



JVM学习笔记——内存结构篇
JVM学习笔记——内存结构篇
在本系列内容中我们会对JVM做一个系统的学习,本片将会介绍JVM的内存结构部分
我们会分为以下几部分进行介绍:
- JVM整体介绍
- 程序计数器
- 虚拟机栈
- 本地方法栈
- 堆
- 方法区
- 直接内存
JVM整体介绍
我们在正式开始学习JVM之前当然需要先简单认识一下JVM了
JVM简述
首先我们给出JVM的定义:
- Java Virtual Machine - java 程序的运行环境(java 二进制字节码的运行环境)
JVM的优点:
- 一次编写,到处运行
- 自动内存管理,垃圾回收功能
- 数组下标越界检查
- 多态
常见JVM展示
我们下面给出常见的JVM视图展示:

目前我们所讲述的JVM知识基本都是基于HotSpot类型的JVM
JVM总体路线
我们给出JVM的整体框架,而该框架也是我们学习JVM的总体路线:
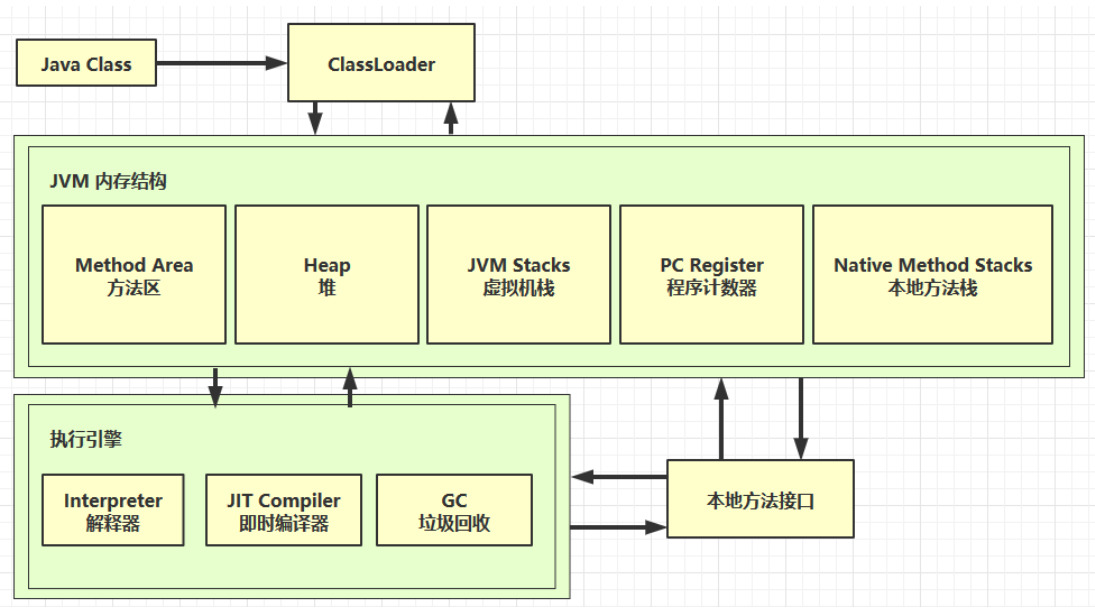
我们的学习顺序如下:
- JVM内存结构
- GC垃圾回收
- Java Class
- ClassLoader
- JIT Compiler
JVM,JRE,JDK比较
我们顺便介绍一个面试常见问题:
- 请给出JVM,JRE,JDK之间的区别
我们首先采用一张图进行解释:

我们来做出简单介绍:
- JVM是我们的Java程序最基本的底层架构,我们通过JVM来实现Java源代码和操作系统之间的交互
- JRE在JVM的基础上添加了我们平时所使用的基础类库,包括有Net Framekwork的核心类库等相关库
- JDK在JRE的基础上又添加了编译工具,包括有jar打包工具,Java运行工具,Javac编译工具,Javadoc文档工具等
- JavaSE程序在JDK的基础上又添加了我们常用的开发工具,市面上我们常见的IDEA或者VS等系列工具
- JavaEE是在 JavaSE 的基础上构建的,它提供Web 服务,通信 API等,可以用来实现企业级的面向服务和Web 3.0应用程序。
程序计数器
首先我们先来介绍JVM内存结构中的程序计数器
程序计数器简述
首先我们给出程序计数器的简单定义:
- Program Counter Register 程序计数器(寄存器)
然后我们给出程序计数器的主要作用:
- 程序计数器主要用于记录下一条jvm指令的执行地址
程序计数器具有以下特点:
-
程序计数器默认情况下不可能出现内存溢出
-
程序计数器是一块较小的内存空间,它通常采用寄存器代替
-
程序计数器绑定线程,每个线程有且只有一个程序计数器,它随着线程创建而创建,随着线程销毁而销毁
程序计数器详细介绍
我们给出一些代码来进行简单介绍:
0: getstatic #20 // PrintStream out = System.out;
3: astore_1 // --
4: aload_1 // out.println(1);
5: iconst_1 // --
6: invokevirtual #26 // --
9: aload_1 // out.println(2);
10: iconst_2 // --
11: invokevirtual #26 // --
14: aload_1 // out.println(3);
15: iconst_3 // --
16: invokevirtual #26 // --
19: aload_1 // out.println(4);
20: iconst_4 // --
21: invokevirtual #26 // --
24: aload_1 // out.println(5);
25: iconst_5 // --
26: invokevirtual #26 // --
29: return
我们下面进行简单解释:
- 首先我们的注释部分是Java的源代码,左侧部分是我们的二进制字节码即jvm指令
- jvm指令中前面的位置是我们的执行地址(物理地址),中间是相关执行指令,最后面带#是常量地址(我们后面会讲到)
- 我们的jvm代码是不能直接与cpu交互的,我们需要通过解释器将jvm代码编程机器码,才可以与cpu进行交互
- 但是我们的jvm代码的位置不是顺序排列的,所以这时我们每个线程都需要一个程序计数器来记录下一个jvm的位置
- 我们将该jvm指令传给解释器后,解释器将其处理的同时程序计数器也接收到下一个地址,进行jvm位置更新
同时我们也强调一点:
- 程序计数器只是逻辑上的概念,我们通常采用寄存器来充当一个程序计数器
- 因为寄存器的读取速度是最快的,我们可以快速保存并且读出物理地址位置来进行交互
虚拟机栈
这小节我们来介绍JVM内存结构中的虚拟机栈
栈简介
我们首先来回顾栈的概念:
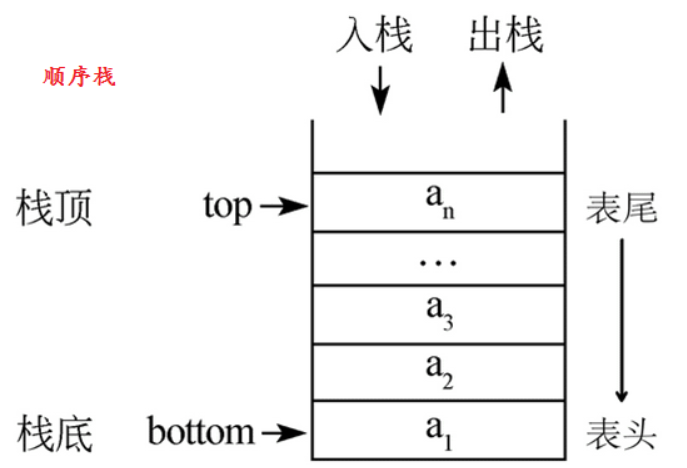
我们的栈先进后出,用于存储程序中的部分信息
虚拟机栈简介
我们的虚拟机栈和栈的基本原理相同,但存储的东西就不尽相同了:
- 虚拟机栈也是绑定线程的,每个线程有且仅有一个虚拟机栈
- 虚拟机栈中存储着栈帧,可以存在有多个栈帧,栈帧就是每个方法运行时所需要的内存
我们给出虚拟机的概念:
- 每个线程运行时所需要的内存,称为虚拟机栈
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
- 每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存
虚拟机栈详细介绍
我们给出一段Java代码来进行展示:
package cn.itcast.jvm.t1.stack;
/**
* 演示栈帧
*/
public class Demo1_1 {
public static void main(String[] args) throws InterruptedException {
method1();
method3();
}
private static void method1() {
method2(1, 2);
}
private static int method2(int a, int b) {
int c = a + b;
return c;
}
private static int method3() {
return 1;
}
}
我们进行简单的介绍:
- 这个程序就是一个线程
- 这三个方法分别就对应着一个栈帧
- 我们调用main,mian进入栈,main中又调用method1,method1进入栈,method1调用method2,所以method2进入栈
- 注意我们的method3不包含在method1的循环中,所以我们会先将前置栈帧都排除后,然后在main栈帧的上方进行累加method3
我们在执行过程中如果采用debug模式是可以看到Frames,这个就是表示的栈帧:
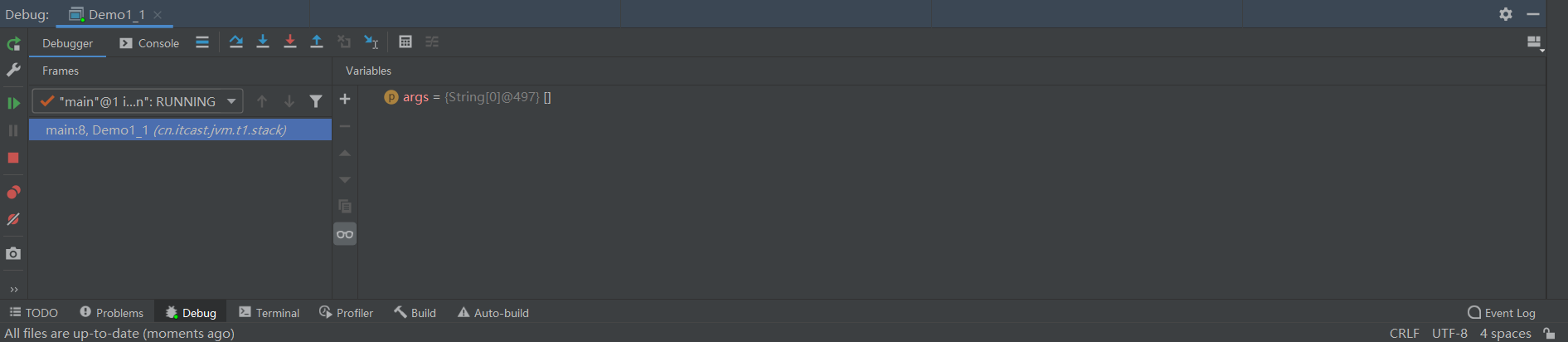
虚拟机栈问题解释
我们针对虚拟机栈提出了三个问题,下面进行解释:
- 垃圾回收是否会涉及栈内存
/*
答案是:
否,因为栈是属于线程内内存,栈具有自动回收功能
*/
- 栈内存是否是越大越好
/*
答案是:
否,如果jvm设置的内存过大,就会导致其它程序所占用的内存小。
*/
- 方法内的局部变量是否线程安全
/**
答案是:
根据实际情况而定,我们通过判断作用范围来进行线程安全判断
首先我们需要介绍两个词汇:
- StringBuffer 用于多线程,保证多线程安全,但效率较慢
- StringBuilder 用于单线程,无法保证但线程安全,效率较快
**/
// 我们下面给出一个简单示例:
// 示例1:下面的变量x是属于方法中的变量,属于局部变量,因此不会出现线程安全问题
package cn.itcast.jvm.t1.stack;
/**
* 局部变量的线程安全问题
*/
public class Demo1_18 {
// 多个线程同时执行此方法
static void m1() {
int x = 0;
for (int i = 0; i < 5000; i++) {
x++;
}
System.out.println(x);
}
}
// 示例2:下面我们通过StringBuilder来进行安全问题测试(因为StringBuilder不具有线程安全保护)
// m1:StringBuilder创建在方法内部,也只在方法内部使用,属于局部变量,不具有线程安全问题
// m2:StringBuilder来自于外部,变量作用范围越界,具有线程安全问题
// m3:StringBuilder返回至外部,变量作用范围越界,具有线程安全问题
package cn.itcast.jvm.t1.stack;
/**
* 局部变量的线程安全问题
*/
public class Demo1_17 {
public static void main(String[] args) {
StringBuilder sb = new StringBuilder();
sb.append(4);
sb.append(5);
sb.append(6);
new Thread(()->{
m2(sb);
}).start();
}
public static void m1() {
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
public static void m2(StringBuilder sb) {
sb.append(1);
sb.append(2);
sb.append(3);
System.out.println(sb.toString());
}
public static StringBuilder m3() {
StringBuilder sb = new StringBuilder();
sb.append(1);
sb.append(2);
sb.append(3);
return sb;
}
}
虚拟机栈内存溢出问题
虚拟机栈在默认情况下为1024K,正常情况下不会溢出,但如果出现异常可能导致溢出
首先我们介绍一个改变虚拟机栈的方法:
// 在配置运行环境的Environment variables中进行配置(如下修改为256k)
-Xss256k
然后我们介绍两种溢出情况:
- 栈帧过多
// 正常情况下我们的栈帧(方法)就算再多也不会导致内存溢出,但是如果我们发生了无限递归异常呢?
// 我们在这个方法中递归调用本身,就会导致不断有栈帧加入到虚拟机栈中,最终导致虚拟机栈内存溢出
package cn.itcast.jvm.t1.stack;
/**
* 演示栈内存溢出 java.lang.StackOverflowError
* -Xss256k
*/
public class Demo1_2 {
private static int count;
public static void main(String[] args) {
try {
method1();
} catch (Throwable e) {
e.printStackTrace();
System.out.println(count);
}
}
private static void method1() {
count++;
method1();
}
}
- 栈帧过大
/*
我们仅仅是来解释这个溢出想法
但实际上我们的默认虚拟机栈大小为1M,是不可能出现栈帧过大的情况的~
*/
虚拟机线程实际问题运行判断
我们会给出两个实际案例来进行讲解:
- CPU占用过多
// 我们的项目通常都会运行在Linux服务器上,所以我们下面通过Linux来介绍方法
// 首先通过top定位哪个进程对cpu的占用过高
top
// 然后我们通过ps命令进一步查看哪个线程引起cpu占用率过高
ps H -eo pid,tid,%cpu | grep 进程id
// 最后我们查看线程具体问题
jstack 进程id
// 最后我们到我们的项目代码中进行检查会发现问题(可能是死循环之类的)
package cn.itcast.jvm.t1.stack;
/**
* 演示 cpu 占用过高
*/
public class Demo1_16 {
public static void main(String[] args) {
new Thread(null, () -> {
System.out.println("1...");
while(true) {
}
}, "thread1").start();
new Thread(null, () -> {
System.out.println("2...");
try {
Thread.sleep(1000000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "thread2").start();
new Thread(null, () -> {
System.out.println("3...");
try {
Thread.sleep(1000000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "thread3").start();
}
}
- 程序运行过久没有结果
/*
我们采用之前相同的方法来进行判断,一般运行过久没有结果都是发生死锁问题
*/
package cn.itcast.jvm.t1.stack;
/**
* 演示线程死锁
*/
class A{};
class B{};
public class Demo1_3 {
static A a = new A();
static B b = new B();
public static void main(String[] args) throws InterruptedException {
new Thread(()->{
synchronized (a) {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (b) {
System.out.println("我获得了 a 和 b");
}
}
}).start();
Thread.sleep(1000);
new Thread(()->{
synchronized (b) {
synchronized (a) {
System.out.println("我获得了 a 和 b");
}
}
}).start();
}
}
本地方法栈
这小节我们来介绍JVM内存结构中的本地方法栈
本地方法简介
首先我们先来简单介绍一下本地方法:
- JVM属于Java层次的东西,是无法通过Java与底层进行交互
- 这时我们就需要一些采用C,C++语言的方法来与底层进行交互,这种方法就被称为本地方法
本地方法特点:
- 本地方法大多设置为接口,其返回值类型为native
- 我们常见的本地方法包括有Object中的clone方法,hashCode方法,wait方法等
本地方法栈简介
本地方法栈自然也不难理解:
- 本地方法栈就是一个存储本地方法的栈
- 其原理与虚拟机栈完全相同,只不过里面的栈帧变为了本地方法而已
堆
这小节我们来介绍JVM内存结构中的堆
堆简介
首先我们需要先理解什么是堆:
- 堆的本体通常可以被看做一棵完全二叉树的数组
那么堆里面通常会储存什么东西:
- 通过关键字new创建的对象都会使用堆来存储
堆具有以下基本特点:
- 有垃圾回收机制
- 堆是线程共享的,堆中的所有对象都需要考虑线程安全问题
堆内存溢出问题
堆通常是用于存储new创建的对象,它的默认大小同样为1024K,我们提供方法来改变堆内存:
// 在配置运行环境的Environment variables中进行配置(如下修改为256k)
-Xmx8m
堆出现内存溢出问题只有一种情况就是创建对象过多:
/*
正常情况下,我们的创建的对象在不使用的情况下就会被自动垃圾回收
但如果出现异常,导致我们不断创建新对象且保存就对象就会导致堆内存溢出
*/
package cn.itcast.jvm.t1.heap;
import java.util.ArrayList;
import java.util.List;
/**
* 演示堆内存溢出 java.lang.OutOfMemoryError: Java heap space
* -Xmx8m
*/
public class Demo1_5 {
public static void main(String[] args) {
int i = 0;
try {
List<String> list = new ArrayList<>();
String a = "hello";
while (true) {
list.add(a); // 这里将旧对象保存下来
a = a + a; // 这里不断创建新对象
i++;
}
} catch (Throwable e) {
e.printStackTrace();
System.out.println(i);
}
}
}
堆内存问题诊断
我们在正常运行中堆的内存占有是非常重要,因此JVM为我们提供了四种方法来检查堆内存问题
首先我们给出用于诊断堆内存问题的参考代码:
package cn.itcast.jvm.t1.heap;
/**
* 演示堆内存
*/
public class Demo1_4 {
public static void main(String[] args) throws InterruptedException {
// 第一阶段:没有对象
System.out.println("1...");
Thread.sleep(30000);
// 第二阶段:制造一个对象,占用堆
byte[] array = new byte[1024 * 1024 * 10];
System.out.println("2...");
Thread.sleep(20000);
// 第三阶段:释放对象,并进行垃圾回收,这时堆变小
array = null;
System.gc();
System.out.println("3...");
Thread.sleep(1000000L);
}
}
我们的JVM为我们提供了四种方法来检测堆的状况:
- jps工具
// jps用于查看当前系统中有哪些java进程
// 我们直接在IDEA的输入台输入即可
jps
- jmap工具
// jmap用于查看当前系统中堆内存占用情况(静态形式)
// 我们直接在IDEA的输入台输入即可
jmap -heap 进程id
// 我们可以看到Heap Usage就是内存管理
// 其中Eden space 为新产生的堆内存
// 其中Old Generation 为之前产生的堆内存
- jconsole工具
// jconsole用于查看当前系统中堆内存占用情况(图形化界面app展示)
// 我们直接在IDEA的输入台输入即可
jconsole
- jvisualvm工具
// jvisualvm用于查看当前系统中堆内存占用情况(图形化界面app展示)
// 我们直接在IDEA的输入台输入即可
jvisualvm
方法区
这小节我们来介绍JVM内存结构中的方法区
方法区简介
我们首先来简单介绍一下方法区:
- 方法区是所有java虚拟机共享的一片区域
- 方法区中存放着所有类的所有信息,包括有属性,方法,构造方法等
- 方法区在虚拟机启动的一瞬间被创建,同样在虚拟机停止时方法区进行销毁
我们需要特别注意一点:
- 方法区和程序计数器一样只是一个概念
- 我们在实际开发中,jdk1.8之前采用的是永久代,在jdk1.8及以后均采用元空间
我们直接给出其内存结构图展示:

方法区内存溢出问题
方法区同样存在有内存溢出问题,但并不常见
我们将方法区的讲解分为两部分,有永久代也有元空间的讲解:
- 永久代内存溢出问题
// 永久代的概念仅存在于jdk1.8之前,我们可以通过-XX来控制永久代大小
// 当方法区为永久代时,溢出就显示错误java.lang.OutOfMemoryError: PermGen space
package cn.itcast.jvm;
import com.sun.xml.internal.ws.org.objectweb.asm.ClassWriter;
import com.sun.xml.internal.ws.org.objectweb.asm.Opcodes;
/**
* 演示永久代内存溢出 java.lang.OutOfMemoryError: PermGen space
* -XX:MaxPermSize=8m
*/
public class Demo1_8 extends ClassLoader {
public static void main(String[] args) {
int j = 0;
try {
Demo1_8 test = new Demo1_8();
for (int i = 0; i < 20000; i++, j++) {
ClassWriter cw = new ClassWriter(0);
cw.visit(Opcodes.V1_6, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null);
byte[] code = cw.toByteArray();
test.defineClass("Class" + i, code, 0, code.length);
}
} finally {
System.out.println(j);
}
}
}
- 元空间内存溢出问题
// 元空间存在于jdk1.8之后,实际上这时的元空间已经作用于系统内存了,相当于元空间的大小几乎是不可能出现溢出的
// 所以我们需要先设置元空间大小才能观察到溢出问题:-XX:MaxMetaspaceSize=8m
// 当方法区为永久代时,溢出就显示错误java.lang.OutOfMemoryError: Metaspace
package cn.itcast.jvm.t1.metaspace;
import jdk.internal.org.objectweb.asm.ClassWriter;
import jdk.internal.org.objectweb.asm.Opcodes;
/**
* 演示元空间内存溢出 java.lang.OutOfMemoryError: Metaspace
* -XX:MaxMetaspaceSize=8m
*/
public class Demo1_8 extends ClassLoader { // 可以用来加载类的二进制字节码
public static void main(String[] args) {
int j = 0;
try {
Demo1_8 test = new Demo1_8();
for (int i = 0; i < 10000; i++, j++) {
// ClassWriter 作用是生成类的二进制字节码
ClassWriter cw = new ClassWriter(0);
// 版本号, public, 类名, 包名, 父类, 接口
cw.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null);
// 返回 byte[]
byte[] code = cw.toByteArray();
// 执行了类的加载
test.defineClass("Class" + i, code, 0, code.length); // Class 对象
}
} finally {
System.out.println(j);
}
}
}
常量池简介
我们再回到方法区来简单介绍一下常量池:
- 我们在上面的图中可以看到常量池之前是放在方法区中的StringTable,但在jdk1.8之后放在了堆中的StingTable
- 我们需要注意的是:即使StringTable在堆里面,在堆里存放的数据和在StringTable里存放的数据也不是同一个数据
我们先来简单介绍一下常量池:
- 常量池实际上是一张表
- 虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息
我们再介绍一下运行时常量池:
-
运行时常量池,常量池是 *.class 文件中的
-
当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
常量池详细介绍
我们通过一个简单的代码编译来介绍常量池:
// 下面是helloworld的源码
package cn.itcast.jvm.t5;
// 二进制字节码(类基本信息,常量池,类方法定义,包含了虚拟机指令)
public class HelloWorld {
public static void main(String[] args) {
System.out.println("hello world");
}
}
然后我们运行之后,我们可以在out文件夹下找到其编译后程序:
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package cn.itcast.jvm.t5;
public class HelloWorld {
public HelloWorld() {
}
public static void main(String[] args) {
System.out.println("hello world");
}
}
我们在该目录下对其进行底层查看:
// 我们通过javap -v 代码名.class来查看其详细信息
// 其中包括有:class文件的路径、最后修改时间、文件大小;类的全路径、源(java)文件;常量池;常量定义、值;构造方法等
javap -v HelloWorld.class
// 我们查看其内部详细信息:
// 这部分是class文件路径,最后修改日志,文件大小等信息
Classfile /E:/编程内容/JVM/资料-解密JVM/代码/jvm/out/production/jvm/cn/itcast/jvm/t5/HelloWorld.class
Last modified 2022-11-2; size 567 bytes
MD5 checksum 8efebdac91aa496515fa1c161184e354
Compiled from "HelloWorld.java"
// 这部分是全路径,源码等
public class cn.itcast.jvm.t5.HelloWorld
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
// 这部分是常量池:我们可以看到很多东西,注解是IDEA为我们携带的
// 首先我们可以看到最前面的#,这个代表这一行的地址,然后如果我们希望看懂这一行的信息,需要根据后面的#查看对应的行号
// 我们到对应的行号去寻找,直到最后我们可以看到utf8形式的结果,我们将这些信息组合起来就是该行后面IDEA为我们注释的信息
Constant pool:
#1 = Methodref #6.#20 // java/lang/Object."<init>":()V
#2 = Fieldref #21.#22 // java/lang/System.out:Ljava/io/PrintStream;
#3 = String #23 // hello world
#4 = Methodref #24.#25 // java/io/PrintStream.println:(Ljava/lang/String;)V
#5 = Class #26 // cn/itcast/jvm/t5/HelloWorld
#6 = Class #27 // java/lang/Object
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 LocalVariableTable
#12 = Utf8 this
#13 = Utf8 Lcn/itcast/jvm/t5/HelloWorld;
#14 = Utf8 main
#15 = Utf8 ([Ljava/lang/String;)V
#16 = Utf8 args
#17 = Utf8 [Ljava/lang/String;
#18 = Utf8 SourceFile
#19 = Utf8 HelloWorld.java
#20 = NameAndType #7:#8 // "<init>":()V
#21 = Class #28 // java/lang/System
#22 = NameAndType #29:#30 // out:Ljava/io/PrintStream;
#23 = Utf8 hello world
#24 = Class #31 // java/io/PrintStream
#25 = NameAndType #32:#33 // println:(Ljava/lang/String;)V
#26 = Utf8 cn/itcast/jvm/t5/HelloWorld
#27 = Utf8 java/lang/Object
#28 = Utf8 java/lang/System
#29 = Utf8 out
#30 = Utf8 Ljava/io/PrintStream;
#31 = Utf8 java/io/PrintStream
#32 = Utf8 println
#33 = Utf8 (Ljava/lang/String;)V
// 这部分是编译后的代码,我们可以看到里面包含了#号,这些#就对应着上面的常量池,他们从常量池中获得相关信息用于代码中
{
public cn.itcast.jvm.t5.HelloWorld();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 4: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcn/itcast/jvm/t5/HelloWorld;
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String hello world
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 6: 0
line 7: 8
// 这里是局部变量表
LocalVariableTable:
Start Length Slot Name Signature
0 9 0 args [Ljava/lang/String;
}
// 最后标上上述信息的来源文件
SourceFile: "HelloWorld.java"
StringTable串池简介
我们首先来简单介绍一下串池:
- 串池的本质是一个哈希表,其中的每个元素都是唯一的
我们在这里稍微解释一下为什么StringTable会移动到堆中:
- jdk7中将StringTable放到了堆空间中
- 因为永久代的回收效率很低,在full GC的时候才会触发。
- 而Full GC是老年代空间不足、永久代空间不足时才会触发。这就导致StringTable回收效率不高。
- 而我们开发中会有大量的字符串被创建,回收效率低,导致永久代内存不足。放到堆里,能及时回收内存。
然后我们提前介绍一下串池的特点:
- 常量池的字符串仅仅是符号,第一次用到时才会变为对象
- 利用串池的机制,可以避免重复创建字符串对象
- 字符串变量拼接的原理是StringBuiler拼接(jdk1.8)
- 字符串常量拼接的原理是编译期优化
- 可以使用intern方法,主动将串池中还没有的字符串放入串池
StringTable串池详细介绍
我们通过一段代码来仔细介绍串池:
package cn.itcast.jvm.t1.stringtable;
// StringTable [ "a", "b" ,"ab" ] hashtable 结构,不能扩容
public class Demo1_22 {
// 常量池中的信息,都会被加载到运行时常量池中, 这时 a b ab 都是常量池中的符号,还没有变为 java 字符串对象
public static void main(String[] args) {
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2; // new StringBuilder().append("a").append("b").toString() new String("ab")
String s5 = "a" + "b"; // javac 在编译期间的优化,结果已经在编译期确定为ab
System.out.println(s3 == s5);
}
}
然后我们对其进行编译解码:
// 解码语句
javap -v Demo1_22.class
// 基本信息
Classfile /E:/编程内容/JVM/资料-解密JVM/代码/jvm/out/production/jvm/cn/itcast/jvm/t1/stringtable/Demo1_22.class
Last modified 2022-11-2; size 985 bytes
MD5 checksum a5eb84bf1a7d8a1e725491f36237777b
Compiled from "Demo1_22.java"
public class cn.itcast.jvm.t1.stringtable.Demo1_22
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
// 常量池
Constant pool:
#1 = Methodref #12.#36 // java/lang/Object."<init>":()V
#2 = String #37 // a
#3 = String #38 // b
#4 = String #39 // ab
#5 = Class #40 // java/lang/StringBuilder
#6 = Methodref #5.#36 // java/lang/StringBuilder."<init>":()V
#7 = Methodref #5.#41 // java/lang/StringBuilder.append:
#8 = Methodref #5.#42 // java/lang/StringBuilder.toString:()Ljava/lang/String;
#9 = Fieldref #43.#44 // java/lang/System.out:Ljava/io/PrintStream;
#10 = Methodref #45.#46 // java/io/PrintStream.println:(Z)V
#11 = Class #47 // cn/itcast/jvm/t1/stringtable/Demo1_22
#12 = Class #48 // java/lang/Object
#13 = Utf8 <init>
#14 = Utf8 ()V
#15 = Utf8 Code
#16 = Utf8 LineNumberTable
#17 = Utf8 LocalVariableTable
#18 = Utf8 this
#19 = Utf8 Lcn/itcast/jvm/t1/stringtable/Demo1_22;
#20 = Utf8 main
#21 = Utf8 ([Ljava/lang/String;)V
#22 = Utf8 args
#23 = Utf8 [Ljava/lang/String;
#24 = Utf8 s1
#25 = Utf8 Ljava/lang/String;
#26 = Utf8 s2
#27 = Utf8 s3
#28 = Utf8 s4
#29 = Utf8 s5
#30 = Utf8 StackMapTable
#31 = Class #23 // "[Ljava/lang/String;"
#32 = Class #49 // java/lang/String
#33 = Class #50 // java/io/PrintStream
#34 = Utf8 SourceFile
#35 = Utf8 Demo1_22.java
#36 = NameAndType #13:#14 // "<init>":()V
#37 = Utf8 a
#38 = Utf8 b
#39 = Utf8 ab
#40 = Utf8 java/lang/StringBuilder
#41 = NameAndType #51:#52 // append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
#42 = NameAndType #53:#54 // toString:()Ljava/lang/String;
#43 = Class #55 // java/lang/System
#44 = NameAndType #56:#57 // out:Ljava/io/PrintStream;
#45 = Class #50 // java/io/PrintStream
#46 = NameAndType #58:#59 // println:(Z)V
#47 = Utf8 cn/itcast/jvm/t1/stringtable/Demo1_22
#48 = Utf8 java/lang/Object
#49 = Utf8 java/lang/String
#50 = Utf8 java/io/PrintStream
#51 = Utf8 append
#52 = Utf8 (Ljava/lang/String;)Ljava/lang/StringBuilder;
#53 = Utf8 toString
#54 = Utf8 ()Ljava/lang/String;
#55 = Utf8 java/lang/System
#56 = Utf8 out
#57 = Utf8 Ljava/io/PrintStream;
#58 = Utf8 println
#59 = Utf8 (Z)V
// 代码解释
{
public cn.itcast.jvm.t1.stringtable.Demo1_22();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 4: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcn/itcast/jvm/t1/stringtable/Demo1_22;
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=6, args_size=1
// 从这里开始我们正式进入main
// 在最开始:StringTable=[],堆=[]
// ldc #2 会把 a 符号变为 "a" 字符串对象,这时StringTable=["a"]
0: ldc #2 // String a
// 这里的astore_1意思将#2的值放入局部变量池的第一位
2: astore_1
// ldc #3 会把 b 符号变为 "b" 字符串对象,这时StringTable=["a","b"]
3: ldc #3 // String b
5: astore_2
// ldc #4 会把 ab 符号变为 "ab" 字符串对象,这时StringTable=["a","b","ab"]
6: ldc #4 // String ab
8: astore_3
// 接下来的操作都是针对String s4 = s1 + s2;
// 这里首先创建了一个StringBuilder类
9: new #5 // class java/lang/StringBuilder
12: dup
// 这里针对StringBuilder进行初始化
13: invokespecial #6 // Method java/lang/StringBuilder."<init>":()V
16: aload_1
// 这里对StringBuilder进行append方法,上面的aload_1意思是读取了第一个局部变量的值,相当于添加了"a"
17: invokevirtual #7 // Method java/lang/StringBuilder.append:
20: aload_2
// 这里对StringBuilder进行append方法,上面的aload_1意思是读取了第二个局部变量的值,相当于添加了"b"
21: invokevirtual #7 // Method java/lang/StringBuilder.append:
// 这里对StringBuilder进行toString方法,相当于new了一个"ab",这时StringTable没有发生变化,但是堆产生了该值
24: invokevirtual #8 // Method java/lang/StringBuilder.toString:
// 这里是针对String s5 = "a" + "b";操作,由于产生的结果为"ab",已经放在局部变量表里,所以直接读取即可
// 注意:有StringTable的值只能有一个,所以这时StringTable=["a","b","ab"] 并没有发生变化
27: astore 4
29: ldc #4 // String ab
// 后面就是获得对应值然后比较
31: astore 5
33: getstatic #9 // Field java/lang/System.out:Ljava/io/PrintStream;
36: aload_3
37: aload 5
39: if_acmpne 46
42: iconst_1
43: goto 47
46: iconst_0
47: invokevirtual #10 // Method java/io/PrintStream.println:(Z)V
50: return
LineNumberTable:
line 11: 0
line 12: 3
line 13: 6
line 14: 9
line 15: 29
line 17: 33
line 21: 50
// 局部变量池
LocalVariableTable:
Start Length Slot Name Signature
0 51 0 args [Ljava/lang/String;
3 48 1 s1 Ljava/lang/String;
6 45 2 s2 Ljava/lang/String;
9 42 3 s3 Ljava/lang/String;
29 22 4 s4 Ljava/lang/String;
33 18 5 s5 Ljava/lang/String;
StackMapTable: number_of_entries = 2
frame_type = 255 /* full_frame */
offset_delta = 46
locals = [ class "[Ljava/lang/String;", class java/lang/String, class java/lang/String, class java/lang/String, class java/lang/String, class java/lang/String ]
stack = [ class java/io/PrintStream ]
frame_type = 255 /* full_frame */
offset_delta = 0
locals = [ class "[Ljava/lang/String;", class java/lang/String, class java/lang/String, class java/lang/String, class java/lang/String, class java/lang/String ]
stack = [ class java/io/PrintStream, int ]
}
SourceFile: "Demo1_22.java"
StringTable字符串延迟加载
在这里我们再次强调一下StringTable中元素的加载原则:
- StringTable中的值只会加载一次,不会重复加载
- 存放在常量池的值在运行时不会加载,只有在第一次运行时才会加载到StringTable中
我们采用一个简单程序来证明:
package cn.itcast.jvm.t1.stringtable;
/**
* 演示字符串字面量也是【延迟】成为对象的
*/
public class TestString {
public static void main(String[] args) {
int x = args.length;
System.out.println(); // 字符串个数 2275
System.out.print("1");
System.out.print("2");
System.out.print("3");
System.out.print("4");
System.out.print("5");
System.out.print("6");
System.out.print("7");
System.out.print("8");
System.out.print("9");
System.out.print("0");
System.out.print("1"); // 字符串个数 2285
System.out.print("2");
System.out.print("3");
System.out.print("4");
System.out.print("5");
System.out.print("6");
System.out.print("7");
System.out.print("8");
System.out.print("9");
System.out.print("0");
System.out.print(x); // 字符串个数 2285
}
}
StringTable的intern功能介绍
我们的intern的功能主要分为两个版本:
- jdk1.6:将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,放入串池, 会把串池中的对象返回
- jdk1.8:将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串池中的对象返回
我们利用同样的代码来进行不同版本的介绍:
// 1.6版本
package cn.itcast.jvm;
public class Demo1_23 {
public static void main(String[] args) {
// 我们来仔细分析这个操作
// 首先StringTable里面加入"a",然后堆里加上一个"a";然后StringTable里面加入"b",然后堆里加上一个"b"
// 最后使用了toString方法,将"ab"放入堆中
String s = new String("a") + new String("b");
// StringTable=["a","b"]
// 堆: new String("a") new String("b") new String("ab")
// 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串池中的对象返回
// 目前s没有在StringTable中,所以将其复制一份放入StringTable,并将StringTable里面的"ab"返回回去
// 这时s和StringTable里面的"ab"是不一样的!
String s2 = s.intern();
// 这时x,s2是StringTable里面的"ab",s是堆里面的"ab"
String x = "ab";
System.out.println( s2 == x);//true
System.out.println( s == x );//false
}
}
public static void main(String[] args) {
String x = "ab";
String s = new String("a") + new String("b");
// StringTable=["a","b","ab"]
// 堆 new String("a") new String("b") new String("ab")
// 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池,会把串池中的对象返回
// 目前StringTable里存在"ab",所以将StringTable里面的ab返回给s2即可
// 目前s2和x属于StringTable里面的ab,s属于堆里面的ab
String s2 = s.intern();
System.out.println( s2 == x);//true
System.out.println( s == x );//false
}
}
// 1.8版本
package cn.itcast.jvm.t1.stringtable;
public class Demo1_23 {
public static void main(String[] args) {
String s = new String("a") + new String("b");
// StringTable=["a","b"]
// 堆 new String("a") new String("b") new String("ab")
// 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池,会把串池中的对象返回
// 这里由于StringTable里面不存在,会将堆中s的字符串做成一个引用直接放入StringTable里面,再将StringTable的值返回
// 这时s,s2,x均属于堆里面的ab,不过s2是堆里的ab,s,x为StringTable里面的引用的堆里面的ab,但他们相等
String s2 = s.intern();
String x = "ab";
System.out.println( s2 == x);//true
System.out.println( s == x );//true
}
}
public static void main(String[] args) {
String x = "ab";
String s = new String("a") + new String("b");
// StringTable=["a","b","ab"]
// 堆 new String("a") new String("b") new String("ab")
// 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池,会把串池中的对象返回
// 目前StringTable里存在"ab",所以将StringTable里面的ab返回给s2即可
// 目前s2和x属于StringTable里面的ab,s属于堆里面的ab
String s2 = s.intern();
System.out.println( s2 == x);//true
System.out.println( s == x );//false
}
}
StringTable常见面试题解答
下面我们给出一个StringTable的常见面试题来进行测试:
package cn.itcast.jvm.t1.stringtable;
/**
* 演示字符串相关面试题
*/
public class Demo1_21 {
// 我们会给出StringTable和堆的值
public static void main(String[] args) {
// StringTable=["a"]
String s1 = "a";
// StringTable=["a","b"]
String s2 = "b";
// StringTable=["a","b","ab"]
String s3 = "a" + "b"; // ab
// StringTable=["a","b","ab"],堆:"ab"
String s4 = s1 + s2; // new String("ab") 和 s3 不相等
// StringTable=["a","b","ab"],堆:"ab"
String s5 = "ab"; // s3 == s5
// StringTable=["a","b","ab"],堆:"ab"
String s6 = s4.intern(); // s4是堆里的ab,s6是StringTable里面的ab
// 问
System.out.println(s3 == s4); // false
System.out.println(s3 == s5); // true
System.out.println(s3 == s6); // true
// StringTable=["a","b","ab","c","d"],堆:"ab"."c","d","cd"
String x2 = new String("c") + new String("d"); // new String("cd")
// StringTable=["a","b","ab","c","d","cd-来自堆"],堆:"ab"."c","d","cd"
x2.intern();
// x1是StringTable里面的cd,但StringTable里面的cd来自堆,所以x1 == x2
String x1 = "cd";
System.out.println(x1 == x2);
// 问,如果调换了【最后两行代码】的位置呢,如果是jdk1.6呢(这个就自己思考啦~)
}
}
StringTable垃圾回收问题
StringTable会自动进行垃圾回收,这也是我们在JDK运行中选择StringTable的原因之一
我们通过一个简单的案例进行解释:
package cn.itcast.jvm.t1.stringtable;
import java.util.ArrayList;
import java.util.List;
/**
* 演示 StringTable 垃圾回收
* -Xmx10m -XX:+PrintStringTableStatistics(打印StringTable内容) -XX:+PrintGCDetails -verbose:gc(打印垃圾回收)
*/
public class Demo1_7 {
public static void main(String[] args) throws InterruptedException {
int i = 0;
try {
for (int j = 0; j < 100000; j++) { // 设置1w个数
// 这里如果不采用.intern()
// 我们会发现1w个数全部存入内存中
String.valueOf(j);
i++;
}
} catch (Throwable e) {
e.printStackTrace();
} finally {
System.out.println(i);
}
}
}
/**
* 演示 StringTable 垃圾回收
* -Xmx10m -XX:+PrintStringTableStatistics(打印StringTable内容) -XX:+PrintGCDetails -verbose:gc(打印垃圾回收)
*/
public class Demo1_7 {
public static void main(String[] args) throws InterruptedException {
int i = 0;
try {
for (int j = 0; j < 100000; j++) { // 设置1w个数
// 这里如果采用.intern()
// 我们会发现StringTable里面的值会少于1w,这是因为发生了垃圾回收,回收掉不使用的信息
String.valueOf(j).intern();
i++;
}
} catch (Throwable e) {
e.printStackTrace();
} finally {
System.out.println(i);
}
}
}
StringTable调优
最后我们介绍StringTable的调优方法:
- 设置桶的个数
// 我们直到StringTable是一个哈希表,哈希表里面桶的个数会影响其效率
// 如果桶过少,每个桶存储信息过多导致查找缓慢;如果桶过多,导致信息分布较为疏散导致查找缓慢
// 我们提供一个配置来改变桶的个数:-XX:StringTableSize=10000(需要设计恰到好处的桶个数)
package cn.itcast.jvm.t1.stringtable;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
/**
* 演示串池大小对性能的影响
* -Xms500m -Xmx500m -XX:+PrintStringTableStatistics -XX:StringTableSize=1009
*/
public class Demo1_24 {
public static void main(String[] args) throws IOException {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if (line == null) {
break;
}
line.intern();
}
System.out.println("cost:" + (System.nanoTime() - start) / 1000000);
}
}
}
- 考虑字符串对象是否入池
// 我们同样可以采用intern来判断该字符串是否应该入池
// 我们排除掉相同的字符串自然可以节省空间~
package cn.itcast.jvm.t1.stringtable;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
/**
* 演示 intern 减少内存占用
* -XX:StringTableSize=200000 -XX:+PrintStringTableStatistics
* -Xsx500m -Xmx500m -XX:+PrintStringTableStatistics -XX:StringTableSize=200000
*/
public class Demo1_25 {
public static void main(String[] args) throws IOException {
List<String> address = new ArrayList<>();
System.in.read();
for (int i = 0; i < 10; i++) {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if(line == null) {
break;
}
// 如果这里不采用.tern会导致全部字符串进入,导致储存较多
address.add(line);
}
System.out.println("cost:" +(System.nanoTime()-start)/1000000);
}
}
System.in.read();
}
}
/**
* 演示 intern 减少内存占用
* -XX:StringTableSize=200000 -XX:+PrintStringTableStatistics
* -Xsx500m -Xmx500m -XX:+PrintStringTableStatistics -XX:StringTableSize=200000
*/
public class Demo1_25 {
public static void main(String[] args) throws IOException {
List<String> address = new ArrayList<>();
System.in.read();
for (int i = 0; i < 10; i++) {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if(line == null) {
break;
}
// 如果这里采用.tern就会筛选字符串,来进行调优~
address.add(line.tern());
}
System.out.println("cost:" +(System.nanoTime()-start)/1000000);
}
}
System.in.read();
}
}
直接内存
这小节我们来介绍系统中常用的直接内存
直接内存简介
我们先来介绍一下直接内存的定义:
- 直接内存不受JVM内存回收管理
- 直接内存是直接受管于系统的内存,不能被JVM所调配
- 直接内存通常用于NIO操作,用于数据缓冲区,其分配成本较高,但读写性能较高
直接内存详细介绍
我们通过一段代码来展示直接内存的速度:
package cn.itcast.jvm.t1.direct;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
/**
* 演示 ByteBuffer 作用
*/
public class Demo1_9 {
static final String FROM = "E:\\编程资料\\第三方教学视频\\youtube\\Getting Started with Spring Boot-sbPSjI4tt10.mp4";
static final String TO = "E:\\a.mp4";
static final int _1Mb = 1024 * 1024;
public static void main(String[] args) {
io(); // io 用时:1535.586957 1766.963399 1359.240226
directBuffer(); // directBuffer 用时:479.295165 702.291454 562.56592
}
// directBuffer(直接内存读取数据)
private static void directBuffer() {
long start = System.nanoTime();
try (FileChannel from = new FileInputStream(FROM).getChannel();
FileChannel to = new FileOutputStream(TO).getChannel();
) {
ByteBuffer bb = ByteBuffer.allocateDirect(_1Mb);
while (true) {
int len = from.read(bb);
if (len == -1) {
break;
}
bb.flip();
to.write(bb);
bb.clear();
}
} catch (IOException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("directBuffer 用时:" + (end - start) / 1000_000.0);
}
// io(jvm正常读取数据)
private static void io() {
long start = System.nanoTime();
try (FileInputStream from = new FileInputStream(FROM);
FileOutputStream to = new FileOutputStream(TO);
) {
byte[] buf = new byte[_1Mb];
while (true) {
int len = from.read(buf);
if (len == -1) {
break;
}
to.write(buf, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("io 用时:" + (end - start) / 1000_000.0);
}
}
我们可以明显看到directBuffer速度比IO读取快很多,那么究竟是怎么实现的
我们可以分别给出两张图进行解释:
- JVM正常读取
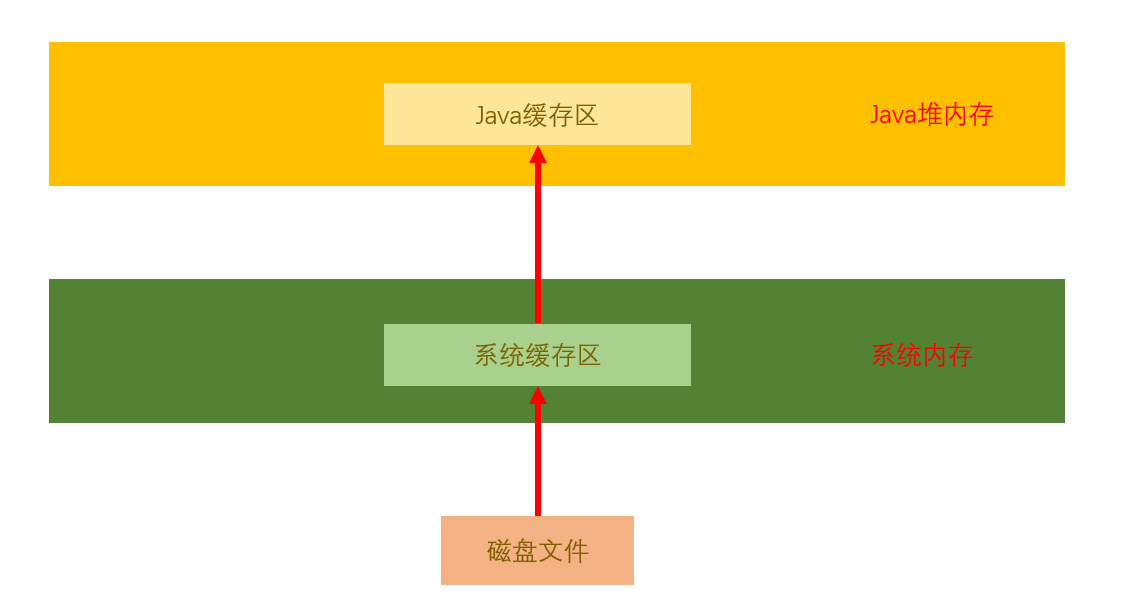
- 直接内存读取
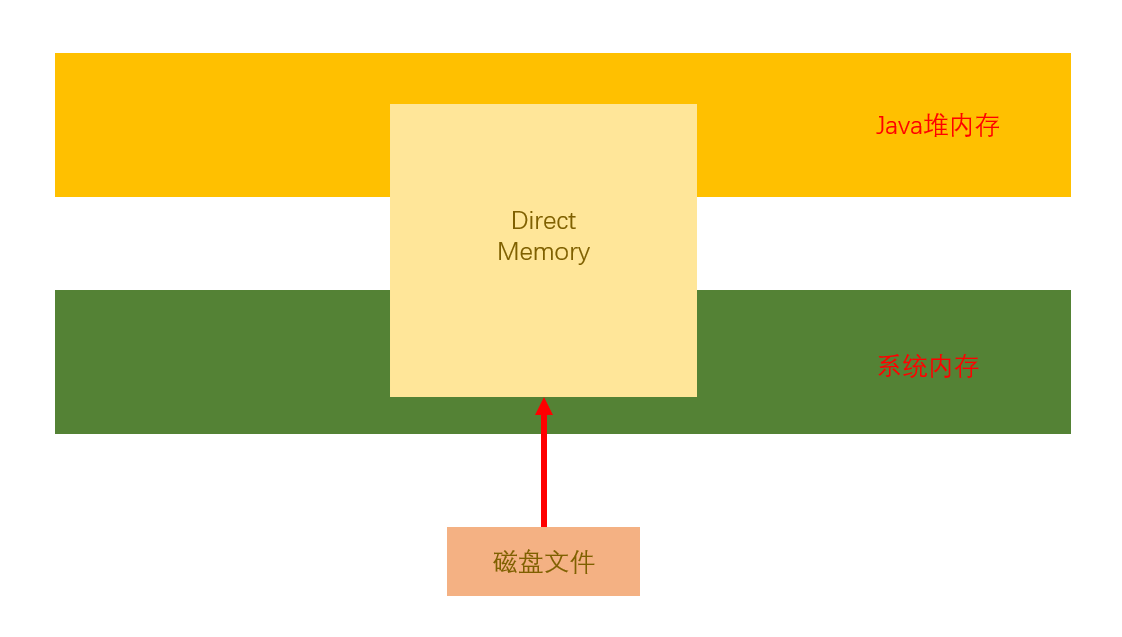
我们由上图可以得知:
- JVM正常读取需要先复制一份经过系统内存缓冲区,然后再复制一份才能进入到java文件中
- DirectMemory可以同时在系统内存和java堆内存中使用,我们只需要传入数据到直接内存中就可以直接读取调用
直接内存内存溢出问题
我们同样来进行直接内存的内存溢出问题测试:
package cn.itcast.jvm.t1.direct;
import java.nio.ByteBuffer;
import java.util.ArrayList;
import java.util.List;
/**
* 演示直接内存溢出
*/
public class Demo1_10 {
static int _100Mb = 1024 * 1024 * 100;
public static void main(String[] args) {
List<ByteBuffer> list = new ArrayList<>();
int i = 0;
try {
while (true) {
// 这里设置一个大小为100mb的直接内存
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_100Mb);
list.add(byteBuffer);
i++;
}
} finally {
System.out.println(i);
}
// 方法区是jvm规范, jdk6 中对方法区的实现称为永久代
// jdk8 对方法区的实现称为元空间
}
}
直接内存释放原理
我们目前所使用的直接内存是DirectMemory:
package cn.itcast.jvm.t1.direct;
import java.io.IOException;
import java.nio.ByteBuffer;
/**
* 我们查看内存管理需要到任务管理器里查看,因为该内存属于系统内存,不再属于jvm
*/
public class Demo1_26 {
static int _1Gb = 1024 * 1024 * 1024;
// 我们使用debug模式调试
public static void main(String[] args) throws IOException {
// 我们使用byteBuffer来调取1G的内存使用
// 我们开启项目后会看到一个内存为1G的java项目
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1Gb);
System.out.println("分配完毕...");
// 输入空格后开始进行系统的垃圾回收,这时byteBuffer被回收,我们会注意到内存为1G的项目结束
System.in.read();
System.out.println("开始释放...");
byteBuffer = null;
System.gc();
System.in.read();
}
}
但是我们需要注意的是我们的jvm的回收功能对系统内存是没有管辖权力的
所以回收ByteBuffer的类另有他人:
package cn.itcast.jvm.t1.direct;
import sun.misc.Unsafe;
import java.io.IOException;
import java.lang.reflect.Field;
/**
* 直接内存分配的底层原理:Unsafe
*/
public class Demo1_27 {
static int _1Gb = 1024 * 1024 * 1024;
public static void main(String[] args) throws IOException {
// unsafe正常情况下不会使用,因为系统内存通常由系统自动控制,我们这里采用暴力反射获取
Unsafe unsafe = getUnsafe();
// 分配内存(base实际上是该内存的地址,所以我们在释放时同样提供该base地址)
long base = unsafe.allocateMemory(_1Gb);
unsafe.setMemory(base, _1Gb, (byte) 0);
System.in.read();
// 释放内存
unsafe.freeMemory(base);
System.in.read();
}
// 暴力反射获得unsafe对象
public static Unsafe getUnsafe() {
try {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe unsafe = (Unsafe) f.get(null);
return unsafe;
} catch (NoSuchFieldException | IllegalAccessException e) {
throw new RuntimeException(e);
}
}
}
然后我们就可以通过DirectMemory的源码来查看为什么它会收到jvm控制:
// Primary constructor
// DirectByteBuffer构造器里面直接调用了unsafe类来进行直接内存的控制
DirectByteBuffer(int cap) {
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
// 进行直接内存的生产
long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
// cleaner会自动检测directMemory是否还存在,若不存在调用该方法
// 这里采用cleaner,直接创建一个新的类型的Deallocator,跳转到下面的类中
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
// cleaner操作跳转的类,继承了Runnable
private static class Deallocator
implements Runnable
{
private static Unsafe unsafe = Unsafe.getUnsafe();
private long address;
private long size;
private int capacity;
private Deallocator(long address, long size, int capacity) {
assert (address != 0);
this.address = address;
this.size = size;
this.capacity = capacity;
}
// 被清理时调用下述方法,采用unsafe.freeMemory(address)来清理直接内存,所以我们的垃圾回收才能清理直接内存
public void run() {
if (address == 0) {
// Paranoia
return;
}
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
}
禁用显式回收的影响
其实在正常情况下我们的显式回收是不被允许开启的,因为可能会导致我们的部分信息损失:
package cn.itcast.jvm.t1.direct;
import java.io.IOException;
import java.nio.ByteBuffer;
/**
* 禁用显式回收对直接内存的影响
*/
public class Demo1_26 {
static int _1Gb = 1024 * 1024 * 1024;
/*
* -XX:+DisableExplicitGC 禁止显式回收配置
*/
public static void main(String[] args) throws IOException {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1Gb);
System.out.println("分配完毕...");
System.in.read();
System.out.println("开始释放...");
byteBuffer = null;
System.gc(); // 显式的垃圾回收,Full GC 这时这个操作是无效的
System.in.read();
// 那么直接内存只能等到系统内存满了之后自动调用被动垃圾回收,但那样直接内存会占用大量空间
// 但是我们又希望清除掉这个直接内存,那么我们这时就只能手动采用unsafe的方法了,这里就不做代码展示了~
// unsafe.freeMemory(address);
}
}
结束语
到这里我们JVM的内存结构篇就结束了,希望能为你带来帮助~
附录
该文章属于学习内容,具体参考B站黑马程序员满老师的JVM完整教程
这里附上视频链接:01_什么是jvm_哔哩哔哩_bilibili

