



mysql学习笔记(1)
以下笔记并不系统,只是针对遇到的问题和特别的点记录一下:
数据类型:
1.mysql小数存储数据类型 有float double decimal ,前两个不属于精确类型,不推荐使用,一般生产库亦不会使用
在使用中用deciaml存储金额相关的数据.但是在计算的时候还是会存在转浮点数计算的问题,运算过程有四舍五入就会导致数据不正确的问题
decimal(M,D) D值是小数位数,插入位数不足,则补到D位小数,超过D位则会四舍五入截断,取D位;M是整数加小数部分的总长度,及插入的整数部分不能超过M-D为,否则会报超出范围的错误。
也可以使用int数据来存储金额,单位为分,就不存在四舍五入的问题
2.时间类型 datetime 在5.6之后的版本占5个字节 之前是8个字节 如果时间存了int 则需要用from_unixtime()来转化
3.varchar 和char 的区别
char定长字符串 0-255 不够则空格补全 多余截断
varchar 变长字符串 长度0-65535 不够不会补全 超过长度,会被截断,在不确定字符数时,使用varchar可以解决磁盘空间,提高存储效率 一般会多1-2字节来记录长度 以是否大于255,小于255,另一位记录null
简单表优化:
mysql的删除delete操作会导致数据碎片 因为删除不是删除真实的数据文件,只是删除数据文件的表示为,也不会整理数据文件,不会彻底释放表空间。当再次写入数据时,会直接利用被删除的区域,单页无法彻底占用
这种额外的碎片空间在数据读取的时候读写效率较低,需要优化表进行碎片整理
查看表数据文件大小: show TABLE status like "%table_name%";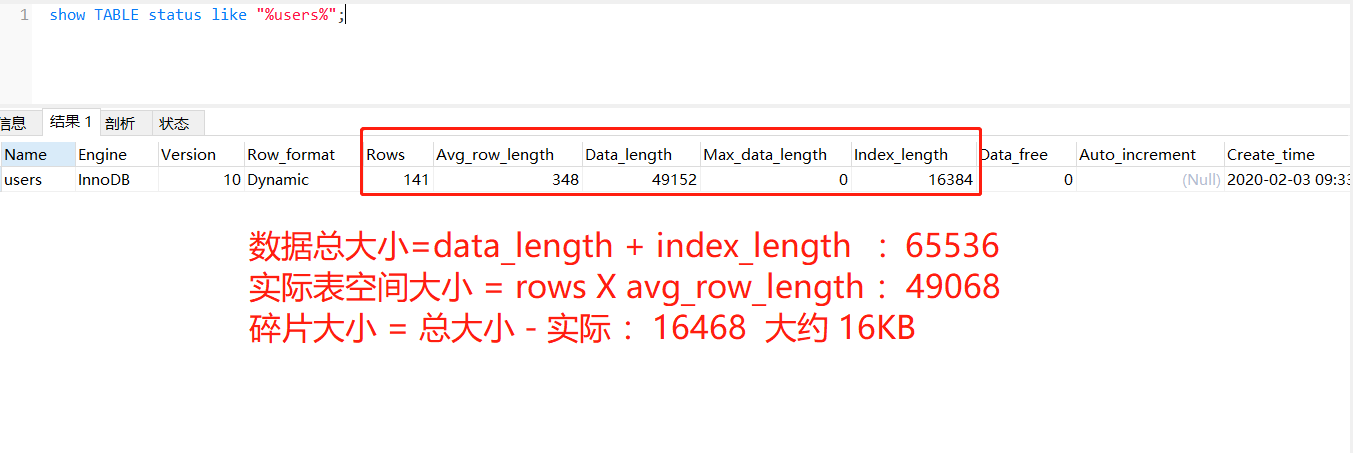
清理方法有两种 (1) 直接alter table table_name engine=innodb 但是这种操作会给表加锁,耗时较长,高峰业务不建议使用(2)备份表数据,删除表,重新导入
索引:
mysql索引是为了提高表查询效率,mysql的索引结构是B+tree 是一种多路搜索树 关于B+tree详细可以学习数据结构与算法中相关内容
创建索引 create table table_name add index index_name 或者 create index index_name on table_name
查看索引 show index from table_name
explain 查看sql语句执行计划 索引执行是否扫描全局
优化sql语句解决:不要直接就创建索引
(1):首先看表数据类型设计是否合理,有没有准守选取数据类型越简单越小原则
(2)表中的数据碎片是否整理
(3) 查看是否有创建索引,索引是否创建的合适
索引创建成功之后,查看一下执行计划,对比两次结果,查看查询效率是否提高
经常查询的列,经常用于表连接的列,经常分组的列可以考虑创建索引
各种类型的索引:
主键索引:主键值唯一 不能包含null
唯一索引:不允许有重复的值 但是允许有null值 创建语句:alter table table_name add unique (colume);
覆盖索引:mysql只需要通过索引就可以返回查询的数据,而不用查到索引之后再去回表查询数据,减少大量I/O操作
例如:select id from t where name="aa" id为主键,name为普通索引 这条语句相当于(name, id)索引 即使用覆盖索引 如果使用覆盖索引,select一定要列出所有需要的列,不要写select *
联合索引: 在表中创建2个及以上的索引,利用附加列减小索引范围 创建语法 create index index_c1_c2 on table_name (c1,c2) 注意最左端原则
在生产环境中,尽量将判断做在程序端,不要让数据库做各种运算,避免sql中出现or
总结索引:
优点:提高数据检索,聚合函数,排序的效率 同时使用覆盖索引避免回表
不要创建索引的情况:选择性低(状态,性别),很少查询的列,大数据类型字段
使用不到索引的情况:
a: 扫描行记录超过30%,优化器就不会走索引变成全表扫描;
b: 在联合索引时,第一个不是最左索引列;
c:在联合索引中第一个使用范围查询(< <= between and)
d: 两个索引 一个检索 一个排序 这种情况下只能使用一个索引 可以考虑联合索引
e: 查询字段有索引,但是使用了函数运算

