
HOWTO re
\w 字母数字字符 [a-z A-Z 0-9_]
\W 非字母数组字符 [^a-z-A-Z 0-9_]
\d 十进制数字 [0-9]
\D 非数字字符 [^0-9]
\s 空白字符 [\t\n\r\f\v]
\S 非空白字符 [^\t\n\r\f\v]
‘.’ 匹配除了换行符之外的所有字符,在dotall模式下,匹配所有字符。
* 匹配前面的字符零次或多次。
+ 匹配前面的字符至少一次。
? 匹配前面的字符零次或者一次。
{m,n} 匹配前面的字符m-n次。可以缺省m,n,m缺省时为0,n缺省时为无穷大
re.compile(‘RE’,re.IGNORECASE) re.IGNORECASE可以缺省
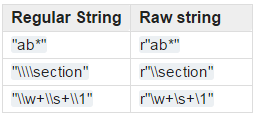

match:在字符串的开始匹配,返回字符
search:在整个字符串中匹配,返回位置
若都没有匹配成功就返回None。
findall:在所有子字符串中匹配,返回list
finditer:在所有子字符串中匹配,返回iterator

group():返回匹配成功的字符串
start() 返回匹配成功的第一个位置
end() 返回匹配成功的最后一个位置
span() 返回匹配成功的位置的元组
因为match之匹配字符串的开始,所以start总是返回0.
Flags:
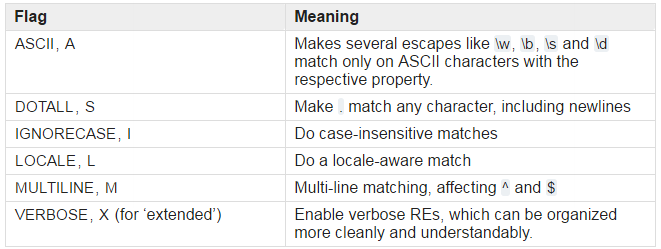
I:不分大小写。
L:\W\w\B\b 可以匹配法文之类的非英文字符作为英文字符,但是会减慢速度
M:^ $在默认模式只能匹配字符串的begining和end。在M下,可以匹配所有行的begining和end。
S:. 在默认模式下匹配所有字符除了换行符。在M下,可以匹配所有行的begining和end。
A: \w\W\b\B\s\S 可以匹配ASCII而不是Unicode
X: 默认省略RE表达式中的空格,除了空格表达式。
To match a literal '|', use \|, or enclose it inside a character class, as in [|].
把元字符放在character class里面就不用\来表示。
\A : 无论在默认模式还是M模式中,都是匹配字符串的begining。
\Z : 无论在默认模式还是M模式中,都是匹配字符串中的end。
\b : 单词边界,表示单词的begining或end,单词是数字和字母的序列,以数字或字母开始,以数字或字母接结束。
\B : 意思跟b相反,非边界。

RE的split和STR的split不一样。

