

spark sql
sparksql结合hive最佳实践
一、Spark SQL快速上手
1、Spark SQL是什么
Spark SQL 是一个用来处理结构化数据的spark组件。它提供了一个叫做DataFrames的可编程抽象数据模型,并且可被视为一个分布式的SQL查询引擎。
2、Spark SQL的基础数据模型-----DataFrames
DataFrame是由“命名列”(类似关系表的字段定义)所组织起来的一个分布式数据集合。你可以把它看成是一个关系型数据库的表。
DataFrame可以通过多种来源创建:结构化数据文件,hive的表,外部数据库,或者RDDs
3、Spark SQL如何使用
首先,利用sqlContext从外部数据源加载数据为DataFrame
然后,利用DataFrame上丰富的api进行查询、转换
最后,将结果进行展现或存储为各种外部数据形式
如图所示:
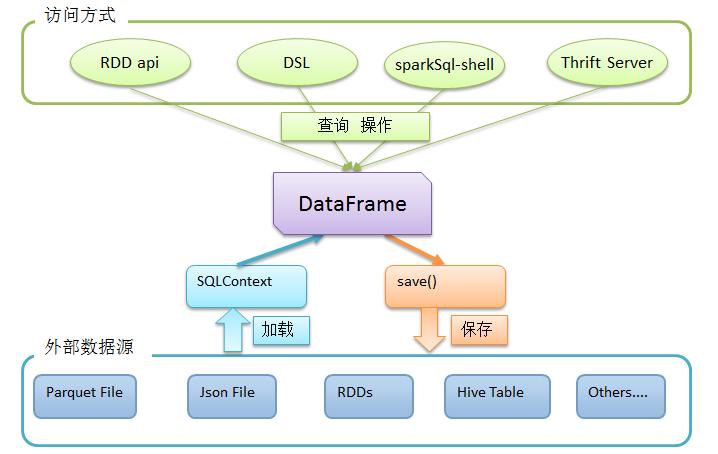
4、Spark SQL代码示例
加载数据
sqlContext支持从各种各样的数据源中创建DataFrame,内置支持的数据源有parquetFile,jsonFile,外部数据库,hive表,RDD等,另外,hbase等数据源的支持也在社区不断涌现
# 从Hive中的users表构造DataFrame
users = sqlContext.table("users")
# 加载S3上的JSON文件
logs = sqlContext.load("s3n://path/to/data.json", "json")
# 加载HDFS上的Parquet文件
clicks = sqlContext.load("hdfs://path/to/data.parquet", "parquet")
# 通过JDBC访问MySQL
comments = sqlContext.jdbc("jdbc:mysql://localhost/comments", "user")
# 将普通RDD转变为DataFrame
rdd = sparkContext.textFile("article.txt") \
.flatMap(_.split(" ")) \
.map((_, 1)) \
.reduceByKey(_+_) \
wordCounts = sqlContext.createDataFrame(rdd, ["word", "count"])
# 将本地数据容器转变为DataFrame
data = [("Alice", 21), ("Bob", 24)]
people = sqlContext.createDataFrame(data, ["name", "age"])
使用DataFrame
Spark DataFrame提供了一整套用于操纵数据的DSL。这些DSL在语义上与SQL关系查询非常相近(这也是Spark SQL能够为DataFrame提供无缝支持的重要原因之一)。以下是一组用户数据分析示例:
# 创建一个只包含年龄小于21岁用户的DataFrame
young = users.filter(users.age < 21)
# 也可以使用Pandas风格的语法
young = users[users.age < 21]
# 将所有人的年龄加1
young.select(young.name, young.age + 1)
# 统计年轻用户中各性别人数
young.groupBy("gender").count()
# 将所有年轻用户与另一个名为logs的DataFrame联接起来
young.join(logs, logs.userId == users.userId, "left_outer")
除DSL以外,我们当然也可以使用熟悉的SQL来处理DataFrame:
young.registerTempTable("young")
sqlContext.sql("SELECT count(*) FROM young")
保存结果
对数据的分析完成之后,可以将结果保存在多种形式的外部存储中
# 追加至HDFS上的Parquet文件
young.save(path="hdfs://path/to/data.parquet", source="parquet", mode="append")
# 覆写S3上的JSON文件
young.save(path="s3n://path/to/data.json", source="json",mode="append")
# 保存为Hive的内部表
young.saveAsTable(tableName="young", source="parquet" mode="overwrite")
# 转换为Pandas DataFrame(Python API特有功能)
pandasDF = young.toPandas()
# 以表格形式打印输出
young.show()
二、SparkSQL操作Hive中的表数据
spark可以通过读取hive的元数据来兼容hive,读取hive的表数据,然后在spark引擎中进行sql统计分析,从而,通过sparksql与hive结合实现数据分析将成为一种最佳实践。详细实现步骤如下:
1、启动hive的元数据服务
hive可以通过服务的形式对外提供元数据读写操作,通过简单的配置即可
编辑 $HIVE_HOME/conf/hive-site.xml,增加如下内容:
<property>
<name>hive.metastore.uris</name>
<value>thrift:// hdp-node-01:9083</value>
</property>
启动hive metastore
[hadoop@hdp-node-01 ~]${HIVE_HOME}/bin/hive --service metastore 1>/dev/null 2>&1 &
查看 metastore:
[hadoop@hdp-node-01 ~] jobs
[1]+ Running hive --service metastore &
2、spark配置
将hive的配置文件拷贝给spark
将 $HIVE_HOME/conf/hive-site.xml copy或者软链 到 $SPARK_HOME/conf/
将mysql的jdbc驱动包拷贝给spark
将 $HIVE_HOME/lib/mysql-connector-java-5.1.12.jar copy或者软链到$SPARK_HOME/lib/
3、启动spark-sql的shell交互界面
spark-sql已经集成在spark-shell中,因此,只要启动spark-shell,就可以使用spakr-sql的shell交互接口:
[hadoop@hdp-node-01 spark] bin/spark-shell --master spark://hdp-node-01:7077
或者,可以启动spark-sql界面,使用起来更方便
[hadoop@hdp-node-01 spark] bin/spark-sql --master spark://hdp-node-01:7077
4、在交互界面输入sql进行查询
注:以下所用到的库和表,都是已经在hive中存在的库和表
如果在spark-shell中执行sql查询,使用sqlContext对象调用sql()方法
scala> sqlContext.sql("select remote_addr from dw_weblog.t_ods_detail group by remote_addr").collect.foreach(println)
如果是在spark-sql中执行sql查询,则可以直接输入sql语句
scala> show databases
scala> use dw_weblog
scala> select remote_addr from dw_weblog.t_ods_detail group by remote_addr
5、在IDEA中编写代码使用hive-sql
如下所示:
val hiveContext = new HiveContext(sc)
import hiveContext.implicits._
import hiveContext.sql
//指定库
sql("use dw_weblog")
//执行标准sql语句
sql("create table sparksql as select remote_addr,count(*) from t_ods_detail group by remote_addr")
……
综上所述,sparksql类似于hive,可以支持sql语法来对海量数据进行分析查询,跟hive不同的是,hive执行sql任务的底层运算引擎采用mapreduce运算框架,而sparksql执行sql任务的运算引擎是spark core,从而充分利用spark内存计算及DAG模型的优势,大幅提升海量数据的分析查询速度

