Shell文本处理 - 匹配与编辑
正则表达式
|
符号 |
含义 |
|
. |
匹配任意ASCII中任意单个字符,或是字母,或是数字 |
|
^ |
匹配行首 |
|
$ |
匹配行尾 |
|
* |
匹配任意字符或前一个的一次或多次重复 |
|
\ |
转义,被转义的有$ . ‘ “ * [ ] ^ \ ( ) | + ? |
|
[…] [-] |
匹配一个范围或集合 |
|
\{\} |
匹配n次:\{n\},最少n次:\{n,\},m到n次:\{m,n\}, |
|
+ |
仅用于awk,标识匹配一个或多个 |
|
? |
仅用于awk,匹配0次或1次 |
grep
先给出示例文件data.f的内容
48 Dec 3BC1977 LPSX 68.00 LVX2A 138 483 Sept 5AP1996 USP 65.00 LVX2C 189 47 Oct 3ZL1998 LPSX 43.00 KVM9D 512 219 dec 2CC1999 CAD 23.00 PLV2C 68 484 nov 7PL1996 CAD 49.00 PLV2C 234 483 may 5PA1998 USP 37.00 KVM9D 644 216 sept 3ZL1998 USP 86.00 KVM9E 234
grep一般匹配
一般匹配通常需要将匹配的模式使用双引号括起来。
grep的一般格式为:grep [选项] 基本正则表达式 [文件]
注意对输入的参数字符串使用双引号
grep的选项:
-c 只输出匹配行的数量
-i 不区分大小写(只适用于单字符)
-h 查询多文件时,不显示文件名
-l 查询多文件时,只输出包含匹配字符的文件名
-n 显示匹配行的行号
-s 不显示不存在或无匹配文本的错误信息
-v 显示不包含匹配文本的所有行
查询多个文件:可以使用文件占位符查询多个文件,也可以将多个文件列出,如:
grep "45" data*.f
grep "45" data1.f data2.f
全字匹配:在匹配的字符后边加上\>
grep "45\>" data.f
grep使用正则匹配
为了防止shell的替换等其他行为发生,使用时通常使用单引号。
模式范围:grep '48[43]' data.f,匹配484/483
不匹配行首:grep '^[^48]' data.f
先匹配月份,再匹配模式:grep '[Ss]ept' data.f | grep 443
空行:grep '^$' data.f
扩展模式:
使用-E参数,这一扩展允许使用扩展模式匹配
匹配219或者216:grep -E '219|216' data.f
类名
|
类名 |
等价的正则 |
|
类名 |
等价的正则 |
|
[[:upper:]] |
[A-Z] |
|
[[:alnum:]] |
[0-9a-zA-Z] |
|
[[:lower:]] |
[a-z] |
|
[[:space:]] |
空格或tab键 |
|
[[:digit:]] |
[0-9] |
|
[[:alpha:]] |
[a-zA-Z] |
grep '[[:alpha:]]*' data.f
系统grep命令
目录:ls -l grep '^d'
passwd文件:grep "angel" /etc/passed
查看DNS服务进程(通常为named):ps | grep "named"
egrep
expression或extended grep,接受所有的正则表达式,特点为:
- 文件作为查询的正则字符串。egrep -f grepstrings data.f
- 使用 | 符号,表示匹配两边之一
- 使用 ^ 符号,表示不匹配到。
AWK进行文本过滤
Usage: awk [POSIX or GNU style options] -f progfile file ...
Usage: awk [POSIX or GNU style options] 'program' file ...
其中progfile中或者'program'是真正的AWK命令,最后的file是输入文件(s)。
常用的参数是-F field-separator,指定文件分隔符,默认为空白字符。对于passed之类的使用冒号分割的,则使用-F:参数,表示冒号为列分割。
同样可以使得同sh脚本一样,在首行指定#/bin/awk,可以使脚本文件使用AWK进行执行。
awk脚本
awk脚本由各种操作和模式组成。
awk将每次读取一行,然后使用分隔符将每一行分割成多个域。
awk语句都由模式和动作组成,模式决定动作的触发条件,如果省略模式部分,动作将时刻保持执行。
awk模式,包括两个特殊字段,BEGIN和END。BEGIN使用在浏览文本动作前,之后文本浏览动作开始执行。END使用在浏览文本动作之后,打印输出文本总数和结尾状态标识。如不特殊指明,总是匹配或打印行数。
awk动作,在大括号{}内指明,多数用来打印,还有诸如if和循环语句等。如不特殊指明,将打印所有浏览出来的记录。
域:awk执行动作时,将域标记为$1 $2 $3 ...,其中$0标识所有域。
记录:每一行就是一个记录
提取文件中的每一列
awk '{print $0}' data.f
awk '{print $3}' data.f

添加文件头尾
awk 'BEGIN {print "Month\tPrice\n------------------------"} {print $2"\t"$5} END {print "------------------\ntip: end of file"}' data.f

awk中的正则表达式
awk中使用正则时,是使用//括起来。如:/wang*/
条件操作符
|
操作符 |
描述 |
操作符 |
描述 |
|
|
< |
小于 |
>= |
大于等于 |
|
|
<= |
小于等于 |
~ |
匹配正则表达式 |
|
|
== |
等于 |
!~ |
不匹配正则表达式 |
|
|
!= |
不等于 |
&& | 且 | |
|
|| |
或 |
! | 非 |
打印符合条件的行的部分列: awk '{if($4~/LPSX/) print $2"\t"$4"\t"$5}' data.f
![]()
打印不符合条件的行的部分列: awk '{if($4!~/LPSX/) print $2"\t"$4"\t"$5}' data.f

打印第一列小于第七列的:awk '{if($1 < $7) print $1"\t"$4"\t"$7}' data.f

awk内置变量
ARGC 命令行参数个数
ARGV 命令行参数排列
ENVIRON 支持队列中系统环境变量的使用
FILENAME awk浏览的文件名
FNR 浏览文件的记录数
FS 设置输入域分隔符,等价于命令行-F选项
NF 浏览记录的域个数
NR 已读的记录数
OFS 输出域分隔符
ORS 输出记录分隔符
RS 控制记录分隔符
打印记录号,域个数,最后打印文件名称
awk '{print NF"\t"NR"\t"$0} END {print FILENAME}' data.f

awk操作符
赋值操作:=、+=、*=、/=、%=、^=
条件表达式:?
或且非:||、&&、!
匹配:~、!~
关系:<、<=、>、>=、!=、==
算术:+、-、*、/、%、^
前后缀:++、--
使用变量:awk '{name=$4; price=$5;print name"\t"price} ' data.f

内置字符串函数
|
gsub(r,s) |
在整个$0中用s替代r |
|
gsub(r,s,t) |
在整个t中用s替代r |
|
index(s,t) |
返回s中字符串t的第一位置 |
|
length(s) |
返回s长度 |
|
match(s,r) |
测试s是否包含匹配r的字符串 |
|
split(s,a,fs) |
在fs上将s分成序列a |
|
sprint(fmt,exp) |
返回经fmt格式化后的exp |
|
sub(r,s) |
用$0中最左边最长的子串代替s |
|
substr(s,p) |
返回字符串s中从p开始的后缀部分 |
|
substr(s,p,n) |
返回字符串s中从p开始长度为n的后缀部分 |
返回每行的长度:awk '{print $0"\t"length($0)} ' data.f

awk使用printf修饰输出格式
|
修饰符 |
含义 |
|
- |
左对齐 |
|
Width |
域的步长,用0表示0步长 |
|
.prec |
最大字符串长度,或小数点右边的位数 |
|
%c |
ASCII字符 |
|
%d |
整数 |
|
%e |
浮点数,科学记数法 |
|
%f |
浮点数,例如(123.44) |
|
%g |
awk决定使用哪种浮点数转换e或者f |
|
%o |
八进制数 |
注意printf不会自动输出换行。
对ASCII的65输出字符A:awk 'BEGIN {printf "%c\n",65}'
固定列宽输出:awk '{printf "%-15s %s\n",$1,$3}' data.f

awk脚本文件
如下是一个脚本文件
第一行表示执行脚本的命令和参数,!/bin/awk -f
执行时,键入脚本名称和输入文件即可得到输出
awk数组
使用实例:
- 将文本划分到数组:awk 'BEGIN {print split("123:456:789",array,":")}'
得到的数组为:array[1]="123"等。 - 循环:For (element in array) print array[element]
awk执行Shell
awk 'BEGIN{cmd="echo shell_cmd"; system(cmd); close(cmd);}'
awk 'BEGIN{cmd="echo shell_cmd"; cmd | getline output; close(cmd); print output}'
sed
sed [选项] sed命令 输入文件
sed [选项] -f sed脚本文件 输入文件
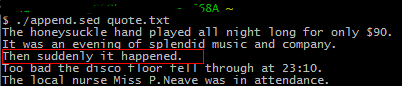
给出一个文本的例子quota.txt:
The honeysuckle hand played all night long for only $90.
It was an evening of splendid music and company.
Too bad the disco floor fell through at 23:10.
The local nurse Miss P.Neave was in attendance.
选项包括:
- n,不打印所编辑的行到标准输出
- c,下一命令是编辑命令,如果只有一条sed命令,则不必须指定
- f,指定sed脚本文件
定位到文本所在的行:
|
x |
x为一行号,如1,$表示最后一行 |
|
x,y |
表示行号范围从x到y,如2,5表示从第2行到第5行 |
|
/pattern/ |
查询包含模式的行。例如/disk/或/[a-z]/ |
|
/pattern/pattern/ |
查询包含两个模式的行。例如/disk/disks/ |
|
/pattern/,x |
在给定行号上查询包含模式的行。如/ribbon/,3 |
|
x,/pattern/ |
通过行号和模式查询匹配行。3./vdu/ |
|
x,y! |
查询不包含指定行号x和y的行。1,2! |
基本的sed编辑命令
|
p |
打印匹配行 |
|
= |
显示文件行号 |
|
a\ |
在定位行号后附加新文本信息 |
|
i\ |
在定位行号前插入新文本信息 |
|
d |
删除定位行 |
|
c\ |
用新文本替换定位文本 |
|
s |
使用替换模式替换相应模式 |
|
r |
从另一个文件中读文本 |
|
w |
写文本到一个文件 |
|
q |
第一个模式匹配完成后推出或立即推出 |
|
l |
显示与八进制ASCII代码等价的控制字符 |
|
{} |
在定位行执行的命令组 |
|
n |
从另一个文件中读文本下一行,并附加在下一行 |
|
g |
将模式2粘贴到/patternn/ |
|
y |
传送字符 |
|
n |
延续到下一输入行;允许跨行的模式匹配语句 |
使用示例
- 显示指定行(由于默认会打印所有编辑的行到输出,所以使用n参数):sed -n '2p' quote.txt
- 打印指定范围的行:sed -n '1,3p' quote.txt
- 打印符合模式的行:sed -n '/Neave/'p quote.txt
- 混合行号与模式:sed -n '4,/Neave/'p quote.txt
- 匹配元字符,使用转义:sed -n '/\$/'p quote.txt
- 打印行号:sed -n '/music/=' quote.txt
如果不加-n,则会先打印编辑的行,再打印匹配到行的行号。 - 替换命令:sed '1,5s/night/NIGHT/' quote.txt
替换1到5行中第一次出现的neight成为NIGHT
替换还能跟gpwn四个选项中的一个。g替换所有/默认替换一次;p打印所有输出结果;w输出到一个文件,需要跟输出文件参数(注意同属于sed命令这个参数)。
脚本文件的编写
如下脚本文件,对给的示例数据执行:
#!/bin/sed -f /company/ a\ Then suddenly it happened.
执行后的结果为:
shuf
随机对输入行重新排列


 浙公网安备 33010602011771号
浙公网安备 33010602011771号