KMP算法
字符串匹配算法,是在实际工程中经常遇到的问题,常见的算法包括:BF(Brute Force,暴力检索)、RK(Robin-Karp,哈希检索)、KMP(教科书上最常见算法)、BM(Boyer Moore)、Sunday等,本篇,我们主要讨论kmp算法。
在说KMP算法之前,我们先看看简单匹配算法(也叫暴力检索)。
简单匹配算法(BF)
首先将原字符串和子串左端对齐,逐一比较;如果第一个字符不能匹配,则子串向后移动一位继续比较;如果第一个字符匹配,则继续比较后续字符,直至全部匹配。
代码实现
n = len(T) m = len(P) for s in range(0, n-m+1): k = 0 for i in range(0, m): if T[s+i] != P[i]: break else: k += 1 if k == m: print s
算法分析
最坏情况:
外层循环: n – m
内层循环: m
总计 (n–m)m = O(nm)
最好情况: n-m
完全随机的文本和模式:
O(n–m)
KMP算法(Knuth-Morris-Pratt)
KMP算法的核心,是一个被称为部分匹配表(Partial Match Table)的数组。
对于字符串“abababca”,它的PMT如下表所示:
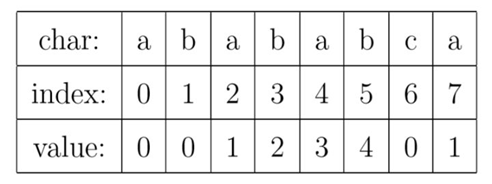
就像例子中所示的,如果待匹配的模式字符串有8个字符,那么PMT就会有8个值。
我先解释一下字符串的前缀和后缀。如果字符串A和B,存在A=BS,其中S是任意的非空字符串,那就称B为A的前缀。例如,”Harry”的前缀包括{”H”, ”Ha”, ”Har”, ”Harr”},我们把所有前缀组成的集合,称为字符串的前缀集合。同样可以定义后缀A=SB, 其中S是任意的非空字符串,那就称B为A的后缀,例如,”Potter”的后缀包括{”otter”, ”tter”, ”ter”, ”er”, ”r”},然后把所有后缀组成的集合,称为字符串的后缀集合。要注意的是,字符串本身并不是自己的后缀。
有了这个定义,就可以说明PMT中的值的意义了。PMT中的值是字符串的前缀集合与后缀集合的交集中最长元素的长度。例如,对于”aba”,它的前缀集合为{”a”, ”ab”},后缀集合为{”ba”, ”a”}。两个集合的交集为{”a”},那么长度最长的元素就是字符串”a”了,长度为1,所以对于”aba”而言,它在PMT表中对应的值就是1。再比如,对于字符串”ababa”,它的前缀集合为{”a”, ”ab”, ”aba”, ”abab”},它的后缀集合为{”baba”, ”aba”, ”ba”, ”a”}, 两个集合的交集为{”a”,”aba”},其中最长的元素为”aba”,长度为3。
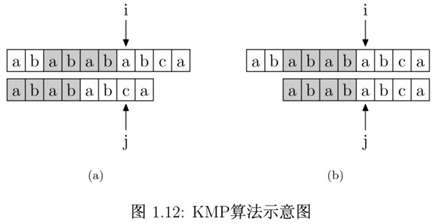
好了,解释清楚这个表是什么之后,我们再来看如何使用这个表来加速字符串的查找,以及这样用的道理是什么。如图 1.12 所示,要在主字符串"ababababca"中查找模式字符串"abababca"。如果在 j 处字符不匹配,那么由于前边所说的模式字符串PMT的性质,主字符串中i指针之前的PMT[j −1]位就一定与模式字符串的第0位至第 PMT[j−1]位是相同的。这是因为主字符串在i位失配,也就意味着主字符串从 i−j 到 i这一段是与模式字符串的0到j这一段是完全相同的。而我们上面也解释了,模式字符串从0到j−1,在这个例子中就是”ababab”,其前缀集合与后缀集合的交集的最长元素为”abab”,长度为4。所以就可以断言,主字符串中i指针之前的 4 位一定与模式字符串的第0位至第 4 位是相同的,即长度为 4 的后缀与前缀相同。这样一来,我们就可以将这些字符段的比较省略掉。具体的做法是,保持i指针不动,然后将j指针指向模式字符串的PMT[j −1]位即可。
简言之,以图中的例子来说,在i处失配,那么主字符串和模式字符串的前边6位就是相同的。又因为模式字符串的前6位,它的前4位前缀和后4位后缀是相同的,所以我们推知主字符串i之前的4位和模式字符串开头的4位是相同的。就是图中的灰色部分。那这部分就不用再比较了。
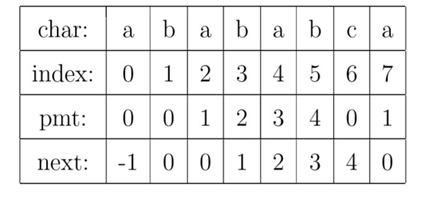
有了上面的思路,我们就可以使用PMT加速字符串的查找了。我们看到如果是在j位失配,那么影响 j指针回溯的位置的其实是第j −1位的PMT值,所以为了编程的方便,我们不直接使用PMT数组,而是将PMT数组向后偏移一位。我们把新得到的这个数组称为next数组。下面给出根据next数组进行字符串匹配加速的字符串匹配程序。其中要注意的一个技巧是,在把PMT进行向右偏移时,第0位的值,我们将其设成了-1,这只是为了编程的方便,并没有其他的意义。在本节的例子中,next数组如下表所示。
具体的程序如下所示:
int KMP(char * t, char * p) { int i = 0; int j = 0; while (i < strlen(t) && j < strlen(p)) { if (j == -1 || t[i] == p[j]) { i++; j++; } else j = next[j]; } if (j == strlen(p)) return i - j; else return -1; }
好了,讲到这里,其实KMP算法的主体就已经讲解完了。只要搞明白了PMT的意义,其实整个算法都迎刃而解。
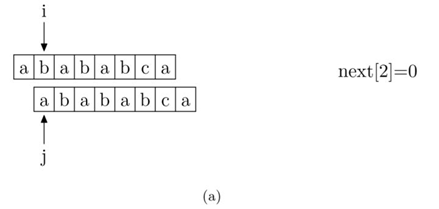
现在,我们再看一下如何编程快速求得next数组。其实,求next数组的过程完全可以看成字符串匹配的过程,即以模式字符串为主字符串,以模式字符串的前缀为目标字符串,一旦字符串匹配成功,那么当前的next值就是匹配成功的字符串的长度。
具体来说,就是从模式字符串的第一位(注意,不包括第0位)开始对自身进行匹配运算。在任一位置,能匹配的最长长度就是当前位置的next值。如下图所示。
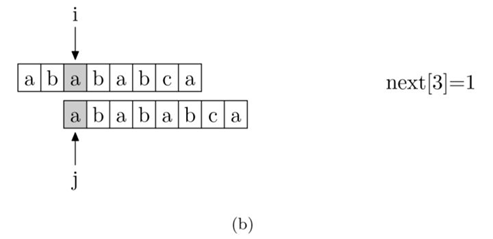
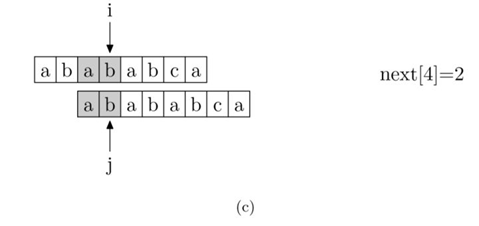
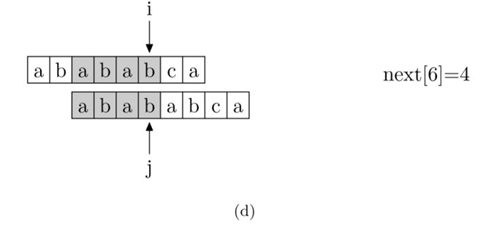
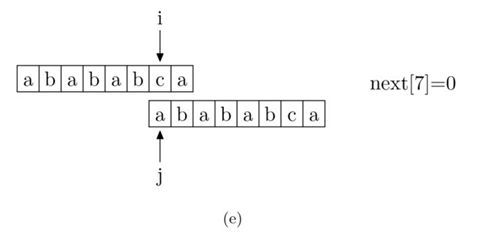
求next数组值的程序如下所示:
void getNext(char * p, int * next) { next[0] = -1; int i = 0, j = -1; while (i < strlen(p)) { if (j == -1 || p[i] == p[j]) { ++i; ++j; next[i] = j; } else j = next[j]; } }
C#实现
// 构造 pattern 的最大匹配数表 static int[] CalculateMaxMatchLengths(String pattern) { int[] maxMatchLengths = new int[pattern.Length]; int maxLength = 0; for (int i = 1; i < pattern.Length; i++) { //上一个最大长度的元素与本次的匹配的元素不相等,maxLength会被赋值到上一个maxLength,然后继续匹配,直到找到相同的。 while (maxLength > 0 && pattern[maxLength] != pattern[i]) { maxLength = maxMatchLengths[maxLength - 1]; } if (pattern[i] == pattern[maxLength]) { maxLength++; } //这里自动省略对i=0的赋值,也就变成默认为0 maxMatchLengths[i] = maxLength; } return maxMatchLengths; }
KMP算法分析
运行时间: O(n+m)
主算法: O(n)
Compute-Prefix-Table: O(m)
空间: O(m)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号