Spark RDD
参考:http://blog.csdn.net/dc_726/article/details/41381791
spark中使用了RDD(Resilient Distributed Datasets, 弹性分布式数据集)抽象分布式计算,即使用RDD以及对应的transform/action等操作来执行分布式计算;并且基于RDD之间的依赖关系组成lineage以及checkpoint等机制来保证整个分布式计算的容错性。
1 背景
RDD模型的产生动机主要来源于两种主流的应用场景:
Ø 迭代式算法:迭代式机器学习、图算法,包括PageRank、K-means聚类和逻辑回归(logistic regression)
Ø 交互式数据挖掘工具:用户在同一数据子集上运行多个Adhoc查询。
不难看出,这两种场景的共同之处是:在多个计算或计算的多个阶段间,重用中间结果。不幸的是,在目前框架如MapReduce中,要想在计算之间重用数据,唯一的办法就是把数据保存到外部存储系统中,
例如分布式文件系统。这就导致了巨大的数据复制、磁盘I/O、序列化的开销,甚至会占据整个应用执行时间的一大部分。
RDD横空出世,它的主要功能有:
Ø 高效的错误容忍
Ø 中间结果持久化到内存的并行数据结构
Ø 可控制数据分区来优化数据存储
Ø 丰富的操作方法
对于设计RDD来说,最大的挑战在于如何提供高效的错误容忍(fault-tolerance)。现有的集群上的内存存储抽象,如分布式共享内存、key-value存储、内存数据库以及Piccolo等,都提供了对可变状态(如数据库表里的Cell)的细粒度更新。
在这种设计下为了容错,就必须在集群结点间进行数据复制(data replicate)或者记录日志。这两种方法对于数据密集型的任务来说开销都非常大,因为需要在结点间拷贝大量的数据,而网络带宽远远低于RAM。
与这些框架不同,RDD提供基于粗粒度转换(coarse-grained transformation)的接口,例如map、filter、join,能够将同一操作施加到许多数据项上。
于是通过记录这些构建数据集(lineage世族)的粗粒度转换的日志,而非实际数据,就能够实现高效的容错。
当某个RDD丢失时,RDD有充足的关于丢失的那个RDD是如何从其他RDD产生的信息,从而通过重新计算来还原丢失的数据,避免了数据复制的高开销。
2 RDD简介
2.1概念
spark中使用了RDD(Resilient Distributed Datasets, 弹性分布式数据集)抽象分布式计算,即使用RDD以及对应的transform/action等操作来执行分布式计算;并且基于RDD之间的依赖关系组成lineage以及checkpoint等机制来保证整个分布式计算的容错性。
RDD是一种只读的、分区的记录集合。也是一个容错的、并行的数据结构。具体来说,RDD具有以下一些特点:
Ø 创建:只能通过转换从两种数据源中创建RDD:1)稳定存储中的数据;2)其他RDD。
Ø 只读:状态不可变,不能修改
Ø 分区:支持使RDD中的元素根据那个key来分区(partitioning),保存到多个结点上。还原时只会重新计算丢失分区的数据,而不会影响整个系统。
Ø 路径:在RDD中叫世族或血统(lineage),即RDD有充足的信息关于它是如何从其他RDD产生而来的。
Ø 持久化:支持将会·被重用的RDD缓存(如in-memory或溢出到磁盘)
Ø 延迟计算:像DryadLINQ一样,Spark也会延迟计算RDD,使其能够将转换管道化(pipeline transformation)
Ø 操作:丰富的动作(action),count/reduce/collect/save等。
关于转换(transformation)与动作(action)的区别,前者会生成新的RDD,而后者只是将RDD上某项操作的结果返回给程序,而不会生成新的RDD
2.2优势
RDD与DSM(distributed shared memory)的最大不同是:RDD只能通过粗粒度转换来创建,而DSM则允许对每个内存位置上数据的读和写。
在这种定义下,DSM不仅包括了传统的共享内存系统,也包括了像提供了共享DHT(distributed hash table)的Piccolo以及分布式数据库等。所以RDD相比DSM有着下面这些优势:
Ø 高效的容错机制:没有检查点(checkpoint)开销,能够通过世族关系还原。而且还原只涉及了丢失数据分区的重计算,并且重算过程可以在不同结点并行进行,而无需回滚整个系统。
Ø 结点落后问题的缓和(mitigate straggler):RDD的不可变性使得系统能够运行类似MapReduce备份任务,来缓和慢结点。这在DSM系统中却难以实现,因为多个相同任务一起运行会访问同样的内存数据而相互干扰。
Ø 批量操作:任务能够根据数据本地性(data locality)被分配,从而提高性能。
Ø 优雅降级(degrade gracefully):当内存不足时,大分区会被溢出到磁盘,提供与其他现今的数据并行计算系统类似的性能。
2.3应用场景
RDD最适合那种在数据集上的所有元素都执行相同操作的批处理式应用。在这种情况下,RDD只需记录世族图谱中的每个转换就能还原丢失的数据分区,而无需记录大量的数据操作日志。
所以RDD不适合那些需要异步、细粒度更新状态的应用,比如Web应用的存储系统,或增量式的Web爬虫等。对于这些应用,使用具有事务更新日志和数据检查点的数据库系统更为高效。
2.4工作原理
在了解了RDD的概念和内部表现形式之后,那么RDD是如何运行的呢?
总高层次来看,主要分为三步:
- 创建RDD对象,
- DAG调度器创建执行计划,
- Task调度器分配任务并调度Worker开始运行。
RDD如何保障数据处理效率?
RDD提供了两方面的特性persistence和patitioning,用户可以通过persist与patitionBy函数来控制RDD的这两个方面。RDD的分区特性与并行计算能力(RDD定义了parallerize函数),使得Spark可以更好地利用可伸缩的硬件资源。
真的能避免对整个数据结构的扫描?待验证
RDD本质上是一个内存数据集,在访问RDD时,指针只会指向与操作相关的部分。例如存在一个面向列的数据结构,其中一个实现为Int的数组,另一个实现为Float的数组。如果只需要访问Int字段,RDD的指针可以只访问Int数组,避免了对整个数据结构的扫描。
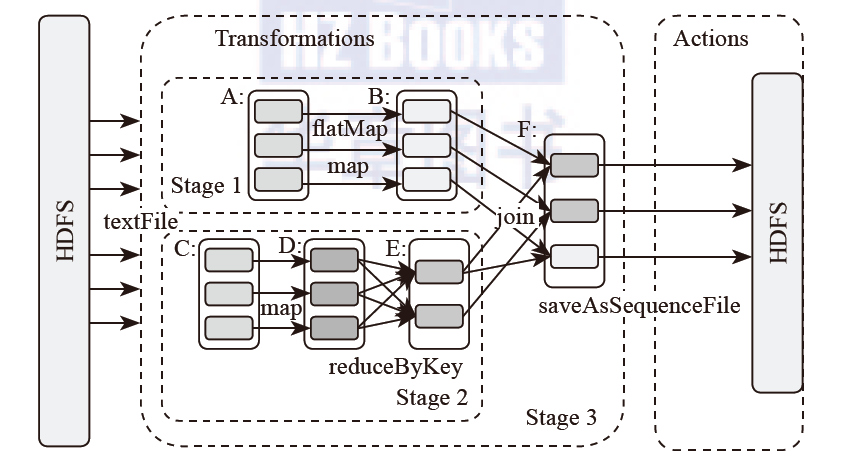
下图是不是有问题?stage1->stage2->stage3不是有依赖关系的吗?这个图显示的完全就是stage1和stage2是并行运行的啊!!!没有任何显示说明stage2有复用stage1的计算结果