


JUC面试点汇总
JUC面试点汇总
我们会在这里介绍我所涉及到的JUC相关的面试点内容,本篇内容持续更新
我们会介绍下述JUC的相关面试点:
- 线程状态
- 线程池
- Wait和Sleep
- Synchronized和Lock
- Volatile线程安全
- 悲观锁和乐观锁
- Hashtable和ConcurrentHashMap
- ThreadLocal
线程状态
下面我们来介绍我们面试中经常考察的两种线程状态分类
六种线程状态
Java虚拟机将线程状态划分为六种:
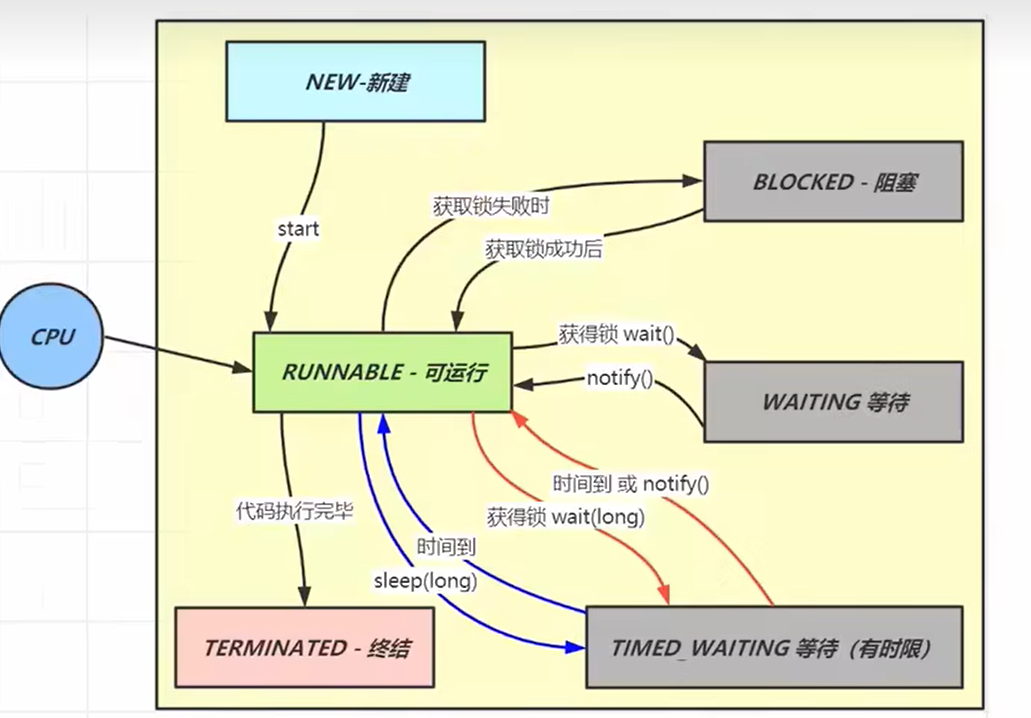
我们来简单介绍一下:
- NEW 线程刚被创建,但是还没有调用 start() 方法
- RUNNABLE 当调用了 start() 方法之后
- 注意,Java API 层面的 RUNNABLE 状态涵盖了操作系统层面的可运行状态运行状态和阻塞状态
- BLOCKED , WAITING , TIMED_WAITING 都是 Java API 层面对阻塞状态的细分
- BLOCKED 表示被锁拦截下的阻塞
- WAITING 表示自己进行wait等待时的阻塞
- TIMED_WAITING 表示进行有时间限制的阻塞
- TERMINATED 当线程代码运行结束
五种线程状态
操作系统将线程分为五种状态:
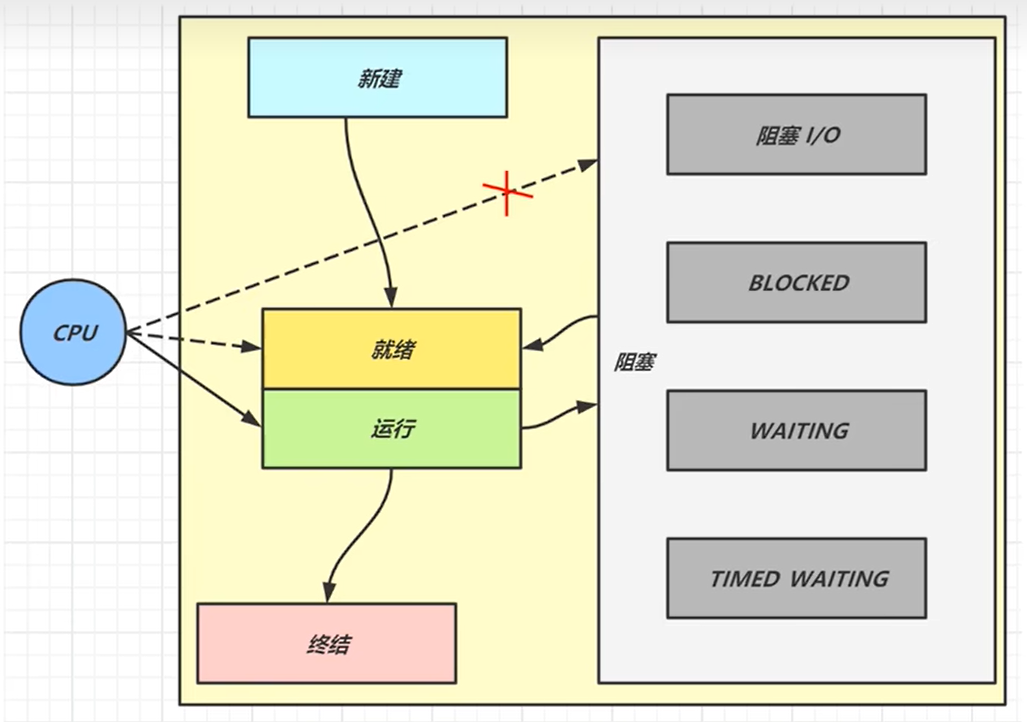
我们来简单介绍一下:
- 【初始状态】仅是在语言层面创建了线程对象,还未与操作系统线程关联
- 【可运行状态】(就绪状态)指该线程已经被创建(与操作系统线程关联),可以由 CPU 调度执行
- 【运行状态】指获取了 CPU 时间片运行中的状态
- 当 CPU 时间片用完,会从【运行状态】转换至【可运行状态】,会导致线程的上下文切换
- 【阻塞状态】
- 如果调用了阻塞 API,如 BIO 读写文件,这时该线程实际不会用到 CPU,会导致线程上下文切换,进入 【阻塞状态】
- 等 BIO 操作完毕,会由操作系统唤醒阻塞的线程,转换至【可运行状态】
- 与【可运行状态】的区别是,对【阻塞状态】的线程来说只要它们一直不唤醒,调度器就一直不会考虑 调度它们
- 【终止状态】表示线程已经执行完毕,生命周期已经结束,不会再转换为其它状态
线程池
下面我们来介绍线程池中常考的一些知识点
线程池工作流程图
首先我们给出线程池的工作流程图以及相关参数:
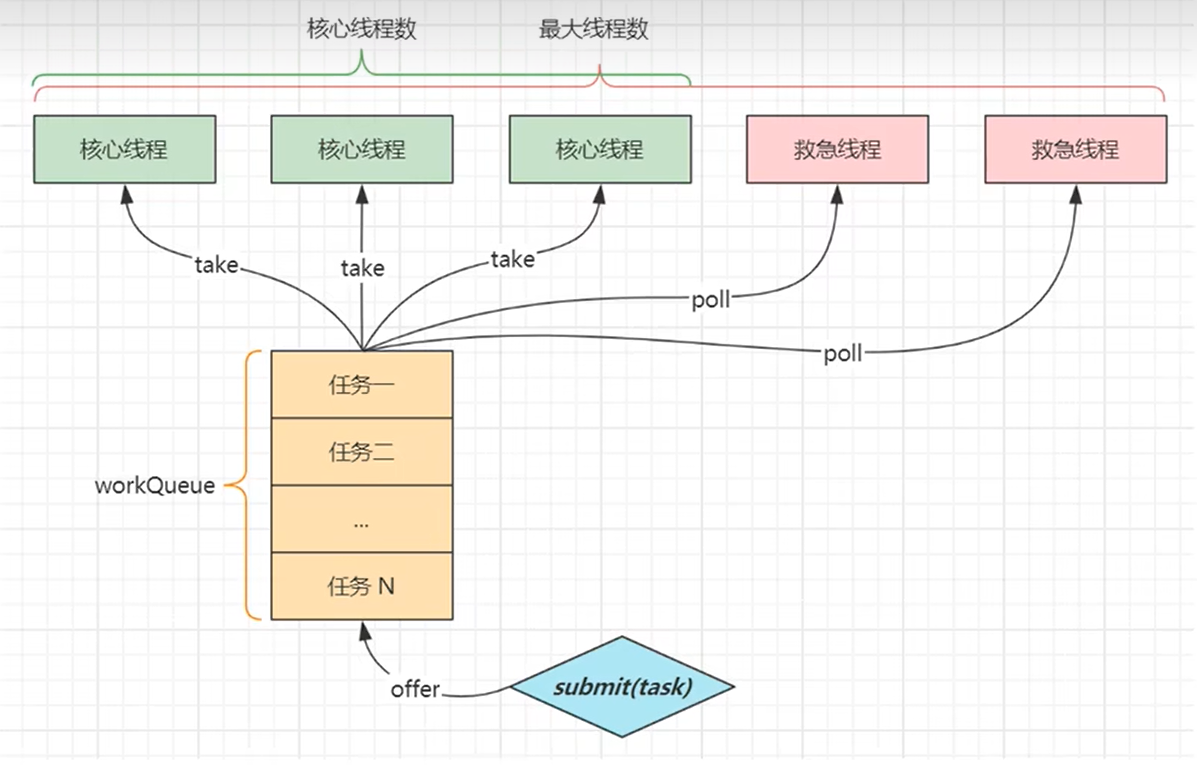
我们对上面元素进行简单介绍:
- submit(task):负责分配任务,将任务传入WorkQueue
- WorkQueue:工作等待队列,用于存放未被执行的任务,通常具有任务个数限制,防止内存过满
- 核心线程:一直处于运行状态的线程,不断从WorkQueue中取得任务并执行
- 救济线程:只有当核心线程全部运行且WorkQueue装载满员并且有submit继续传入任务时开启,在一定时间没有任务接收后结束
线程池工作参数
我们给出线程池工作的基本参数:
/*corePoolSize核心线程数目*/
用于控制核心线程的个数
/*maximumPoolSize最大线程数目*/
表示核心线程和救急线程的最大个数,用该值减去corePoolSize核心线程数目就是救急线程个数
/*keepAliveTime生存时间*/
针对救急线程,当救急线程在该时间段没有接收新任务,就结束该线程
/*unit时间单位*/
配合keepAliveTime生存时间使用的时间单位
/*workQueue阻塞队列*/
用于存放处于阻塞状态的任务
/*threadFactory线程工厂*/
用于生成线程名称
/*handler拒绝策略*/
当线程均处于运行状态,workQueue满员,且有新任务进入时,handler负责处理新进入的线程
- AbortPolicy 让调用者抛出 RejectedExecutionException 异常,这是默认策略
- CallerRunsPolicy 让调用者运行任务
- DiscardPolicy 放弃本次任务
- DiscardOldestPolicy 放弃队列中最早的任务,本任务取而代之
- Dubbo 的实现,在抛出 RejectedExecutionException 异常之前会记录日志,并 dump 线程栈信息,方 便定位问题
- Netty 的实现,是创建一个新线程来执行任务
- ActiveMQ 的实现,带超时等待(60s)尝试放入队列,类似我们之前自定义的拒绝策略
- PinPoint 的实现,它使用了一个拒绝策略链,会逐一尝试策略链中每种拒绝策略
线程池构建代码
我们直接给出线程池构建代码,了解即可:
/*线程池构造:我之前有线程池专门的文章,可以深入了解*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
Wait和Sleep
我们来介绍一下wait和sleep的相关面试点
Wait和Sleep区别以及共同点
我们给出wait和sleep的区别以及共同点:
/*共同点*/
wait(),wait(long),sleep(long) 都会导致阻塞,将当前线程暂时放弃CPU使用权
/*不同点*/
// 方法归属类不同
wait 属于 Object实体类
sleep 属于 Thread线程类
// 醒来时机不同
wait(): 只有当notify唤醒时才会醒来
wait(long): 当时间结束,或者notify唤醒就会醒来
sleep(long): 当时间结束才会醒来
注意:都可以被打断唤醒!
// 锁性质不同
1.wait必须配合锁一同使用,且只有锁对象调用Lock.lock;sleep在任何时间段都可以使用
2.wait在lock时会解除当前锁的限制;sleep若在锁中不会解除当前锁的限制
Synchronized和Lock
我们来介绍一下Synchronized和Lock的相关面试点
Synchronized和Lock区别以及共同点
我们会从三个层面讲解两者的区别以及共同点:
/*语法层面*/
// 所属类
synchronized:关键字,属于JVM,用C++语言实现
Lock:接口,属于JDK,用Java语言实现
// 锁实现
synchronized:在结束同步代码块后自动释放锁
Lock:在结束代码块后,需要手动unlock释放锁
/*功能层面*/
// 相同点
均属于悲观锁,具备互斥,同步,锁重入功能
// 不同点
Lock提供了synchronized所不具备的功能:获得等待状态,公平锁,可打断,可超时,多条件变量
Lock提供了多场景Lock:ReentrantLock,ReentrantReadWriteLock
/*性能方面*/
// 性能差距
synchronized:在无竞争情况下,存在轻量级锁,偏向锁,性能较高
Lock:在竞争激烈的情况下,性能更好
相关知识点补充
我们来补充上述所讲述的部分知识点:
/*知识点补充*/
// Lock正常使用
owner:正在运行程序,存有status,表示几重锁,当锁重入时,status++;解除锁时,status--;当status==0,释放锁
blocked queue:阻塞队列
waiting queue:等待队列
// 公平锁和非公平锁
公平锁:所有任务在进入时均放于阻塞队列按顺序排序并执行
非公平锁:当owner释放锁后,新加入的任务可以和阻塞队列的任务处于同一级竞争锁
// 多条件变量
条件变量创建:Condition c1 = Lock.newCondition("c1");
条件变量使用:c1.await();
条件变量唤醒:c1.signal();
条件变量唤醒:c1.signalAll();
必须处于owner才能使用await,唤醒后放于Blocked Queue尾部等待
Volatile线程安全
我们来介绍一下Volatile的线程安全相关问题
Volatile线程安全
我们首先要知道线程安全主要从三方面解释:
/*可见性*/
当前线程对数值的修改是否对其他线程可见?
问题产生原因:
CPU和内存之间还有一层缓存区,当使用数据较多时,会直接将内存的数据放入缓存区,然后直接从缓存区调入数据
这时倘若另一个线程修改了内存中的数据,但是原线程仍旧从自己的缓存区读取数据,就会导致数据不可见
/*有序性*/
当前线程内的代码是否按照编写顺序执行?
问题产生原因:
JVM存在自动编写机制,当出现同级别的代码时,JVM会自动优化代码顺序,加快速度,可能导致代码执行顺序错乱
/*原子性*/
当前线程内的代码是否为一次执行?
问题产生原因:
线程是由CPU调度使用的,倘若线程调度到达指定时间片,可能就会导致线程内代码未完成执行而被其他线程使用的情况
然后我们需要知道Volatile对这三种特性的可控度:
/*可见性*/
Volatile可以保证数据的可见性
Volatile会使该属性的每次读取都默认从内存中读取(该属性不会被存放于缓冲区)
/*有序性*/
Volatile可以保证数据的有序性
Volatile存在写屏障和读屏障
写屏障出现在属性输入之后,在写屏障之前的代码顺序不会变更
读屏障出现在属性读取之前,在读屏障之后的代码顺序不会变更
/*原子性*/
Volatile无法保证数据的原子性!
悲观锁和乐观锁
我们来介绍一下悲观锁和乐观锁的面试点
悲观锁和乐观锁区别
我们来介绍一下悲观锁和乐观锁的区别:
/*悲观锁*/
代表:
Synchronized
Lock
特点:
1.核心思想:当前线程占用锁后,才能操作共享数据,只有当当前线程结束操作后,其他线程才能竞争
2.线程的运行与阻塞都会导致上下文切换,频繁的上下文切换会导致CPU速度降低
3.悲观锁大部分都存在自旋现象,在获得锁时会多次尝试来减少上下文切换次数
/*乐观锁*/
代表:
Atomic系列
AtomicInteger
特点:
1.核心思想:所有数据都可以操作共享数据,但只有一个线程可以修改数据,其他线程如果修改失败就会不断尝试
2.由于线程一直运行,不需要阻塞,不涉及上下文切换
3.由于线程一直运行,需要一个CPU保证其线程的活动,否则单CPU下乐观锁属于负增益,一般线程数不会超过CPU个数
悲观锁乐观锁代码比较
我们分别给出悲观锁和乐观锁的代码展示:
/*乐观锁底层实现*/
// 乐观锁底层其实是采用Unsafe类来完成的
// 1.获得该类的属性对于类的偏移量(第一个参数:类名称.class,第二个参数:类属性名称)
Long BALANCE = unsafe.objectFieldOffset(Account.class,"blance");
// 2.采用unsafe的原子比较赋值方法(第一个参数:类对象,第二个参数:属性偏移量,第三个参数:修改前数值,第四个参数:修改后数值)
// 如果再次检测时,该值和oldInt相同,就将其修改为newInt,否则不作为
unsafe.compareAndSetInt(account,BALANCE,oldInt,newInt);
/*乐观锁代码*/
Thread t1 = new Thread(() -> {
// 乐观锁需要不断尝试
while(true){
// 每次获得当前值
int oldInt = account.getBalance;
// 我们假设做++操作
int newInt = oldInt + 1;
// 然后启动unsafe的比较赋值(compareAndSetInt会返回一个布尔值表示是否成功),若成功退出循环
if(unsafe.compareAndSetInt(account,BALANCE,oldInt,newInt)){
break;
}
}
}).start;
/*悲观锁代码*/
Thread t2 = new Thread(() -> {
// 悲观锁就是直接采用锁处理即可
synchronized(Account.class){
int oldInt = account.getBalance;
int newInt = oldInt + 1;
account.setBalance(newInt);
}
})
Hashtable和ConcurrentHashmap
我们来介绍一下Hashtable和ConcurrentHashmap的面试点
Hashtable和ConcurrentHashmap区别
我们来介绍一下Hashtable和ConcurrentHashmap区别:
/*线程安全?*/
Hashtable和ConcurrentHashMap均属于线程安全类的Map集合
/*并发度*/
Hashtable:只存在一个锁,所有索引点的操作均在一个锁上,并发度低
1.7ConcurrentHashMap:底层由数组+Segment+链表结构,每个Segment对应一把锁,不同Segment不会造成锁冲突
1.8ConcurrentHashMap:底层由数组+链表结构,每个链表头对应一把锁,相当于每个索引点对应一把锁,只有同一条链表会产生锁冲突
Hashtable
我们来介绍一下Hashtable的基本面试点:
/*基本问题*/
初始capacity:11
扩容:超过0.75
索引:hashcode即可,(因为以质数为主,分散性较好,不需要二次hash)
1.7ConcurrentHashMap
我们来介绍一下JDK1.7版本的ConcurrentHashMap:
/*基本组成*/
capacity:总共的索引头
factor:超过0.75
clevel:并发度,也就是Segment的个数
每个Segment算是一个大桶,然后大桶中会根据capacity/clevel算出小桶
举例:
capacity:32
factor:0.75
clevel:8
这时存在8个Segment,每个Segment中存有四个初始小桶
不同Segment拥有不同锁,不同Segment独自占有并发性
基本形式如下:
---- ---- ---- ---- ---- ---- ---- ----
/*put操作*/
1.hashCode
2.hash
3.根据hash值二进制的前(clevel二进制为2的n次方)n位的数值来判断放在哪个大桶
4.根据hash值二进制的后(小桶大小二进制为2的n次方)n为的数值来判断放哪个大桶
举例:
capacity:32
factor:0.75
clevel:8
首先clevel的为2的3次方,小桶大小为2的2次方
假设我们的hash值二进制为 110 1101 0110
这时我们的大桶取前三位:110 -> 6 -> Segment[6]
这时我们的小桶取后两位: 10 -> 2 -> Segment[6][2]
也就是第七个桶的第三个位置
/*扩容*/
扩容仅针对每个Segment单独扩容,最开始的桶大小为capacity/clevel,当超过factor,就会自动扩大一倍,单独计算
Segment[0]的扩容不会影响到其他Segment的桶大小
/*Segment[0]*/
Segment[0]会自动初始化小桶,其他Segment只有在put第一个数时初始化
因为Segment[0]类似于一个初始模板,其他Segment会根据Segment[0]的大小来构造,节省空间(懒汉式构建)
1.8ConcurrentHashMap
我们来介绍一下JDK1.8版本的ConcurrentHashMap:
/*基本知识点*/
1.8版本的ConcurrentHashMap只包含 数组 + 链表 结构
属于懒汉式初始化,我们new一个ConcurrentHashMap并不会产生数组,只有开始put时才会初始化
capacity:16
注意:这里的capacity并不是初始桶大小,而是我们需要插入的数的数量,系统会根据我们书写的capacity更换桶大小
例如我们写15,系统会为我们分配一个大小为32的桶
factor:达到0.75
/*并发依据*/
1.8ConcurrentHashMap根据链表头分配不同的锁,也就是如果不是在同一索引下,均可以正常运行
/*扩容操作*/
扩容是ConcurrentHashMap的考点之一
ConcurrenthashMap扩容是从后往前移动数据,每次移动完成该索引点数据,就为其标记为ForwardingNode用来表示已移动
ConcurrentHashMap扩容不再是将原数据next更换,而是直接在新数组上创建新数据,将数据拷贝过去,防止并发操作时出现问题
/*扩容细节*/
当一个线程t1正在进行扩容,另一个线程t2参与该HashMap各项操作:
1.get操作:
I.如果查询的该索引属于ForwardingNode,就去新的数组中查找
II.如果查询的索引不属于ForwardingNode,就直接查找
2.put操作:
I.如果该索引不属于ForwardingNode,就直接插入即可
II.如果该索引正在迁移,堵塞
III.如果该索引已经属于ForwardingNode,帮助线程t1完成扩容后,再进行修改
ThreadLocal
我们来介绍一下ThreadLocal的面试点
对ThreadLocal的理解
我们来讲解一下对对ThreadLocal的理解:
/*线程安全性*/
ThreadLocal可以实现资源对象的线程隔离,让每个线程各用各的资源对象,避免争用引发的线程安全问题
ThreadLocal同时实现了线程内资源共享
/*ThreadLocal使用*/
每个线程中有一个ThreadLocalMap类型的成员变量,用于存储资源对象
1.创建一个ThreadLocal(该ThreadLocal实际上就是ThreadLocalMap的key)
ThreadLocal<class?> t1 = new ThreadLocal<>();
2.可以调用set方法存储数据(ThreadLocal就是key,资源对象作为value,放入当前线程的ThreadLocalMap集合中)
t1.set(new String("123"));
3.可以调用get方法查找数据(根据ThreadLocal为key,查找相关数据)
t1.get();
4.可以调用remove方法删除该数据(根据ThreadLocal为key,删除相关数据)
注意点:
I.当使用set时才会构造map对象
II.不同的ThreadLocal使用不同的数据结构
III.扩容时阈值为0.75,每次扩容一倍;存储时采用开放寻址法
/*key*/
这里的key采用的是弱引用:
1.Thread可能需要长时间运行(如线程池的线程),如果key不再被使用,可以被JVM的GC所释放
2.GC仅使key释放,但是value不会释放:
I.获得key时,会删除value
II.setkey时,会将附近的value删除
III.手动remove删除
结束语
目前关于JUC的面试点就总结到这里,该篇文章后续会持续更新~
附录
参考资料:
- 黑马Java八股文面试题视频教程:并发篇-01-线程状态_java中的线程状态_哔哩哔哩_bilibili

