把链接进行按次序提取。
1 2 3 4 5 | links =p.findAll('a') for link in links: if link.string!=None: link.string = '['+link.string+']'+'('+link.string+')' self.content={'tag':'text','content':p.text.replace(' :','').strip()} self.papers.append(self.content) |
经过这几个步骤就将所有要提取的内容都分离出来了,接下来进行转化为markdown格式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #coding:utf-8class Convert(object): @classmethod def convert(self,papers): str = '' with open('D:\markdown.txt','w') as file_writer: for p in papers: if p['tag']=='text': str = p['content'].replace('c_start','**').replace('c_end','**') #这个是替换颜色,使用加粗 pass elif p['tag']=='code': str = '```'+'\r\n'+p['content']+'\r\n'+'```' #这个是代码框的添加 else: ##这个是图片链接的转化 str = ''%(p['content']) str = '\r\n'+str+'\r\n' file_writer.write(str.encode('utf-8')) file_writer.write('\r\n'.encode('utf-8')) file_writer.close() |
最后咱们看一下效果,将生成的markdown文本复制到简书上去,是否显示正确。这个就是最后简书文章链接:http://www.jianshu.com/p/9159111bcd87。效果还是不错的,可能需要一些微调,以前整理格式要花10几分钟,不超过两分钟就搞定

完整的代码我已经上传到github上:
https://github.com/qiyeboy/html2Md
今天的分享就到这里,如果大家觉得还可以呀,记得推荐呦。

欢迎大家支持我公众号:

本文章属于原创作品,欢迎大家转载分享。尊重原创,转载请注明来自:七夜的故事 http://www.cnblogs.com/qiyeboy/


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?