

机器学习实战:沃尔玛销售预测
一、简介
1.1 比赛描述
建模零售数据的一个挑战是需要根据有限的历史做出决策。如果圣诞节一年一次,那么有机会看到战略决策如何影响到底线。
在此招聘竞赛中,为求职者提供位于不同地区的45家沃尔玛商店的历史销售数据。每个商店都包含许多部门,参与者必须为每个商店中的每个部门预测销售额。要添加挑战,选定的假日降价事件将包含在数据集中。众所周知,这些降价会影响销售,但预测哪些部门受到影响以及影响程度具有挑战性。
想要在世界上最大的一些数据集的良好环境中工作吗?这是向沃尔玛招聘团队展示您的模特气概的机会。
这项比赛计入排名和成就。 如果您希望考虑参加沃尔玛的面试,请在第一次参加时选中“允许主持人与我联系”复选框。
你必须在招募比赛中作为个人参加比赛。您只能使用提供的数据进行预测。
1.2 比赛评估
本次比赛的加权平均绝对误差(WMAE)评估:
n是行数
yi是真实销售额
wi是权重,如果该周是假日周,wi=5,否则为1
提交文件:Id列是通过将Store,Dept和Date与下划线连接而形成的(例如Store_Dept_2012-11-02)
对于测试集中的每一行(商店+部门+日期三元组),您应该预测该部门的每周销售额。
1.3 数据描述
您将获得位于不同地区的45家沃尔玛商店的历史销售数据。每个商店都包含许多部门,您的任务是预测每个商店的部门范围内的销售额。
此外,沃尔玛全年举办多项促销降价活动。这些降价活动在突出的假期之前,其中最大的四个是超级碗,劳动节,感恩节和圣诞节。包括这些假期的周数在评估中的加权比非假日周高五倍。本次比赛提出的部分挑战是在没有完整/理想的历史数据的情况下模拟降价对这些假期周的影响。
stores.csv:
此文件包含有关45个商店的匿名信息,指示商店的类型和大小。
train.csv:
这是历史销售数据,涵盖2010-02-05至2012-11-01。在此文件中,您将找到以下字段:
Store - 商店编号
Dept - 部门编号
Date - 一周
Weekly_Sales - 给定商店中给定部门的销售额(目标值)
sHoliday - 周是否是一个特殊的假日周
test.csv:
此文件与train.csv相同,但我们保留了每周销售额。您必须预测此文件中每个商店,部门和日期三元组的销售额。
features.csv:
此文件包含与给定日期的商店,部门和区域活动相关的其他数据。它包含以下字段:
Store - 商店编号
Date - 一周
Temperature - 该地区的平均温度
Fuel_Price - 该地区的燃料成本
MarkDown1-5 - 与沃尔玛正在运营的促销降价相关的匿名数据。MarkDown数据仅在2011年11月之后提供,并非始终适用于所有商店。任何缺失值都标有NA。
CPI - 消费者物价指数
Unemployment - 失业率
IsHoliday - 周是否是一个特殊的假日周
为方便起见,数据集中的四个假期在接下来的几周内(并非所有假期都在数据中):
超级碗:2月12日至10日,11月2日至11日,10月2日至12日,2月8日至2月13
日劳动节:10月9日至10日,9月9日至9日,9月9日至9月12日-13
感恩节:26-Nov- 10,25 -Nov-11,23-Nov-12,29-Nov-13
圣诞节:31-Dec-10,30-Dec-11,28-Dec-12,27-Dec -13
二、代码
将数据存在GitHub的压缩包里,直接运行下载即可,或去kaggle下载数据,链接:https://www.kaggle.com/c/walmart-recruiting-store-sales-forecasting
2.1.1 下载数据
import os import zipfile from six.moves import urllib FILE_NAME = "walmart-recruiting-store-sales-forecasting.zip" #文件名 DATA_PATH ="datasets/walmart-recruiting-store-sales-forecasting" #存储文件的文件夹,取跟文件相同(相近)的名字便于区分 DATA_URL = "https://github.com/824024445/KaggleCases/blob/master/datasets/" + FILE_NAME + "?raw=true" def fetch_data(data_url=DATA_URL, data_path=DATA_PATH, file_name=FILE_NAME): if not os.path.isdir(data_path): #查看当前文件夹下是否存在"datasets/titanic",没有的话创建 os.makedirs(data_path) zip_path = os.path.join(data_path, file_name) #下载到本地的文件的路径及名称 # urlretrieve()方法直接将远程数据下载到本地 urllib.request.urlretrieve(data_url, zip_path) #第二个参数zip_path是保存到的本地路径 data_zip = zipfile.ZipFile(zip_path) data_zip.extractall(path=data_path) #什么参数都不输入就是默认解压到当前文件,为了保持统一,是泰坦尼克的数据就全部存到titanic文件夹下 data_zip.close() fetch_data()
2.1.2 读取数据
import pandas as pd import numpy as np train_df = pd.read_csv("datasets/walmart-recruiting-store-sales-forecasting/train.csv") test_df = pd.read_csv("datasets/walmart-recruiting-store-sales-forecasting/test.csv") features = pd.read_csv("datasets/walmart-recruiting-store-sales-forecasting/features.csv") stores = pd.read_csv("datasets/walmart-recruiting-store-sales-forecasting/stores.csv") train_df = train_df.merge(features, on=["Store", "Date"], how="left").merge(stores, on="Store", how="left") test_df = test_df.merge(features, on=["Store", "Date"], how="left").merge(stores, on="Store", how="left") combine = [train_df, test_df] train_df.head()
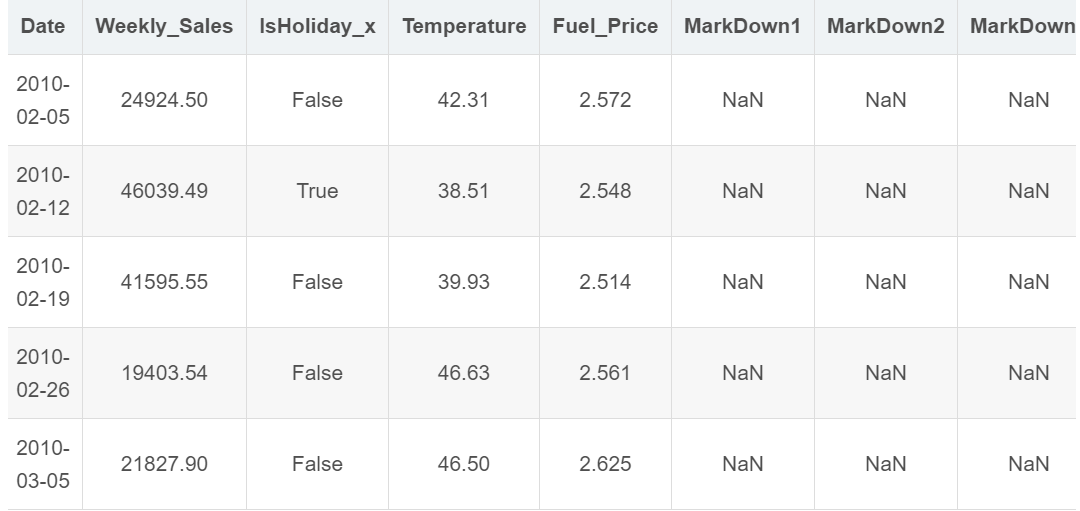
train_df.info()
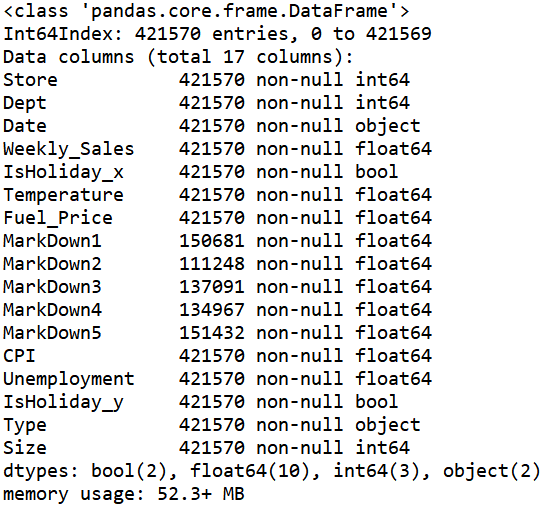
test_df.info()
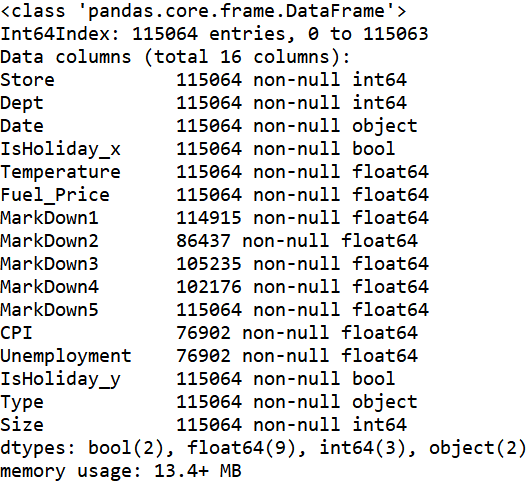
train_df.describe()
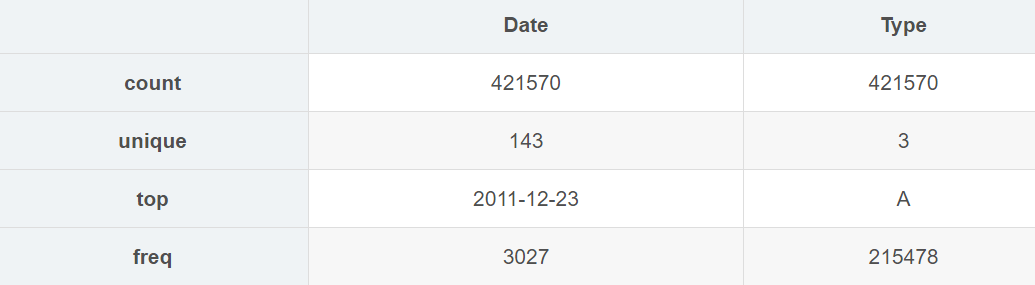
train_df.describe(include="O")
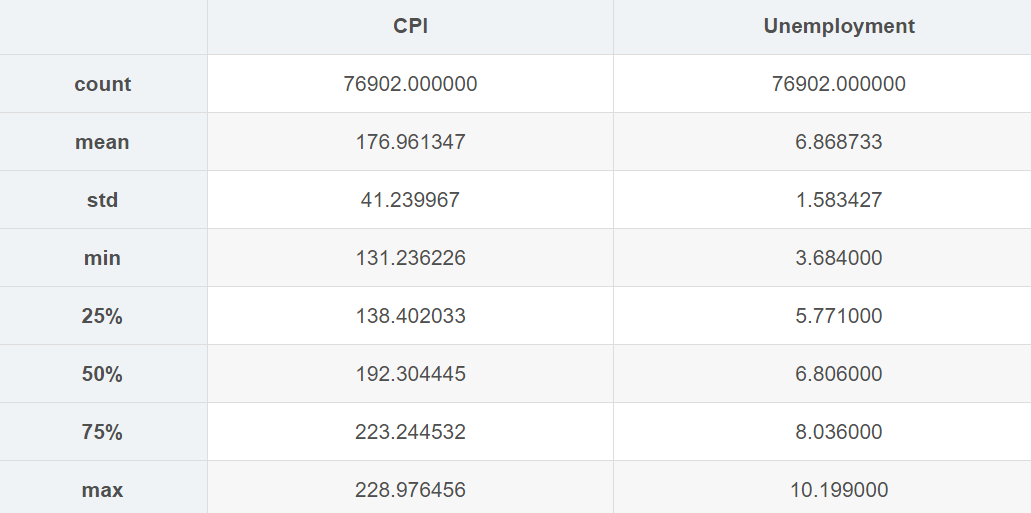
#各变量与Weekly_Sales的关系
corr_matrix = train_df.corr()
corr_matrix.Weekly_Sales.sort_values(ascending=False)

corr_matrix[["MarkDown1","MarkDown2","MarkDown3","MarkDown4","MarkDown5"]].sort_values(by="MarkDown5", ascending=False)
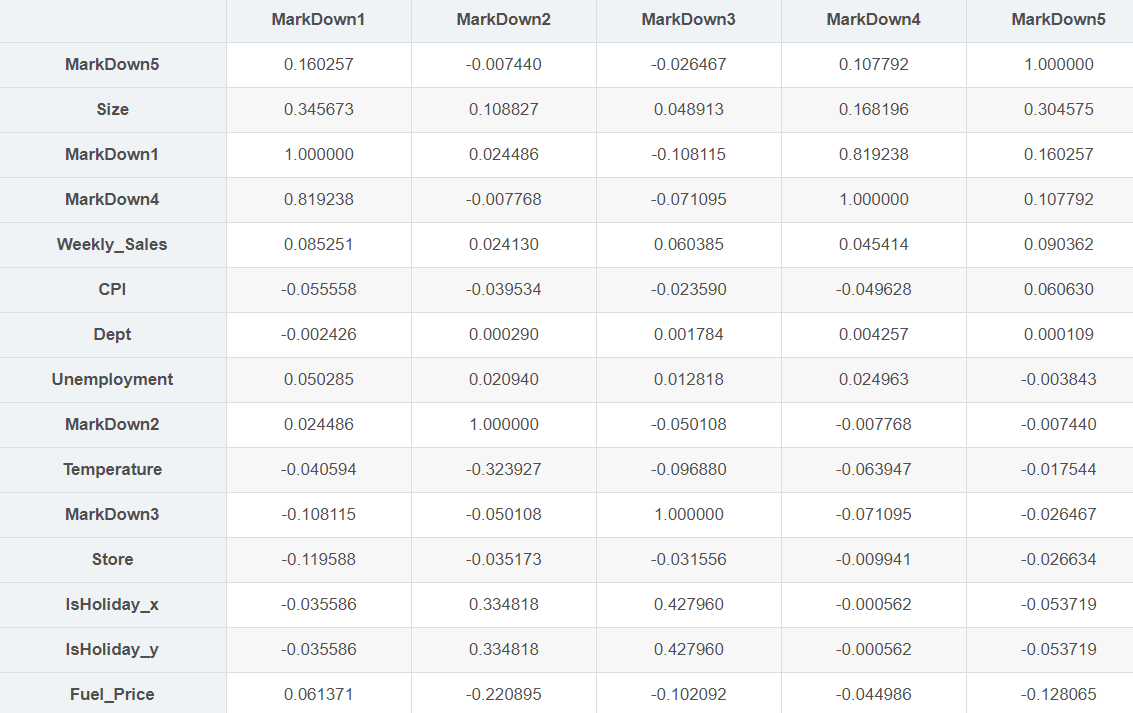
- markdown1和4的关联度比较大,只需要要一个就行,删除markdown4
2.3 数据清洗
2.3.1 缺失值处理
## Markdown 对于训练集markdown的缺失,这里先不处理,等会分成两个数据集,一个含缺失markdown然后填充,一个去掉这些数据 test_df[['MarkDown1','MarkDown2','MarkDown3','MarkDown5']] = test_df[['MarkDown1','MarkDown2','MarkDown3','MarkDown5']].fillna(0) test_df[["CPI","Unemployment"]] = test_df[["CPI","Unemployment"]].fillna(method="ffill")
2.3.2 创建新特征
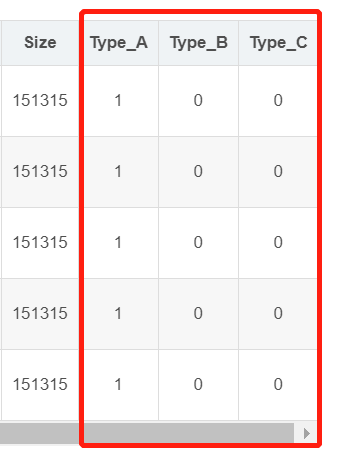
将type列转变成onehot编码
train_df = pd.get_dummies(train_df, columns=["Type"]) test_df = pd.get_dummies(test_df, columns=["Type"]) train_df.head()
把日期换成月份
train_df['Month'] = pd.to_datetime(train_df['Date']).dt.month test_df["Month"] = pd.to_datetime(test_df['Date']).dt.month #等下记得删除Date,test的暂时先不删,后面要用
温度
想来,人们在极端天气的时候不太会出门。所以把数据分成两组:小于22.01,大于91.03(根据温度分布划分的,画柱状图可得,我已经删掉了)
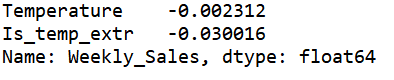
train_df.loc[(train_df["Temperature"]<22.01)|(train_df["Temperature"]>91.03), "Is_temp_extr"]=1 train_df.loc[(train_df["Temperature"]>=22.01)& (train_df["Temperature"]<=91.03), "Is_temp_extr"]=0 test_df.loc[(test_df["Temperature"]<22.01)|(test_df["Temperature"]>91.03), "Is_temp_extr"]=1 test_df.loc[(test_df["Temperature"]>=22.01)& (test_df["Temperature"]<=91.03), "Is_temp_extr"]=0 train_df.corr().Weekly_Sales.sort_values(ascending=False)[["Temperature", "Is_temp_extr"]] #提取新特征后相关性提升了十多倍 等下记得把这个特征删除。
燃油价格
人们会因为燃油费太贵不出门吗?
train_df.loc[train_df["Fuel_Price"]>3.47, "Is_fuel_expen"]=1 train_df.loc[train_df["Fuel_Price"]<=3.47, "Is_fuel_expen"]=0 #无论怎么改,这个相关性都很低,所以这个特征等下去除 train_df.corr().Weekly_Sales.sort_values(ascending=False)[["Fuel_Price", "Is_fuel_expen"]]

IsHoliday
(在最开始df.merge时)
由于前面合并表格的时候的问题,出现了两个isholidy,删掉一个即可。
另外,把bool值换成0和5(后面权重),新建一列IsHoliday,一会吧IsHoliday_x,IsHoliday_y删掉
train_df["IsHoliday"] = train_df["IsHoliday_x"].replace(True, 5).replace(False,0) test_df["IsHoliday"] = test_df["IsHoliday_x"].replace(True, 5).replace(False,0) train_df.corr().Weekly_Sales.sort_values(ascending=False)[["IsHoliday_x", "IsHoliday"]]
把刚刚处理过的多余的特征值删掉
train_df = train_df.drop(["IsHoliday_x", "IsHoliday_y",'MarkDown4',"Date", "Temperature", "Fuel_Price","Is_fuel_expen"], axis=1)
#这是后面提交表格需要用到的变量,用到了测试集的date特征,先在这里给id变量赋值,然后就可以吧date特征删除了
id = test_df["Store"].astype(str)+"_"+test_df["Dept"].astype(str)+"_"+test_df["Date"].astype(str)
test_df = test_df.drop(["IsHoliday_x", "IsHoliday_y", "MarkDown4", "Date","Temperature", "Fuel_Price"], axis=1)
最终检查
将数据集用到模型前,一定要确保没有空值,所以最后再检查一下
先把训练集做成两份:一份含缺失的markdown,一个去除掉这些数据
train_df_one = train_df.copy() train_df_two = train_df.copy() train_df_one[['MarkDown1','MarkDown2','MarkDown3','MarkDown5']] = train_df_one[['MarkDown1','MarkDown2','MarkDown3','MarkDown5']].fillna(0) train_df_two.dropna(inplace=True) train_df_one.info()

train_df_two.info()
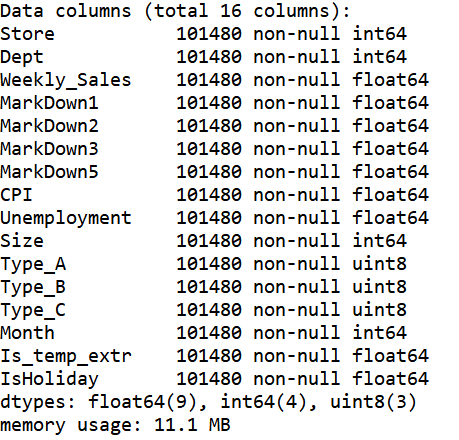
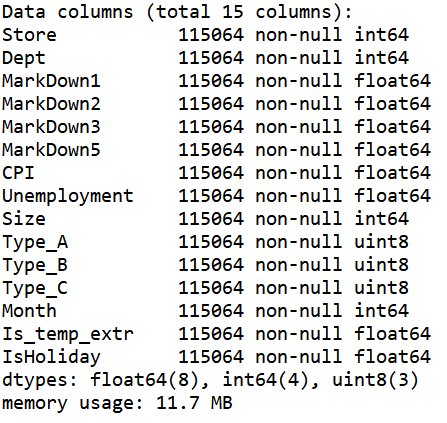
test_df.info()
模型和预测
为了快速测试,写了一个类。我写的案例大部分都回用到这个类。不过每次因为性能评测的指标不同,所以需要微改。
import time import os from sklearn.metrics import mean_absolute_error from sklearn.base import clone class Tester(): def __init__(self, target): self.target = target self.datasets = {} self.models = {} self.scores = {} self.cache = {} # 我们添加了一个简单的缓存来加快速度 def addDataset(self, name, df): self.datasets[name] = df.copy() def addModel(self, name, model): self.models[name] = model def clearModels(self): self.models = {} def clearCache(self): self.cache = {} def testModelWithDataset(self, m_name, df_name, sample_len, cv): if (m_name, df_name, sample_len, cv) in self.cache: return self.cache[(m_name, df_name, sample_len, cv)] clf = clone(self.models[m_name]) if not sample_len: sample = self.datasets[df_name] else: sample = self.datasets[df_name].sample(sample_len) X = sample.drop([self.target], axis=1) Y = sample[self.target] #评分标准不一样的话,修改这里 weights = X["IsHoliday"] clf.fit(X, Y) Y_pred = clf.predict(X) s = mean_absolute_error(Y, Y_pred, sample_weight=weights) self.cache[(m_name, df_name, sample_len, cv)] = s return s def runTests(self, sample_len=97056, cv=3): # 在所有添加的数据集上测试添加的模型 for m_name in self.models: for df_name in self.datasets: # print('Testing %s' % str((m_name, df_name)), end='') start = time.time() score = self.testModelWithDataset(m_name, df_name, sample_len, cv) self.scores[(m_name, df_name)] = score end = time.time() # print(' -- %0.2fs ' % (end - start)) print('--- Top 10 Results ---') # 评分标准改了之后这里也得改 for score in sorted(self.scores.items(), key=lambda x: x[1])[:10]: # score = int(score[1]) print(score) def obtian_result(self, X_test): clf = self.models[sorted(self.scores.items(), key=lambda x: x[1])[0][0]] Y_pred = clf.predict(X_test) return Y_pred
from sklearn.ensemble import ExtraTreesRegressor, RandomForestRegressor, GradientBoostingRegressor from sklearn.neighbors import KNeighborsRegressor from sklearn.svm import SVR from sklearn.feature_selection import RFE from sklearn.neural_network import MLPRegressor # 我们将在所有模型中使用测试对象 tester = Tester('Weekly_Sales') # 添加数据集 tester.addDataset('all_markdown', train_df_one) tester.addDataset('wipe_markdown', train_df_two) # 添加模型 knn_reg = KNeighborsRegressor(n_neighbors=10) tree_reg = ExtraTreesRegressor(n_estimators=100,max_features='auto', verbose=1, n_jobs=1) rf_reg = RandomForestRegressor(n_estimators=100,max_features='log2', verbose=1) svr_reg = SVR(kernel='rbf', gamma='auto') mlp_reg = MLPRegressor(hidden_layer_sizes=(10,), activation='relu', verbose=3) gbrt_reg = GradientBoostingRegressor(max_depth=8, warm_start=True) tester.addModel('KNeighborsRegressor', knn_reg) tester.addModel('ExtraTreesRegressor', tree_reg) tester.addModel('RandomForestRegressor', rf_reg) tester.addModel('SVR', svr_reg) tester.addModel('MLPRegressor', mlp_reg) tester.addModel('GradientBoostingRegressor', gbrt_reg) # 测试 tester.runTests()
X = train_df_one.drop(["Weekly_Sales"], axis=1) Y = train_df_one["Weekly_Sales"] gbrt_reg.fit(X, Y) Y_pred = gbrt_reg.predict(test_df) submission = pd.DataFrame({ "Id": id, "Weekly_Sales": pd.DataFrame(Y_pred)[0] }) id submission.to_csv('submission.csv', index=False)
完整代码
#下载数据
import os import zipfile from six.moves import urllib FILE_NAME = "walmart-recruiting-store-sales-forecasting.zip" #文件名 DATA_PATH ="datasets/walmart-recruiting-store-sales-forecasting" #存储文件的文件夹,取跟文件相同(相近)的名字便于区分 DATA_URL = "https://github.com/824024445/KaggleCases/blob/master/datasets/" + FILE_NAME + "?raw=true" def fetch_data(data_url=DATA_URL, data_path=DATA_PATH, file_name=FILE_NAME): if not os.path.isdir(data_path): #查看当前文件夹下是否存在"datasets/titanic",没有的话创建 os.makedirs(data_path) zip_path = os.path.join(data_path, file_name) #下载到本地的文件的路径及名称 # urlretrieve()方法直接将远程数据下载到本地 urllib.request.urlretrieve(data_url, zip_path) #第二个参数zip_path是保存到的本地路径 data_zip = zipfile.ZipFile(zip_path) data_zip.extractall(path=data_path) #什么参数都不输入就是默认解压到当前文件,为了保持统一,是泰坦尼克的数据就全部存到titanic文件夹下 data_zip.close() fetch_data() #数据处理 import pandas as pd import numpy as np train_df = pd.read_csv("datasets/walmart-recruiting-store-sales-forecasting/train.csv") test_df = pd.read_csv("datasets/walmart-recruiting-store-sales-forecasting/test.csv") features = pd.read_csv("datasets/walmart-recruiting-store-sales-forecasting/features.csv") stores = pd.read_csv("datasets/walmart-recruiting-store-sales-forecasting/stores.csv") train_df = train_df.merge(features, on=["Store", "Date"], how="left").merge(stores, on="Store", how="left") test_df = test_df.merge(features, on=["Store", "Date"], how="left").merge(stores, on="Store", how="left") combine = [train_df, test_df] train_df.head() train_df.info() test_df.info() train_df.describe() train_df.describe(include="O") #各变量与Weekly_Sales的关系 corr_matrix = train_df.corr() corr_matrix.Weekly_Sales.sort_values(ascending=False) corr_matrix[["MarkDown1","MarkDown2","MarkDown3","MarkDown4","MarkDown5"]].sort_values(by="MarkDown5", ascending=False) #数据清洗 ## Markdown 对于训练集markdown的缺失,这里先不处理,等会分成两个数据集,一个含缺失markdown然后填充,一个去掉这些数据 #缺失值处理 test_df[['MarkDown1','MarkDown2','MarkDown3','MarkDown5']] = test_df[['MarkDown1','MarkDown2','MarkDown3','MarkDown5']].fillna(0) test_df[["CPI","Unemployment"]] = test_df[["CPI","Unemployment"]].fillna(method="ffill") #创建新特征 #type转变成onehot编码 train_df = pd.get_dummies(train_df, columns=["Type"]) test_df = pd.get_dummies(test_df, columns=["Type"]) train_df.head() #把日期换成月份,便于分析 train_df['Month'] = pd.to_datetime(train_df['Date']).dt.month test_df["Month"] = pd.to_datetime(test_df['Date']).dt.month #等下记得删除Date,test的暂时先不删,后面要用 #温度 #想来,人们在极端天气的时候不太会出门。所以把数据分成两组:小于22.01,大于91.03(根据温度分布划分的,画柱状图可得,我已经删掉了) train_df.loc[(train_df["Temperature"]<22.01)|(train_df["Temperature"]>91.03), "Is_temp_extr"]=1 train_df.loc[(train_df["Temperature"]>=22.01)& (train_df["Temperature"]<=91.03), "Is_temp_extr"]=0 test_df.loc[(test_df["Temperature"]<22.01)|(test_df["Temperature"]>91.03), "Is_temp_extr"]=1 test_df.loc[(test_df["Temperature"]>=22.01)& (test_df["Temperature"]<=91.03), "Is_temp_extr"]=0 train_df.corr().Weekly_Sales.sort_values(ascending=False)[["Temperature", "Is_temp_extr"]] #提取新特征后相关性提升了十多倍 等下记得把这个特征删除。 #燃油价格 #人们会因为燃油费太贵不出门吗? train_df.loc[train_df["Fuel_Price"]>3.47, "Is_fuel_expen"]=1 train_df.loc[train_df["Fuel_Price"]<=3.47, "Is_fuel_expen"]=0 #无论怎么改,这个相关性都很低,所以这个特征等下删除 train_df.corr().Weekly_Sales.sort_values(ascending=False)[["Fuel_Price", "Is_fuel_expen"]] #IsHoliday #(在最开始df.merge时) #由于前面合并表格的时候的问题,出现了两个isholidy,删掉一个即可。 #另外,把bool值换成0和5(后面权重) train_df["IsHoliday"] = train_df["IsHoliday_x"].replace(True, 5).replace(False,0) test_df["IsHoliday"] = test_df["IsHoliday_x"].replace(True, 5).replace(False,0) #train_df.corr().Weekly_Sales.sort_values(ascending=False)[["IsHoliday_x", "IsHoliday"]] #把刚刚处理过的多余的特征值删掉 train_df = train_df.drop(["IsHoliday_x", "IsHoliday_y",'MarkDown4',"Date", "Temperature", "Fuel_Price","Is_fuel_expen"], axis=1) #这是后面提交表格需要用到的变量,用到了测试集的date特征,先在这里给id变量赋值,然后就可以吧date特征删除了 id = test_df["Store"].astype(str)+"_"+test_df["Dept"].astype(str)+"_"+test_df["Date"].astype(str) test_df = test_df.drop(["IsHoliday_x", "IsHoliday_y", "MarkDown4", "Date","Temperature", "Fuel_Price"], axis=1) #最终检查 #将数据集用到模型前,一定要确保没有空值,所以最后再检查一下 #先把训练集做成两份:一份含缺失的markdown,一个去除掉这些数据 train_df_one = train_df.copy() train_df_two = train_df.copy() train_df_one[['MarkDown1','MarkDown2','MarkDown3','MarkDown5']] = train_df_one[['MarkDown1','MarkDown2','MarkDown3','MarkDown5']].fillna(0) train_df_two.dropna(inplace=True) train_df_one.info() train_df_two.info() test_df.info() #训练模型 import time import os from sklearn.metrics import mean_absolute_error from sklearn.base import clone class Tester(): def __init__(self, target): self.target = target self.datasets = {} self.models = {} self.scores = {} self.cache = {} # 我们添加了一个简单的缓存来加快速度 def addDataset(self, name, df): self.datasets[name] = df.copy() def addModel(self, name, model): self.models[name] = model def clearModels(self): self.models = {} def clearCache(self): self.cache = {} def testModelWithDataset(self, m_name, df_name, sample_len, cv): if (m_name, df_name, sample_len, cv) in self.cache: return self.cache[(m_name, df_name, sample_len, cv)] clf = clone(self.models[m_name]) if not sample_len: sample = self.datasets[df_name] else: sample = self.datasets[df_name].sample(sample_len) X = sample.drop([self.target], axis=1) Y = sample[self.target] #评分标准不一样的话,修改这里 weights = X["IsHoliday"] clf.fit(X, Y) Y_pred = clf.predict(X) s = mean_absolute_error(Y, Y_pred, sample_weight=weights) self.cache[(m_name, df_name, sample_len, cv)] = s return s def runTests(self, sample_len=97056, cv=3): # 在所有添加的数据集上测试添加的模型 for m_name in self.models: for df_name in self.datasets: # print('Testing %s' % str((m_name, df_name)), end='') start = time.time() score = self.testModelWithDataset(m_name, df_name, sample_len, cv) self.scores[(m_name, df_name)] = score end = time.time() # print(' -- %0.2fs ' % (end - start)) print('--- Top 10 Results ---') # 评分标准改了之后这里也得改 for score in sorted(self.scores.items(), key=lambda x: x[1])[:10]: # score = int(score[1]) print(score) def obtian_result(self, X_test): clf = self.models[sorted(self.scores.items(), key=lambda x: x[1])[0][0]] Y_pred = clf.predict(X_test) return Y_pred from sklearn.ensemble import ExtraTreesRegressor, RandomForestRegressor, GradientBoostingRegressor from sklearn.neighbors import KNeighborsRegressor from sklearn.svm import SVR from sklearn.feature_selection import RFE from sklearn.neural_network import MLPRegressor # 我们将在所有模型中使用测试对象 tester = Tester('Weekly_Sales') # 添加数据集 tester.addDataset('all_markdown', train_df_one) tester.addDataset('wipe_markdown', train_df_two) # 添加模型 knn_reg = KNeighborsRegressor(n_neighbors=10) tree_reg = ExtraTreesRegressor(n_estimators=100,max_features='auto', verbose=1, n_jobs=1) rf_reg = RandomForestRegressor(n_estimators=100,max_features='log2', verbose=1) svr_reg = SVR(kernel='rbf', gamma='auto') mlp_reg = MLPRegressor(hidden_layer_sizes=(10,), activation='relu', verbose=3) gbrt_reg = GradientBoostingRegressor(max_depth=8, warm_start=True) tester.addModel('KNeighborsRegressor', knn_reg) tester.addModel('ExtraTreesRegressor', tree_reg) tester.addModel('RandomForestRegressor', rf_reg) tester.addModel('SVR', svr_reg) tester.addModel('MLPRegressor', mlp_reg) tester.addModel('GradientBoostingRegressor', gbrt_reg) # 测试 tester.runTests() X = train_df_one.drop(["Weekly_Sales"], axis=1) Y = train_df_one["Weekly_Sales"] gbrt_reg.fit(X, Y) Y_pred = gbrt_reg.predict(test_df) submission = pd.DataFrame({ "Id": id, "Weekly_Sales": pd.DataFrame(Y_pred)[0] }) id submission.to_csv('submission.csv', index=False)
