芯片顶级盛会Hotchips2019年-未来芯片论坛及资料下载
提示:下载链接在文章最后。
HOTCHIPS是一个关于计算机体系结构和电子设计的会议,主要探讨芯片设计、存储器、能源效率、机器学习和人工智能等方面的发展。该会议每年都会召开一次,吸引着来自世界各地的专业人士和研究人员。
在HOTCHIPS 2019年会上,许多重要的芯片设计和技术被展示和讨论,包括Trent XT、EUV光刻机、Zen 2、96-Tensor TPU等。会议还讨论了未来芯片设计的趋势,例如7nm以下的制程技术、3D堆叠技术等。
此外,AMD在会议上介绍了其未来的芯片设计策略,即推出基于Zen 2微架构的第三代EPYC服务器处理器,并强调了7nm霄龙三代EPYC的性价比。同时,其他公司也在会议上展示了多款7nm产品,包括Nvidia的T4 GPU、高通的新款服务器芯片等。
HOTCHIPS(High-Performance Chips)是一个聚焦于微处理器和半导体技术的年度技术会议,通常涵盖以下一些主题:
新一代处理器架构和设计:会议通常会介绍最新的处理器架构、设计方法和优化技术。这可能包括针对性能、能效、多核心和多线程等方面的创新。
人工智能硬件:HOTCHIPS会议可能会涵盖人工智能领域的硬件加速器、神经网络处理器、深度学习芯片等技术。
高性能计算和超级计算机:针对高性能计算和超级计算机的硬件设计、体系结构和优化也是会议的热点。
存储技术和存储层次:新型存储技术、非易失性存储器(NVM)、快闪存储器等领域的发展也可能是HOTCHIPS的话题之一。
封装和互联技术:芯片封装、高速互联技术、片上系统(SoC)互联等方面的创新在会议上可能得到讨论。
物联网和边缘计算:物联网、边缘计算和嵌入式系统的硬件设计与优化也是会议的一部分。
安全性和隐私保护:在数字化时代,硬件安全性和隐私保护变得越来越重要,HOTCHIPS可能会涵盖这些方面的话题。
新兴技术和趋势:会议通常还会关注半导体技术领域的新兴趋势,如量子计算、光计算、生物计算等。
在这届Hot Chips大会上,AI 仍是主角,但 AI 芯片设计已经不是主角,从一个新颖的话题变为了成熟的工程。
会议要点摘要:
本次大会确实是有非常多非常扎实的工作,也展现了整个处理器与高性能芯片领域行业的趋势与变化。本系列文章将介绍我在 Hot Chips 大会上的几点观察与思考,涵盖以下几点内容:
• AI 仍是主角,但 AI 芯片设计已经不是主角,从一个新颖的话题变为了成熟的工程;
• 异构是大势所趋,无论赛灵思还是英伟达,都在持续前进;
• 安全是一个越来越重要的话题;
• FPGA 在各种不同应用中扮演着重要角色;
• 集成电路工艺演进:未来越来越难,但一定会有突破。
AI 芯片从火热到理性
Cerebras 是本次报告最大的亮点,也是被大家关注最多的 “AI 芯片” 的代表。然而,实际上本次大会,AI 芯片的设计本身,已经不是被大家关注的重点了。
此次 Hot Chips 大会的情况也充分说明,AI 芯片的技术噱头时代已经过去,越来越多的人在考虑,怎样去改变当前的范式,用更新的底层技术去实现更好的性能;是否能够真的做出可量产的芯片,之后怎样去和应用更好的融合,实现一个整体好用的系统。在单纯数字芯片模式下,单纯新的体系结构的创新,已经无法带来任何新的机会了 —— 我们必须进一步向前看。
No.3 异构计算:大势所趋
异构计算,Heterogeneous Computing, 不是一个新鲜的话题,然而真正出现大量使用的异构计算平台,却是从近几年的事情了。异构最重要的涵义,是系统由多种不同功能的部分组成,让每个部分做它最擅长的事情,而不是用统一的平台来做所有的事情。
异构计算的兴起,与 AI 芯片的兴起,本质上都有一个核心原因,摩尔定律的放缓甚至结束。
在过去几十年,芯片性能的增长,过半是由于制造工艺的进步带来的。在AMD CEO Lisa Su的报告中,也可以看到对于GPU,过去十年性能进步最重要的因素,也还是制造工艺的进步,占到了 40%。而随着摩尔定律的放缓,由制造工艺带来的进步越来越小,我们必须更多地依赖微架构和系统层面的进步来实现整体的进步。而这其中,最直接的方式,就是设计 Domain-specific architecture(DSA),放弃一部分通用性,来获得更大的性能提升。通常而言,越专用,通用性越差,越容易取得更好的性能。
也正因为此,我们看到了 GPU 在图像渲染上碾压 CPU,我们看到了在不同通用性层次支持深度学习的各类 DPU/NPU/NNP/MLU/DLA/VPU。比如,我们可以选择支持各类机器学习算法、而不仅仅是深度学习的 MLU,也可以选择只支持深度学习推理的 DPU,而如今又出现了不少专注在深度学习训练的专用芯片。
(Hot Chips 31 现场 nVidia 的报告)
在这次 Hot Chips 大会上介绍的 Turing GPU,虽然还挂着 GPU 的名字,其实也已经是一颗异构计算芯片,不仅仅是传统那些 SIMD 单元,总共由 Turing SM, RT Core,与 Tensor Core 三个部分组成。报告人 John Burgess 介绍,传统做光线追踪,对于每一条光线,要反复花费数千个时钟周期,才能正确计算和物体的交界点在哪里,而一次渲染会有非常多条光线要计算,因此他们才想要设计 RT Core 来专门解决光线追踪的问题。这就是典型的异构与 DSA 解决问题的方式:为一个计算复杂的任务设计专用加速器,用异构的系统来做整体的计算。
制造工艺之于 AI 芯片
黄老师有理有据地阐述了他的观点:摩尔定律很健康!然而俗话说 “屁股决定脑袋” ,他这样说,我们就无从知道,有多少比例的原因是他正在台积电担任集团研究副总裁。
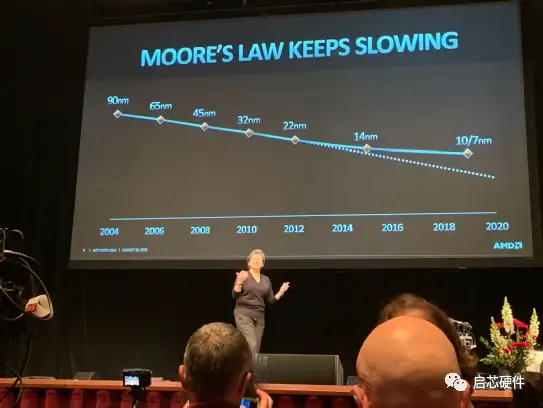
如在 AMD CEO Lisa Su 的报告中,就已经画出来了工艺演进的曲线,可以看到 10nm 与 7nm 工艺的发展速度已经很大程度上偏离了原来的 projection。虽然系统级封装,利用 Interposer 方式将 HBM 与计算部分集成到一起,大大提升了存储带宽,但是这并不是集成密度的提升。
而芯片制造工艺对于行业影响最大的,并不只是放缓,其制造成本也有非常大的影响:对于晶圆厂和 Fabless 设计公司均是这样。
对于晶圆厂来说,7nm 等先进工艺生产线动辄数十亿美金的投资是一笔巨大的负担。于是我们看到,在 2018 年 8 月,第二梯队的晶圆厂联电、Global Foundries 先后宣布放弃 7nm 工艺。在整个市场上,拥有最先进生产工艺的代工厂,只剩下了台积电、Intel 和三星。
对于 Fabless 的芯片设计公司,问题同样巨大。对于台积电 28nm、16nm、7nm 的芯片来说,要完成一颗芯片的量产,其 IP 购买、MPW、量产的成本在数百万美金,千万美金,亿美金以上 —— 如果考虑人员成本、设备成本等等的,这个数字还会高上不少。这就导致只有出货量极大、收入极高的几家大厂能够负担得起最先进工艺。比如大家耳熟能详的联发科,如今也只能先使用着台积电的 12nm,而不能像高通和海思一样使用 7nm 工艺。
先进制造工艺的成本问题,对于 AI 芯片创业公司也有很大影响。一般的 AI 芯片创业公司,可能只能负担得起 28nm 工艺,或者说最开始只敢用 28nm 工艺进行尝试。融资足够多的 AI 创业企业才能尝试得起 16nm 工艺的生产费用。在全球数十家 AI 芯片创业公司当中,我只听说过有一家敢于去使用 7nm。
如地平线在周五发布的征程二代芯片,就是使用的台积电 28nm 工艺(虽然 28nm HPC + 是多次改进的版本,不展开详细介绍),这也是大部分嵌入式 / 终端 AI 芯片目前选择的制造工艺;在 Hot Chips 上吸引了众多眼球的 Cerebras 与 Habana,均采用的 16nm 工艺 —— 而这也是迫不得已,因为他们的应用场景在云端,必须追求极限的高性能,所以必须使用能负担得起的最好的工艺,也必须选择 HBM 或者更加极端的存储方案(如 Cerebras 使用的 Wafer-scale engine,采用 18GB SRAM,单片成本据说在 100 万美金左右)。
--------------------------------------------------------------
全部会议资料下载链接分享:
链接:https://pan.baidu.com/s/1098dWOw3AT1v0_XJ0wvRWg?pwd=qxcc
提取码:qxcc
本文使用 文章同步助手 同步



 浙公网安备 33010602011771号
浙公网安备 33010602011771号