缓存
缓存知识
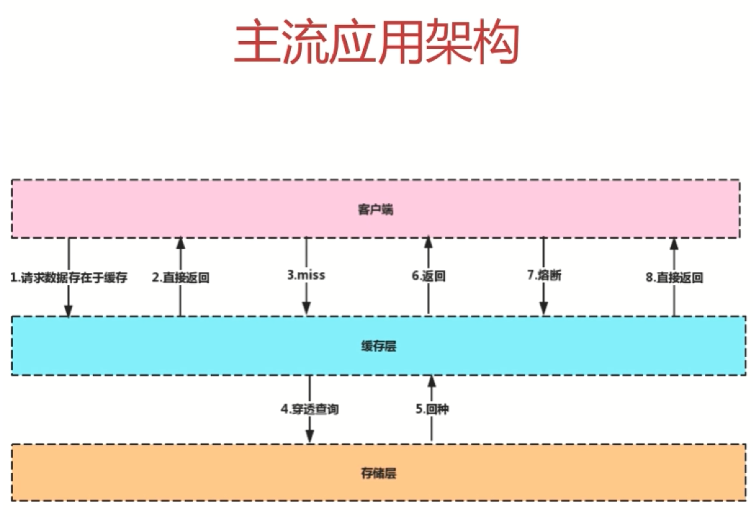
一般为了提升性能,都会在客户端和存储层之间添加一个缓存层,当客户端向后端发送请求时,会先从后端查看有没有相关的数据,如果有就将数据直接返回,这样减轻了存储层的压力,如果缓存层没有相关的数据,才会到存储层进行查询,这就是所说的穿透。穿透就是缓存里没有,穿透缓存,去访问存储层查询数据。此时,在存储层找到数据,就会将该数据回写回缓存,以便下次客户端再次请求同样的数据后,可以直接快速的从缓存层返回。
回写的过程就是所谓的回种,回种完成之后,就将结果返回至客户端,完成一次请求响应的操作。
这个架构还能实现熔断机制,即当发现存储层挂掉,无法提供服务的时候,可以让客户端的请求直接到缓存层上,不管有没有获取到数据,都直接返回,这样就能在有损的情况下对外提供服务。
缓存中间件:Memcache
Memcache 的优点在于简单易用,它和哈希非常类似,是可以通过Hash这个数据结构来实现的。Memcache 它支持简单的数据类型,但是它也有一些缺点,比如说它不支持数据持久化存储。一旦服务器宕机,数据无法保存下来,同时它也不支持 Mysql 一样的主从同步,也不支持分片,即所谓的 Sharding,Sharding 指的是将整个数据库打碎的过程,可以简单理解为将大数据分布到多个物理节点的一个分区方案
缓存中间件:Redis
对于 redis 来说,它的数据类型比较丰富,支持set、list等类型,同时还支持数据磁盘持久化存储,支持主从同步,支持 Sharding(redis 3.0之后)
其实,对于二者的选择,对于有持久化需求,或者对数据结构和处理有高级要求的应用,应该选择 redis,其他简单的 key-value 的存储,选择 Memcache,根据业务特性,选择适合的数据库缓存技术
为什么Redis能这么快
redis 的性能很高,官方提供的数据可达到 10w+ 的 QPS,QPS 即 query per second,每秒内查询的次数。那为什么这么快,首先它是基于内存的,绝大部分请求时纯粹的内存操作,执行效率高,redis 采用的时单进程单线程模型的 key-value 数据库,由 C 语言编写,它将数据储存在内存里面,读写数据的时候都不会受到硬盘 I/O 速度的限制,所以速度极快。第二点就是它的数据结构比较简单,对数据操作也非常简单。redis 不使用表,它的数据库不会预定义或者强制去要求用户对 redis 存储的不同数据进行关联,因此性能相比关系型数据库要高出很多,它的存储结构就是键值对,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是 O(1) 。第三点就是它采用单线程,一般在面对多并发的请求的时候,首先想到的是用多个线程来处理,将 I/O 线程和业务线程分开,业务线程使用线程池来避免频繁创建和销毁线程,即便是一次请求,阻塞了也不会影响到其它请求。为什么 redis 会选择反其道而行之,准确的来说,redis 的单线程结构是指其主线程是单线程的,这里主线程包括 I/O 事件的处理,以及 I/O 对应的相关请求业务的处理,此外,主线程还负责复制协调,集群协调等等。这些除了 I/O 事件之外的逻辑,会被封装成周期性的任务,由主线程周期性的处理。正因为采用单线程的设计,对于客户端的所有读写请求,都有一个主线程串行的处理,因此,多个客户端同时对一个键进行写操作,就不会有并发的问题,避免了频繁的上下文切换和锁竞争,使得 redis 执行起来效率更高。
单线程也可以处理高并发的请求,redis 就实现了,有一点需要注意,并发并不是并行,并行意味着服务器同时能够执行几个事情,具有多个计算单元,而并发,意味着能够让一个计算单元来处理来自多个客户端的请求。redis 使用单线程和 I/O 多路复用,能大幅度的提升性能。在多核 CPU 流的今天,只用一个线程,只用一个核,会感觉很浪费?并且是不是也没法利用 CPU 的其他计算能力?redis早已对相关问题进行验证,在实际测试中,redis 的 QPS 相当高,并且在 QPS 的峰值,CPU 也并没有被跑满,只是由于网络等原因,导致并发处理量不能进一步上升,因此 CPU 并不是制约 redis 的性能瓶颈。此外,依旧可以在多核的服务器中,启动多个 redis 实例,来利用多核的特性。需要注意的是,这里一直在强调的单线程,只是在处理网络请求的时候,只有一个单线程来处理,一个正式的 redis server,在运行的时候,肯定是不止一个线程的。例如 redis 进行持久化的时候,会根据实际情况,以子进程或者子线程的方式执行。
第四点它使用的 I/O 多路复用模型,即非阻塞的 I/O。redis 是跑在单线程中的,所有的操作都是按照顺序线性执行,但是由于读写操作,等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,就会导致某一文件的 I/O 阻塞,进而导致进程无法对其他客户端提供服务。而 I/O 多路复用就是为了解决这个问题而出现的。
I/O多路复用模型
FD:File Descriptor,文件描述符。在操作系统中,一个打开的文件通过唯一的描述符进行引用,该描述符是打开文件的元数据到文件本身的映射。在 linux 系统中,文件描述符用整数表示。
传统的 I/O 阻塞模型如何工作?当使用 read 或者 write 对某一个文件描述符 FD 进行读写时,如果当前 FD 不可读或者不可写,整个 redis 服务就不会对其他的操作做出响应,导致整个服务不可用,这就是在编程中使用最多的阻塞模型。阻塞模型虽然开发中非常常见,也非常易于理解,但是它会影响其他 FD 对应的服务,所以在需要处理多个客户端任务的时候,往往都不会使用阻塞模型,此时,需要一种更高效率的模型来支撑 redis 的高并发处理,这里涉及的就是 I/O 多路复用模型。
在 I/O 多路复用模型中,最重要的函数调用就是 Select 系统调用,Select 这个方法能够同时监控多个文件描述符的可读、可写情况。当其中的某些文件描述符可读或者可写时,Select 方法就会返回可读或者可写的文件描述符个数。
与此同时,也有其他的 I/O 多路复用函数,如:poll、epoll、kqueue、evport 等,这么多的函数,redis 使用哪个呢?因为 redis 需要在不同平台上运行,同时为了最大化的提高执行效率和性能,会根据编译平台的不同,选择不同的 I/O 多路复用函数作为子模块提供给上层统一的接口。redis 会优先选择时间复杂度为 O(1) 的 I/O 多路复用函数作为底层实现。上述的这些函数,都使用了内核内部的结构,并且能够服务几十万的文件描述符,性能比 select 优秀。然而因为 select 是作为 Proxy 标准中的系统调用,在不同版本的操作系统上都会实现,所以将其作为保底方案,一旦当前环境没有上述的函数,就会选择 select 作为备选方案。由于 select 在使用时,会扫描全部监听的描述符,所以其时间复杂度较差,通常是 O(n) 。
此外,redis 服务是采用了 react 设计模式来实现文件事件处理器的。文件事件处理器使用 I/O 多路复用模块同时监听多个 FD,当 read、write 等文件事件产生时,文件事件处理器 FD 就会回调绑定的事件处理器。虽然整个文件事件处理器是在单线程上运行的,但是通过 I/O 多路复用模块的引用,实现了对多个 FD 读写的监控,提高了网络通信模型的性能,同时也可以保证整个 redis 服务实现的简单。

