


freeswitch APR库内存池

概述
freeswitch的核心源代码是基于apr库开发的,在不同的系统上有很好的移植性。
apr库中的大部分API都需要依赖于内存池,使用内存池简化内存管理,提高内存分配效率,减少内存操作中出错的概率。
在fs的自定义模块开发中,我们也会用到内存池来操作内存,所以要对内存池的基本操作和使用限制有一定了解,防止错误的使用,导致程序运行问题。
下面我们对apr的内存池接口做一个介绍。
环境
centos:CentOS release 7.0 (Final)或以上版本
freeswitch:v1.8.7
GCC:4.8.5
内存池源码
apr库的内存池源代码文件在libs/apr目录下
libs\apr\include\apr_pools.h
libs\apr\memory\unix\apr_pools.c
内存池结构体apr_pool_t的定义在apr_pools.c文件中
struct apr_pool_t {
apr_pool_t *parent;
apr_pool_t *child;
apr_pool_t *sibling;
apr_pool_t **ref;
cleanup_t *cleanups;
cleanup_t *free_cleanups;
apr_allocator_t *allocator;
struct process_chain *subprocesses;
apr_abortfunc_t abort_fn;
apr_hash_t *user_data;
const char *tag;
#if APR_HAS_THREADS
apr_thread_mutex_t *user_mutex;
#endif
#if !APR_POOL_DEBUG
apr_memnode_t *active;
apr_memnode_t *self; /* The node containing the pool itself */
char *self_first_avail;
#else /* APR_POOL_DEBUG */
apr_pool_t *joined; /* the caller has guaranteed that this pool
* will survive as long as ->joined */
debug_node_t *nodes;
const char *file_line;
apr_uint32_t creation_flags;
unsigned int stat_alloc;
unsigned int stat_total_alloc;
unsigned int stat_clear;
#if APR_HAS_THREADS
apr_os_thread_t owner;
apr_thread_mutex_t *mutex;
#endif /* APR_HAS_THREADS */
#endif /* APR_POOL_DEBUG */
#ifdef NETWARE
apr_os_proc_t owner_proc;
#endif /* defined(NETWARE) */
};
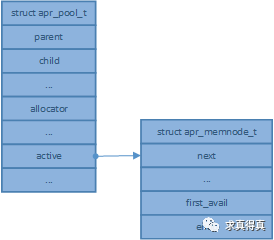
从结构体的定义来看,在使用内存池的过程中主要关注“apr_memnode_t *active;”和“char *self_first_avail;”俩个变量。
变量active是当前内存池中内存节点链表的第一个节点,也可以从名字理解是活动节点。
变量self_first_avail是当前内存池中可用内存的起始点。
常用函数
查看源代码头文件libs\apr\include\apr_pools.h
…
APR_DECLARE(apr_status_t) apr_pool_create(apr_pool_t **newpool, apr_pool_t *parent);
APR_DECLARE(void) apr_pool_clear(apr_pool_t *p);
APR_DECLARE(void) apr_pool_destroy(apr_pool_t *p);
APR_DECLARE(void *) apr_palloc(apr_pool_t *p, apr_size_t size);
…
使用apr_pool_create函数创建内存池
使用apr_pool_clear函数清空内存池
使用apr_pool_destroy函数销毁整个内存池
使用apr_palloc函数从内存池获取指定大小的内存块
创建create
apr_pool_create接口是apr_pool_create_ex的简化版,省略了4个参数中的后俩个,简化了用户的调用过程,下面我们介绍apr_pool_create_ex的代码逻辑。
- 传入参数parent父节点为空,则使用global_pool作为父节点
- 传入参数abort_fn内存分配失败回调函数为空,则使用父节点的回调函数
- 传入参数allocator分配器为空,则使用父节点的allocator分配器
- 使用allocator分配器获取一块内存节点node,大小为“MIN_ALLOC - APR_MEMNODE_T_SIZE”
- 初始化内存池pool,对“pool->active”赋值为节点node
这里可以看出内存池pool刚创建的时候,“pool->active”变量只有一个内存节点,大小为“MIN_ALLOC - APR_MEMNODE_T_SIZE”,根据宏定义计算大小为8192-40=8152字节。
清空clear
apr_pool_clear代码逻辑。
- 销毁内存池pool的所有子内存池。
- 清理pool中的额外设置,包括cleanup、subprocess和user_data。
- 重置pool->active,保留1个内存节点并重置起点,释放多余节点。
经过clear的内存池pool,回归到了刚刚create出来的状态。
销毁destory
apr_pool_destroy的代码逻辑。
- 销毁内存池pool的所有子内存池。
- 清理pool中的额外设置,包括cleanup、subprocess和父节点指针。
- 释放pool->active所有节点。
- 销毁当前内存池拥有的allocator分配器。
经过destory的内存池,占用的所有内存都会释放掉。
分配alloc
apr_palloc接口的代码逻辑。
- 传入参数size按照8字节做内存对齐
- 检查pool->active节点数据,如果节点剩余空间满足分配请求的大小,则直接在pool->active节点分配空间并返回。
- 获取pool->active->next节点,检查节点数据。
a) 如果节点剩余空间满足分配请求的大小,则将该节点从list中删除,保存为node节点。
b) 如果节点剩余空间不满足,则使用pool->allocator分配器获取大小为size的内存节点,保存为node节点。
- 修改node节点数据,记录node->first_avail并作为分配请求的返回数据,修改node->first_avail起始空间点+size。
- 将node节点插入active列表的首位。
- 判断node节点的剩余空间,并将active列表按照node节点剩余空间的大小由大到小排序 。
经过多次apr_palloc后,pool->active节点列表会产生多个新的节点,组成node链表。

自动扩展的问题
从分配alloc的代码逻辑可以看出,当内存池的空间不足时,apr_palloc会生成新的node节点扩展内存池空间。
内存池的内存空间并非是连续的,而是以单向链表的形式组合多个node节点,并且没有node个数的限制,理论上可以无限扩展直到内存被占满。
apr内存池没有内存回收接口,即使有内存空间明确不再需要使用,apr_pools也没有提供对应的回收接口,除非对整个内存池执行clear或者destroy,才能回收整个内存池空间。
总结
从apr库内存池的接口逻辑来看,该内存池更多适用于会话式场景,一个新的会话对应一个内存池,会话结束后,直接对内存池整体回收,简化会话过程中的内存管理。
而对于更长的生命周期的代码逻辑来说,使用上需要注意内存占用问题,防止内存的无限增长。
另外,apr内存池还有一些特性(包括调试、多线程、分配失败回调、子池等)需要更深入的学习和测试。
空空如常
求真得真

