芯片顶级盛会Hotchips 2021年-未来芯片论坛及资料下载
提示:下载链接在文章最后。
HOTCHIPS是一个关于计算机体系结构和电子设计的会议,主要探讨芯片设计、存储器、能源效率、机器学习和人工智能等方面的发展。该会议每年都会召开一次,吸引着来自世界各地的专业人士和研究人员。

在HOTCHIPS 2021年会上,许多重要的芯片设计和技术被展示和讨论,包括Golden Cycle、Foveros、Lionx、AIaccelerators等。会议还讨论了未来芯片设计的趋势,例如3D堆叠技术、定制芯片等。
此外,Intel在会议上介绍了其未来的芯片设计策略,即推出基于Alder Lake架构的全新一代处理器,并强调了大小核设计的重要性。同时,其他公司也在会议上展示了多款创新芯片,包括AMD的Ryzen 5000处理器、Apple的M1芯片等。

Hot Chips 33
会议首先由来自 Arm 的组织主席 Ian Bratt 和来自加州大学伯克利分校的项目联合主席 Alisa Scherer 对会议内容进行整体介绍。Ian Bratt 在 Arm 有10年的工作经历,是 Machines Learning Group 的 Fellow。Alisa Scherer 曾在 AMD 工作7年,而后在加州大学伯克利分校任顾问。
会议包括8个 Session ,分别为以下主题:
1. CPUs
2. Academic Spinout Chips
3.Infrastructure and Data Processors
4.Enabling chips for Automotive, 5G, and High-bandwidth Memory
5. ML Inference for the Cloud
6. ML and Computation Platforms
7. Graphics and Video
8. New Technologies: sensors, quantum computing, and AR contact lenses
Tutorial包含两个方面:
1. ML Performance and Real World Applications
2. Advanced Packaging以及3个Keynote以及18个Poster
会议要点摘要:
核心设计
该报告指出,Alder Lake 的设计面向传统的单线程通用计算与新兴的并发和机器学习两种不同应用场景,同时追求可控的功耗与 die 大小,为用户提供更好的体验。为此,Alder Lake 从以往由多个高性能核心组成处理器转变为由高性能核和高能效核共同组成处理器。高性能和高能效核心微结构不同但支持指令集相同。

根据报告,高性能核心引入了用于矩阵计算的协处理器和更智能的电源管理控制器,具有相比以往高性能核心更深的流水线和更宽的后端执行单元,高能效核心保留了乱序执行及uop调度器特性(根据Intel架构日报告补充),但为了平衡功耗和性能没有加入新的矩阵引擎。报告后续图中给出了高性能核心和高能效核心间IPC比值随workload不同的统计数据。可以注意到,当前主流应用下高性能核心相对高能效核心IPC比往往不足1.5,高能效核心能够满足主流应用需要,或许得益于较浅的流水线,在某些高强度循环场景下高能效核心甚至可以有更好的性能表现。
前端
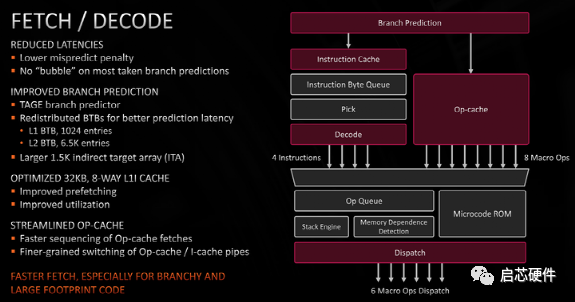
从这张图里能看出Zen3的前端采用了 decoupled 结构,先 bp 再取指,有效减少了前端的取指空泡数量,分支预测方面,加入了 Tage 预测器,增大了间接跳转预测器容量,Icache 增强了预取和利用率,micro op cache 方面提升了取指速度,并能细粒度的在 op cache 和 Icache 之间切换。减少前端的取指空泡能提升分支指令较多的程序的性能,提升间接跳转预测器容量能对 large footprint 的程序带来很好的提升,因此 AMD 强调了 "especially for branchy and large footprint code"。
整数执行
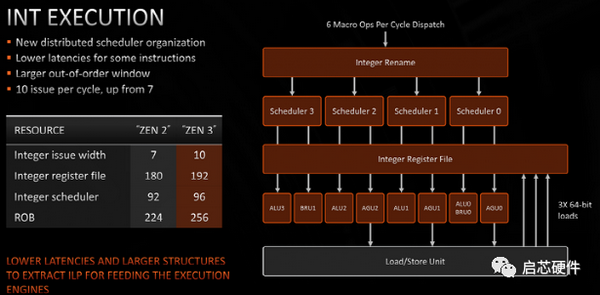
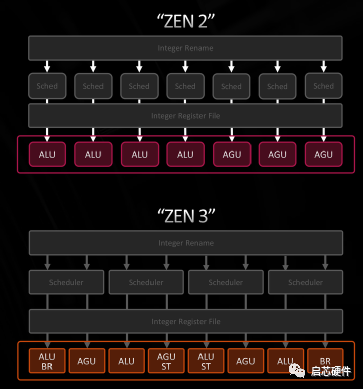
从图中可以看出 Zen3 是发射后读寄存器堆,所以这里的 scheduler 大小指的应该是 issue queue 的大小,4 个分布式的 issue queue,总大小 96 项,这边除了增大 ROB、寄存器堆之外的一个主要改动是把 7 issue 改成了 10 issue,增加的三个分别是一个 BR + 两个 STD,branch 和 store data都只需要读寄存器,不需要写寄存器,所以这里的修改不会增加处理器中 bypass 网络和寄存器堆的写口数,能以较小的开销提升处理器性能。
浮点执行
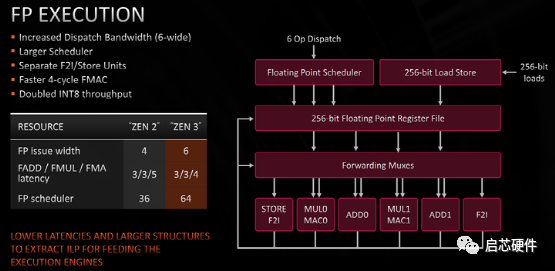
浮点方面,相比Zen2让Float To Int / FP Store指令跟FMUL/FADD共享发射宽度,Zen3为F2I / FP Store增加了专用的发射端口,这样做能够提升浮点单元向内存/定点寄存器堆传输数据的带宽,并且不占用正常浮点运算的带宽,这样的修改应该是和他们特定的workload需求相关的。此外还可以从图中看出,Zen3是将FADD和FMUL分离的,这表明他们的浮点乘累加运算实现方式很可能是分离式FMA结构,而不是传统的融合式FMA。分离式FMA是先算浮点加法,将未舍入的浮点加法结果送到浮点乘法器再和第三个操作数做乘法运算,最后舍入,其好处是能够在FMA的两个加法操作数ready后就立即开始计算,而不需要等待第三个乘法操作数准备就绪,另一方面,分离式FMA也能为单独的FADD和FMUL带来更短的延迟,这样的设计在CPU中能有效降低浮点运算总延迟。
load store
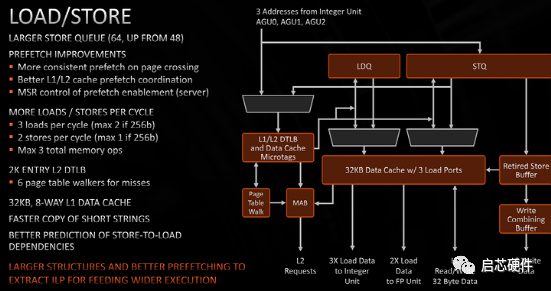
layout
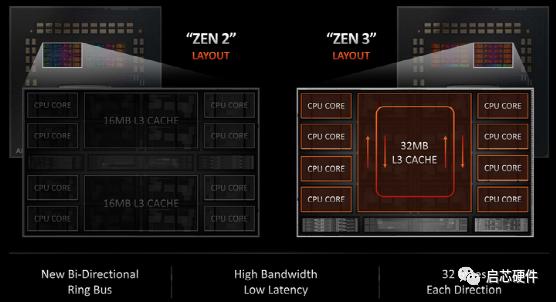
Zen2是8个核分2组,每组只能访问16MB的L3,Zen3为L3加了个环形总线,8个核可以无差别的共享32MB的L3。
计算IP
Sapphire Rapids通过提高核心数量、提高AI计算性能和数据中心广泛使用的相关加速器提供最高级别的计算性能。

主要的微架构设计
在core的架构中,基于Intel之前几代的经验,数据中心的workloads中代码有很大的footprint,并受到前端性能的限制,因此Intel重新设计了前端以解决这类瓶颈。 此外core中有多项改进例如VM拒绝保护服务、增强的Cache包括每个core私有的2MB L2 Cache和多用户的新TLB QoS功能,为了给多用户使用的情况下提供一致的性能。
新的架构增强功能
集成了AMX功能来加速AI workloads的tensor operations;
引入加速器接口架构指令集(AiA)以在用户模式支持高效的调度、同步和向加速器和设备发送信号,而不是在高开销的内核模式下做这些事;
为了满足日益增长的信号处理需求,向AVX引入了半精度浮点指令;
CLDEMOTE指令,有助于优化Cache层次结构中的数据移动以改进共享数据使用模型。
Intel在演讲中提出加速器可以极大的提高性能、降低功率和面积,但是仅仅添加加速器并不能够真正的集成这些功能,主要的困难在于数据的共享和内存管理,因此AiA和高级虚拟化技术能够避免内核模式的开销,或其他类似的复杂内存管理,这是解决加速器集成问题的基础。除此以外又介绍了几个Acceleration Engines:
Data Streming:数据移动加速,可以在CPU Cahe和IO设备之间移动数据;
Quick Assit Technology:密码和数据压缩/解压缩加速,最大400Gb/s的对称加密,160Gb/s的压缩和解压缩,并且加密和压缩可以混合操作;
Dynamic Load Balancer:动态负载平衡器,负责管理任务,每秒能够做出多大4亿个负载决策。
IO
Sapphire Rapids通过CXL1.1、PCIe Gen 5和UPI2.0提供领先的IO功能。
Sapphire Rapids引入对了CXL1.1和PCIe Gen 5的支持,同时还增强了QoS和DDIO功能,通过改进Intel Ultra Path Interconnect (UPI) 2.0提供增强的Multi-Socket,与前几代相比支持更多链接,更多的宽度和速度。
Shared Virtual Memory (SVM):实现内核集成加速器和离散的IO设备的关键技术,能够通过提供一致的内存视图来显着降低内存管理的开销。
Scalable IO Virtualization (S-IOV):支持集成或离散的设备,能够共享并直接访问加速器。
Memory
Sapphire Rapids通过DDR 5,Optane和HBM提供Intel的最高带宽和低延迟的内存解决方案。
IO功能需要通过适当平衡Cache和内存架构来提供持续的带宽和低延迟。
Sapphire Rapids支持动态的大型共享缓存,共享整个sockets,与上一代相比共享缓冲容量几乎翻倍,并增强了关键的QoS功能,通过DDR5来进一步提高效率,此外,Sapphire Rapids通过下一代Intel Optane内存提供多倍的性能改进和QoS功能,但是好像还没有完成。
此外Sapphire Rapids还提供集成了高带宽内存(HBM)的产品版本,应对高性能计算中普遍存在的并行计算、AI、机器学习和内存数据分析等workloads。
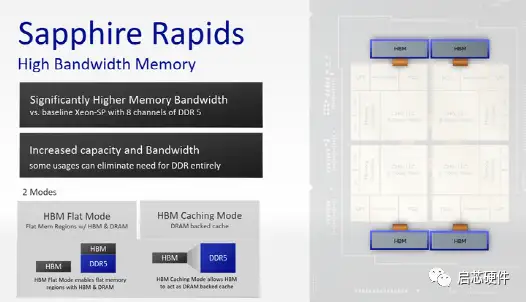
总结
Sapphire Rapids通过改进微架构、IO和内存三个方面为整个核的性能带来了巨大的提升,可以看出在更加复杂的workloads的背景下,如何提供高带宽低延迟的内存管理是非常核心的问题。其次对AI、机器学习相关的计算能力优化也是现代处理器一个重要的发展方向,针对特定功能的加速器集成也是处理器厂商中流行的一种方案。尤其在AI方面,针对特定算子和算法的加速已经成为CPU设计不可或缺的一部分,Intel已经在微架构中引入加速器接口架构指令集以支持在用户模式下与各个加速器高效的交互。

其次是AMD谈论其最新的Zen 3核心微体系结构。随着Zen 3于去年第四季度投放市场,具有更新的后端和统一的L3缓存结构,我怀疑我们是否会在这次演讲中看到任何新内容。因为硬件已经过全面测试;AMD通常使用Hot Chips刷新市场上已有的产品,并且第二天还会有RDNA2演讲,预计也将具有类似的性质。
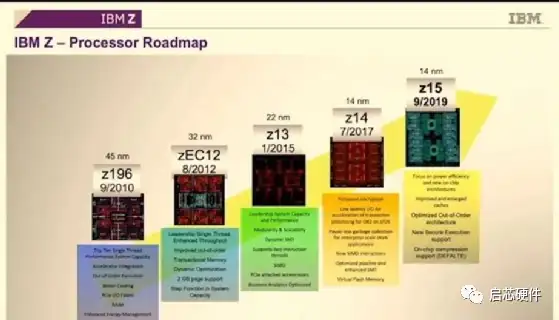
第三是IBM讨论其下一代大型机架构和产品线,即Z处理器。我们已经在先前的Hot Chips活动中介绍过IBM讨论z14和z15的内容,因此,这次演讲应该是对z15的更深入研究(已在去年进行了详细介绍),或者是对即将面世的z16设计的新外观。Z大型机解决方案通常通过统一的多机架方法由计算处理器和控制/缓存处理器组,-因为此演讲的标题是“处理器芯片”,我怀疑它比解决方案更多地涉及计算处理器,但希望将来会有一两张关于它们如何组合在一起的幻灯片。 --------------------------------------
全部会议资料下载链接分享: 链接:
https://pan.baidu.com/s/1jqKxCwbeIFbmMPHdMKH3MQ?pwd=qxcc
提取码:qxcc

 浙公网安备 33010602011771号
浙公网安备 33010602011771号