
Scrapy爬取美女图片第三集 代理ip(上) (原创)
首先说一声,让大家久等了。本来打算520那天进行更新的,可是一细想,也只有我这样的单身狗还在做科研,大家可能没心思看更新的文章,所以就拖到了今天。不过忙了521,522这一天半,我把数据库也添加进来了,修复了一些bug(现在肯定有人会说果然是单身狗)。(我的新书《Python爬虫开发与项目实战》出版了,大家可以看一下样章)
好了,废话不多说,咱们进入今天的主题。上两篇 Scrapy爬取美女图片 的文章,咱们讲解了scrapy的用法。可是就在最近,有热心的朋友对我说之前的程序无法爬取到图片,我猜应该是煎蛋网加入了反爬虫机制。所以今天讲解的就是突破反爬虫机制的上篇 代理ip。

现在很多的网站对反爬虫的一个做法(当然还有其他检测)是:检测一个ip的重复性操作,从而判断是爬虫还是人工。所以使用代理ip就可以突破这个封锁。作为一个学生党,没钱专门去买vpn和ip池,所以咱们使用的代理ip来自于网络上免费的,基本上够个人使用了。接下来咱们讲的是爬取免费ip,并且验证代理ip的可用性。
网上有很多代理ip的网站,这次我选择的是http://www.xicidaili.com/nn/,大家学完可以试试其他的网站,咱们努力做个大的代理ip池。

大家是否注意到高匿两个字,高匿的意思是:对方服务器不知道你使用了代理,更不知道你的真实IP,因此隐蔽性很高。

当真。
按照咱们之前的学习爬虫的做法,使用firebug审查元素,查看如何解析html。
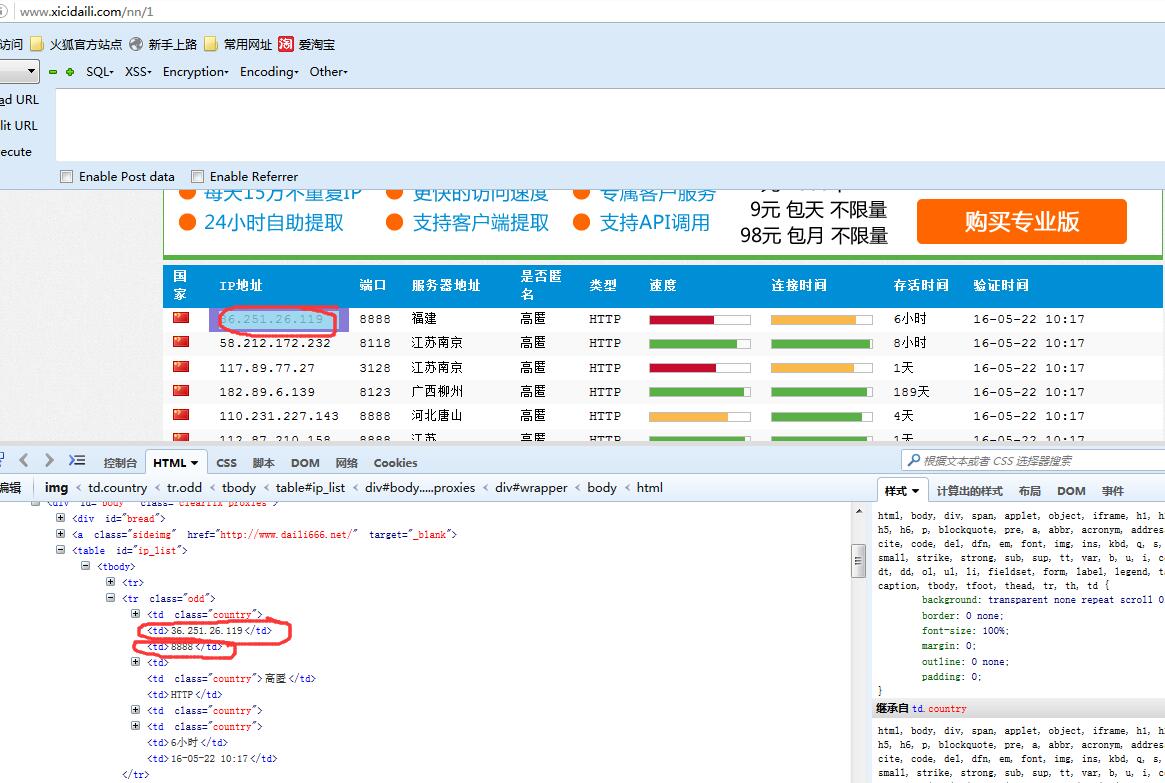
其实就是一个table,解析里面的每一行,这个很简单,咱们使用BeautifulSoup很容易就解析出来了。
同时大家还应该注意到,它每一页上的ip表的页数和url中的参数是对应的。例如第一页就是http://www.xicidaili.com/nn/1。这样就省去了咱们翻页的麻烦。

以下是程序的结构:

db包中db_helper:实现的是mongodb的增删改查。
detect包中 detect_proxy:验证代理ip的可用性
entity包中 proxy_info:对代理信息进行了对象化
spider包:
spiderman 实现爬虫的逻辑
html_downloader 实现爬虫的html下载器
html_parser 实现爬虫的html解析器
test包: 对样例的测试,不涉及程序运行
main.py:实现命令行参数定义
还要说一下检测:我是用 http://ip.chinaz.com/getip.aspx作为检测网址,只要使用代理访问不超时,而且响应码为200,咱们就认为是成功的代理。
接下来运行程序看看效果:
在windows下切换到工程目录,运行python main.py -h,会看到我定义的使用说明和参数设置。

接着运行python main.py -c 1 4 (意思是爬取1-4页的ip地址):

这时候如果想验证ip的正确性:运行python main.py -t db
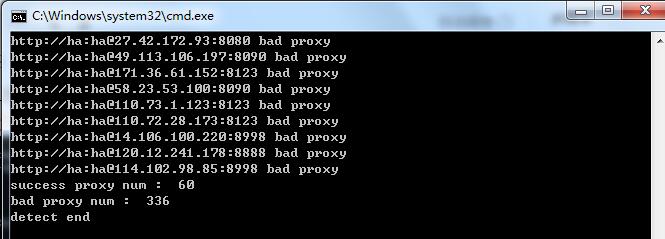
看来好用的ip还是比较少,不过对于个人算是够用了。
看一下mongodb数据库:
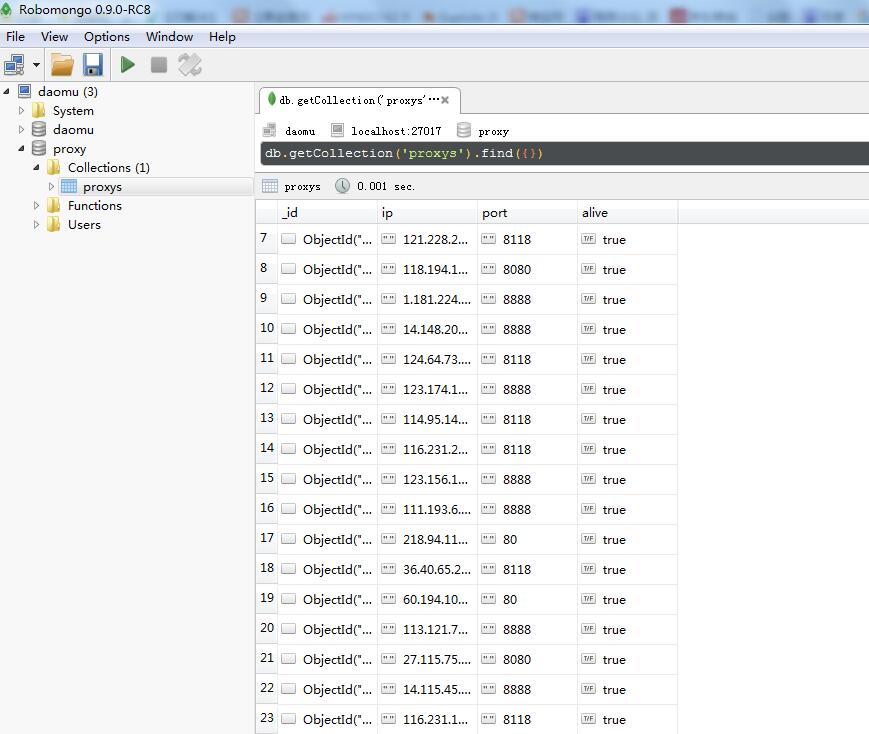
当咱们下次爬取图片的时候就可以使用这些ip了。

下面把解析和验证的代码贴一下:
def parser(self,html_cont):
'''
:param html_cont:
:return:
'''
if html_cont is None:
return
# 使用BeautifulSoup模块对html进行解析
soup = BeautifulSoup(html_cont,'html.parser',from_encoding='utf-8')
tr_nodes = soup.find_all('tr',class_ = True)
for tr_node in tr_nodes:
proxy = proxy_infor()
i = 0
for th in tr_node.children:
if th.string != None and len(th.string.strip()) > 0:
proxy.proxy[proxy.proxyName[i]] = th.string.strip()
print 'proxy',th.string.strip()
i += 1
if(i>1):
break
self.db_helper.insert({proxy.proxyName[0]:proxy.proxy[proxy.proxyName[0]],proxy.proxyName[1]:proxy.proxy[proxy.proxyName[1]]},proxy.proxy)
验证部分核心代码:
def detect(self):
'''
http://ip.chinaz.com/getip.aspx 作为检测目标
:return:
'''
proxys = self.db_helper.proxys.find()
badNum = 0
goodNum = 0
for proxy in proxys:
ip = proxy['ip']
port = proxy['port']
try:
proxy_host ="http://"+ip+':'+port #
response = urllib.urlopen(self.url,proxies={"http":proxy_host})
if response.getcode()!=200:
self.db_helper.delete({'ip':ip,'port':port})
badNum += 1
print proxy_host,'bad proxy'
else:
goodNum += 1
print proxy_host,'success proxy'
except Exception,e:
print proxy_host,'bad proxy'
self.db_helper.delete({'ip':ip,'port':port})
badNum += 1
continue
print 'success proxy num : ',goodNum
print 'bad proxy num : ',badNum
今天的分享就到这里,如果大家觉得还可以呀,记得支持我。代码上传到github上:https://github.com/qiyeboy/proxySpider_normal

欢迎大家支持我公众号:

本文章属于原创作品,欢迎大家转载分享。尊重原创,转载请注明来自:七夜的故事 http://www.cnblogs.com/qiyeboy/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号