Python常用模块(3)—— shelve、pickle、json、xml、configparser
什么是序列化/反序列化?
序列化就是将内存中的数据结构转换成一种中间格式存储到硬盘或者基于网络传输,反序列化就是硬盘中或者网络中传来的一种数据格式转换成内存中数据结构
为什么要有序列化/反序列化?
1、可以保存程序的运行状态
2、数据的跨平台交互
shelve模块:也用于序列化,它于 pickle 不同之处在于不需要关心文件模式等,而是直接把它当成一个字典来看待,它可以直接对数据进行修改,而不用覆盖原来的数据,但 pickle 想要修改只能用 wb 模式来覆盖


import shelve
dic1 = {'pwd': 'qiu123', 'age': 22}
dic2 = {'pwd': 'xi456', 'age': 22}
d = shelve.open('db.txt')
d['qiu'] = dic1
d['xi'] = dic2
print(d['qiu']['pwd'])
d.close()
import shelve
d = shelve.open('db.txt')
print(d['qiu'])
print(d['qiu']['pwd'])
d.close()
import shelve
# 对子字典的修改需要参数
d = shelve.open('db.txt', writeback=True)
d['qiu']['age'] = 20
print(d['qiu'])
d.close()
pickle模块:一个用来序列化的模块
主要功能有dump(序列化)、load(反序列化)、dumps、loads。dump/load 相比于 dumps/loads,封装了 write 和 read,使用操作更方便
import pickle
dic = {'a':1, 'b':2, 'c':3}
# 1. 序列化
pkl = pickle.dumps(dic)
print(pkl, type(pkl))
# 2. 写入文件
with open('db.pkl', 'wb') as f:
f.write(pkl)
# 1和2可以合成一步
with open('db.pkl', 'wb') as f:
res = pickle.dump(dic, f)
import pickle
# 1. 从文件中读取pickle格式
with open('db.pkl', 'rb') as f:
pkl = f.read()
# 2. 将pkl_str转成内存中的数据类型
dic = pickle.loads(pkl)
print(dic)
# 1和2可以合成一步
with open('db.pkl', 'rb') as f:
dic = pickle.load(f)
print(dic)
优点:可以支持 Python 中所有的数据类型
缺点:只能被 Python 识别,不能跨平台
json模块:一个用于序列化的模块
在使用 json 模块之前,需要先了解 JSON(JavaScript Object Notation,JS的对象简谱),它表示出来的是一个字符串,可以被任何语言解析读取,方便使用
JSON 表示的对象就是标准的 JavaScript 语言的对象,JSON 和 Python 内置的数据类型对应如下:
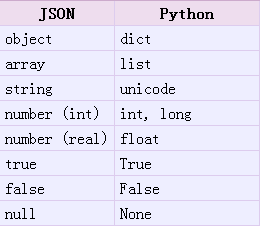
import json
dic = {'name': 'qiuxi', 'age': 22}
# 序列化: 内存中的数据类型转化成中间格式json
json_str = json.dumps(dic)
print(json_str, type(json_str))
# 运行
{"name": "qiuxi", "age": 22} <class 'str'>
JSON格式不能识别单引号,全都是双引号
import json
dic = {'name': 'qiuxi', 'age': 22}
# 1. 序列化得到json_str
json_str = json.dumps(dic)
# 2. 把json_str写入文件
# 因为json表示出来的都是字符串, 所以用wt且指定编码
with open('db.json', 'wt', encoding='utf-8') as f:
f.write(json_str)
# 1和2合并一步
with open('db.json', 'wt', encoding='utf-8') as f:
json.dump(dic, f)
import json
# 1. 从文件中读取json格式
with open('db.json', 'rt', encoding='utf-8') as f:
json_str = f.read()
# 2. 将json_str转成内存中的数据类型
dic = json.loads(json_str)
print(dic)
# 1和2合并一步
with open('db.json', 'rt', encoding='utf-8') as f:
dic = json.load(f)
print(dic)
当自己手写的 json 文件时,可以到网上进行JSON格式化校验
优点:跨平台性强
缺点:只能支持 Python 部分的数据类型
xml模块:也是用于序列化的一种模块
在使用 xml 模块之前,需要先了解 XML(可扩展标记语言),也是一种通用的数据格式。
语法格式:
1、任何的起始标签都必须有一个结束标签
2、可以采用另一种简化语法,可以在一个标签中同时表示起始和结束标签。这种语法是在大于符号之前紧跟一个斜线(/),例如<百度百科词条/>,XML解析器会将其翻译成 <百度百科词条></百度百科词条>
3、标签必须按合适的顺序进行嵌套,所以结束标签必须按镜像顺序匹配起始签。这好比是将起始和结束标签看作是数学中的左右括号:在没有关闭所有的内部括号之前,是不能关闭外面的括号的。
4、所有的属性都必须有值
5、所有的属性都必须在值的周围加上双引号
标签的组成
<tagname attributename="value">text
<subtags/>
</tagname>
<标签名 属性="属性值">文本
</子标签>
</标签名>
import xml.etree.ElmentTree # 表示节点树
<studentinfo>
<stu age="20" name="张三">
<phone name="华为">这是华为手机</phone>
<computer name="Mac">14888</computer>
</stu>
<stu age="22" name="李四">
<phone name="华为">这是华为手机</phone>
<computer name="联想">4888</computer>
</stu>
</studentinfo>
标签的三个特征:标签名tag、标签属性attrib、标签的文本内容text
import xml.etree.ElementTree as ET
# 解析d.xml
tree = ET.parse('d.xml')
print(tree)
# 获取根标签
rootTree = tree.getroot()
# 第一种获取标签的方式
# iter用于在全文范围获取标签
for item in rootTree.iter('phone'):
print(item.tag) # 标签名
print(item.attrib) # 标签的属性
print(item.text) # 文本内容
# 第二种获取标签的方式
# find用于从根标签的子标签中查找一个名为stu的标签, 如果有多个, 找到的是第一个
print(rootTree.find('stu').attrib)
# 第三种获取标签的方式
# findall用于从同级标签中查找所有名为phone的标签
print(rootTree.findall('phone'))
# 1、查
# 遍历整个文档
for stu in rootTree:
for item in stu:
print(item.tag)
print(item.attrib)
print(item.text)
# 2、改
for phone in rootTree.iter('phone'):
print(phone.tag)
phone.attrib = {'name': '华为'}
phone.text = '这是华为手机'
tree.write('d.xml',encoding='utf-8')
# 3、增
for stu in rootTree:
computer = stu.find('computer')
if int(computer.text) > 5000:
print('价钱大于5000的电脑的使用者', stu.attrib)
tag = ET.Element('qiuxi')
tag.attrib = {'hobby': 'music'}
tag.text = '喜欢音乐'
stu.append(tag)
tree.write('d.xml', encoding='utf-8')
# 4、删
for stu in rootTree:
tag = stu.find('qiuxi')
if tag is not None:
print("========")
stu.remove(tag)
tree.write('d.xml', encoding='utf-8')
configparser模块:用于解析配置文件的模块
配置文件即包含配置程序信息的文件,一些需要修改但不经常修改的信息,例如数据文件的路径等
配置文件中只有两种内容,一种是 section 分区,另一种是 option 选项,就是一个 key=value 形式
使用最多的是 get ,用来从配置文件获取一个配置选项
# 路径的相关配置
[path]
db_path = C://myfile/test.txt
# 用户相关的配置
[user]
name = qiuxi
age = 22
import configparser
# 创建一个解析器
config = configparser.ConfigParser()
# 读取并解析test.cfg
config.read('test.cfg', encoding='utf-8')
# 获取需要的信息
print(config.sections()) # 获取分区
print(config.options('user')) # 获取选项
# 获取某个选项的值
print(config.get('path', 'db_path'))
print(config.get('user', 'age'))
# get返回的都是字符串类型, 如果需要转换类型, 直接使用get+对应的类型
print(type(config.getint("user","age")))
# 是否有某个分区
print(config.has_section('user'))
# 是否有某个选项
print(config.has_option('user', 'name'))
# 一些不太常用的操作
# 添加
config.add_section("server")
config.set("server","url","192.168.1.2")
# 删除
config.remove_option("user","age")
# 修改
config.set("server","url","192.168.1.2")
# 增删改查操作完成后写回文件中
with open("test.cfg", "wt", encoding="utf-8") as f:
config.write(f)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号