分布式kv存储系统之etcd集群管理
 leader选举过程是这样的;首先candidate向集群其他候选节点(condidate角色的节点)发送投票信息(Request Vote),默认是投票给自己;各候选节点相互收到另外的节点的投票信息,会对比日志是否比自己的更新,如果比自己的更新,则将自己的选票投给目的候选人,并回复一个包含自己最新日志信息的响应消息;经过上述的投票,最终会有一个节点获取多数投票(超过集群节点数的一半),即这个节点就被当选为leader代表集群工作;即该节点会从candidate角色转换为leader;成为leader的的节点会定时发送自己的心跳信息,以此来维护自己leader的地位(默认是每100ms发送一次);其他节点收到leader发送的心跳信息后,会将自己的状态从candidate转换为follower状态,然后从leader节点同步数据到本地;
leader选举过程是这样的;首先candidate向集群其他候选节点(condidate角色的节点)发送投票信息(Request Vote),默认是投票给自己;各候选节点相互收到另外的节点的投票信息,会对比日志是否比自己的更新,如果比自己的更新,则将自己的选票投给目的候选人,并回复一个包含自己最新日志信息的响应消息;经过上述的投票,最终会有一个节点获取多数投票(超过集群节点数的一半),即这个节点就被当选为leader代表集群工作;即该节点会从candidate角色转换为leader;成为leader的的节点会定时发送自己的心跳信息,以此来维护自己leader的地位(默认是每100ms发送一次);其他节点收到leader发送的心跳信息后,会将自己的状态从candidate转换为follower状态,然后从leader节点同步数据到本地;
etcd简介
etcd是CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,etcd基于Go语言实现。
官方网站:https://etcd.io/;
github地址:https://github.com/etcd-io/etcd;
官方硬件推荐:https://etcd.io/docs/v3.5/op-guide/hardware/;
官方文档:https://etcd.io/docs/v3.5/op-guide/maintenance/;
手动二进制部署etcd集群可以参考本人博客:https://www.cnblogs.com/qiuhom-1874/p/14349964.html;
etcd集群属性
1、完全复制:所谓完全复制是指每个节点的数据都是从主节点同步过来的,每个节点的数据都是一摸一样的,这种基于主节点复制同步数据的集群我们称为复制或镜像集群,即集群成员的数据一摸一样;除了这种集群之外,常见的还有另一种集群,集群成员之间各自保存整个集群数据的一部分,例如redis cluster;
2、高可用性:所谓高可用性是指集群在发生网络分区以后,etcd能够自动进行选举,选出能够代表集群工作的leader,从而实现服务的高可用性,避免硬件的单点故障或网络问题;
3、一致性:所谓一致性是指客户端每次读取数据都会返回跨多主机的最新写入;数据读取是可以从集群任意节点进行读取,数据写入只能由leader完成,然后通知集群成员进行数据同步;
4、简单:包括一个定义良好、面向用户的API(gRPC);
5、安全:实现了带有可选的客户端证书身份验证的自动化TLS;
6、快速:每秒10000次写入的基准速度;
7、 可靠:使用Raft算法实现了存储的合理分布etcd的工作原理;
etcd集群选举过程
选举算法Raft简介
Raft算法是由斯坦福大学的Diego Ongaro(迭戈·翁加罗)和John Ousterhout(约翰·欧斯特霍特)于2013年提出的,在Raft算法之前,Paxos算法是最著名的分布式一致性算法,但Paxos算法的理论和实现都比较复杂,不太容易理解和实现,因此,以上两位大神就提出了Raft算法,旨在解决Paxos算法存在的一些问题,如难以理解、难以实现、可扩展性有限等。Raft算法的设计目标是提供更好的可读性、易用性和可靠性,以便工程师能够更好地理解和实现它,它采用了Paxos算法中的一些核心思想,但通过简化和修改,使其更容易理解和实现,Raft算法的设计理念是使算法尽可能简单化,以便于人们理解和维护,同时也能够提供强大的一致性保证和高可用性。 etcd基于Raft算法进行集群角色选举,使用Raft的还有Consul、InfluxDB、kafka(KRaft)等。
etcd节点角色和相关术语
集群中每个节点只能处于 Leader、Follower 和 Candidate 三种状态的一种;
follower:追随者(Redis Cluster的Slave节点);
candidate:候选节点,选举过程中。
leader:主节点(Redis Cluster的Master节点);
termID(任期ID):termID是一个整数默认值为0,在Raft算法中,一个term代表leader的一段任期周期,每当一个节点成为leader时,就会进入一个新的term, 然后每个节点都会在自己的term ID上加1,以便与上一轮选举区分开来。
etcd角色转换
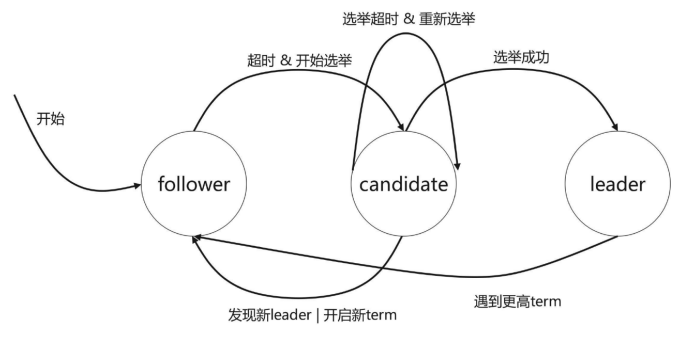
提示:上图描述了etcd集群各节点选举角色转换图;首次选举,各etcd节点启动后默认是follower角色,默认termID为0;如果发现集群内没有leader,则所有节点都会从follower角色转变为 candidate角色进行leader选举;leader选举过程是这样的;首先candidate向集群其他候选节点(condidate角色的节点)发送投票信息(Request Vote),默认是投票给自己;各候选节点相互收到另外的节点的投票信息,会对比日志是否比自己的更新,如果比自己的更新,则将自己的选票投给目的候选人,并回复一个包含自己最新日志信息的响应消息;经过上述的投票,最终会有一个节点获取多数投票(超过集群节点数的一半),即这个节点就被当选为leader代表集群工作;即该节点会从candidate角色转换为leader;成为leader的的节点会定时发送自己的心跳信息,以此来维护自己leader的地位(默认是每100ms发送一次);其他节点收到leader发送的心跳信息后,会将自己的状态从candidate转换为follower状态,然后从leader节点同步数据到本地;如果选举超时,则重新选举,如果选出来两个leader,则超过集群总数的一半选票leader代表集群工作;如果当一个follower节点再规定时间内未收到leader的心跳时,它会从follower状态转变为candidate状态,并向其他节点发送投票请求(自己的term ID和日志更新记录)并等待其他节点的响应,如果该candidate的(日志更新记录最新),则会获多数投票,它将成为新的leader。新的leader将自己的termID +1 并通告至其它节点,并定期向其他节点通告自己的心跳信息。如果leader挂了,那么对应leader的状态不会发生变化,只有leader再次恢复加入集群,它发现有更高的term,此时该leader会将自己的角色转换为follower,然后加入到已有的leader中并将自己的term ID更新为和当前leader一致,在同一个任期内所有节点的term ID是一致的;
etcd集群优化
etcd的配置是基于选项传递参数的方式来达到配置etcd的目的,如下,etcd service文件内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | root@k8s-etcd01:~# cat /etc/systemd/system/etcd.service[Unit]Description=Etcd ServerAfter=network.targetAfter=network-online.targetWants=network-online.targetDocumentation=https://github.com/coreos[Service]Type=notifyWorkingDirectory=/var/lib/etcdExecStart=/usr/local/bin/etcd \ --name=etcd-192.168.0.37 \ --cert-file=/etc/kubernetes/ssl/etcd.pem \ --key-file=/etc/kubernetes/ssl/etcd-key.pem \ --peer-cert-file=/etc/kubernetes/ssl/etcd.pem \ --peer-key-file=/etc/kubernetes/ssl/etcd-key.pem \ --trusted-ca-file=/etc/kubernetes/ssl/ca.pem \ --peer-trusted-ca-file=/etc/kubernetes/ssl/ca.pem \ --initial-advertise-peer-urls=https://192.168.0.37:2380 \ --listen-peer-urls=https://192.168.0.37:2380 \ --listen-client-urls=https://192.168.0.37:2379,http://127.0.0.1:2379 \ --advertise-client-urls=https://192.168.0.37:2379 \ --initial-cluster-token=etcd-cluster-0 \ --initial-cluster=etcd-192.168.0.37=https://192.168.0.37:2380,etcd-192.168.0.38=https://192.168.0.38:2380,etcd-192.168.0.39=https://192.168.0.39:2380 \ --initial-cluster-state=new \ --data-dir=/var/lib/etcd \ --wal-dir= \ --snapshot-count=50000 \ --auto-compaction-retention=1 \ --auto-compaction-mode=periodic \ --max-request-bytes=10485760 \ --quota-backend-bytes=8589934592Restart=alwaysRestartSec=15LimitNOFILE=65536OOMScoreAdjust=-999[Install]WantedBy=multi-user.targetroot@k8s-etcd01:~# |
提示:当然我们也可以使用配置文件的方式向etcd.service提供环境变量文件的方式来配置etcd,最终都是向etcd传递参数;其中--name这个参数,在集群一个etcd集群中每个节点的名字是唯一的,因为etcd通过这个名称来识别集群成员;--cert-file和--key-file选项是用来指定对应节点的etcd的证书和私钥;即用于外部客户端连接etcd集群对客户端认证用的;--peer-cert-file 和--peer-key-file是用来指定集群成员通信时用到的证书和私钥,主要用来验证集群成员节点的;--trusted-ca-file用来指定签发外部客户端证书的ca证书;--peer-trusted-ca-file用于指定为集群成员签发证书的ca证书;--initial-advertise-peer-urls用于指定自己的集群端口;--listen-peer-urls用于指定集群节点之间通信端口;--listen-client-urls用于指定客户端访问地址;--advertise-client-urls用于指定向集群节点通告自己客户端的地址;--initial-cluster-token用于指定创建集群使用的token信息;一个集群内的节点保持一致; --initial-cluster用于指定集群全部节点成员信息;--initial-cluster-state用于指定集群状态,如果是new,则表示是新建集群,如果是existing则表示集群已存在;--data-dir用于指定etcd保存数据的目录;
集群优化
--max-request-bytes=10485760 #request size limit(请求的最大字节数,默认一个key最大1.5Mib,官方推荐最大不要超出10Mib);
--quota-backend-bytes=8589934592 #storage size limit(磁盘存储空间大小限制,默认为2G,此值超过8G启动会有警告信息);
基于etcdctl客户端工具管理etcd中的数据
集群碎片整理
1 2 3 4 5 6 | ETCDCTL_API=3 /usr/local/bin/etcdctl defrag \--cluster \--endpoints=https://192.168.0.37:2379 \--cacert=/etc/kubernetes/ssl/ca.pem \--cert=/etc/kubernetes/ssl/etcd.pem \--key=/etc/kubernetes/ssl/etcd-key.pem |

提示:etcd有多个不同的API访问版本,v1版本已经废弃,etcd v2 和 v3 本质上是共享同一套 raft 协议代码的两个独立的应用,接口不一样,存储不一样,数据互相隔离。也就是说如果从 Etcd v2 升级到 Etcd v3,原来v2 的数据还是只能用 v2 的接口访问,v3 的接口创建的数据也只能访问通过v3 的接口访问。当然现在默认是v3版本,如果要使用v2版本可以使用ETCDCTL_API环境变量来指定对应API版本号;
列出成员列表
1 2 3 4 5 | etcdctl --write-out=table member list \--endpoints=https://192.168.0.37:2379 \--cacert=/etc/kubernetes/ssl/ca.pem \--cert=/etc/kubernetes/ssl/etcd.pem \--key=/etc/kubernetes/ssl/etcd-key.pem |

验证节点心跳状态
1 2 3 4 5 6 7 | export NODE_IPS="192.168.0.37 192.168.0.38 192.168.0.39"for ip in ${NODE_IPS};do /usr/local/bin/etcdctl --write-out=table \--endpoints=https://${ip}:2379 \--cacert=/etc/kubernetes/ssl/ca.pem \--cert=/etc/kubernetes/ssl/etcd.pem \--key=/etc/kubernetes/ssl/etcd-key.pem \endpoint health; done |
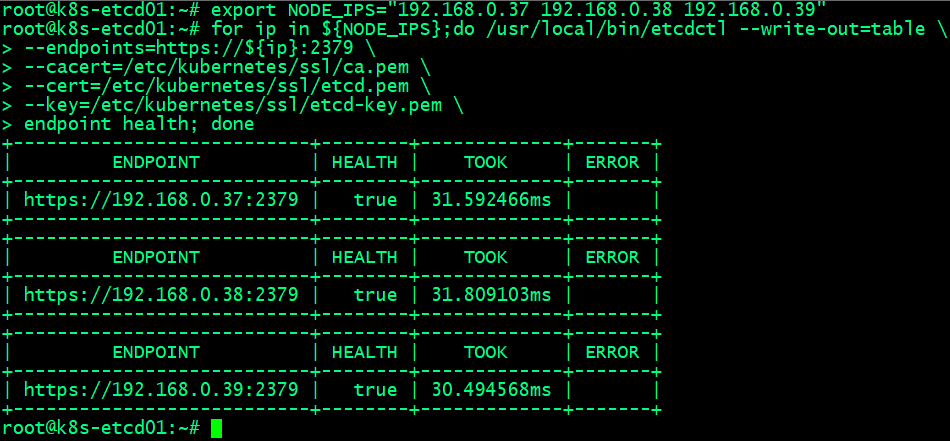
查看etcd集群详细信息
1 2 3 4 5 6 7 | export NODE_IPS="192.168.0.37 192.168.0.38 192.168.0.39"for ip in ${NODE_IPS};do /usr/local/bin/etcdctl --write-out=table \--endpoints=https://${ip}:2379 \--cacert=/etc/kubernetes/ssl/ca.pem \--cert=/etc/kubernetes/ssl/etcd.pem \--key=/etc/kubernetes/ssl/etcd-key.pem \endpoint status; done |
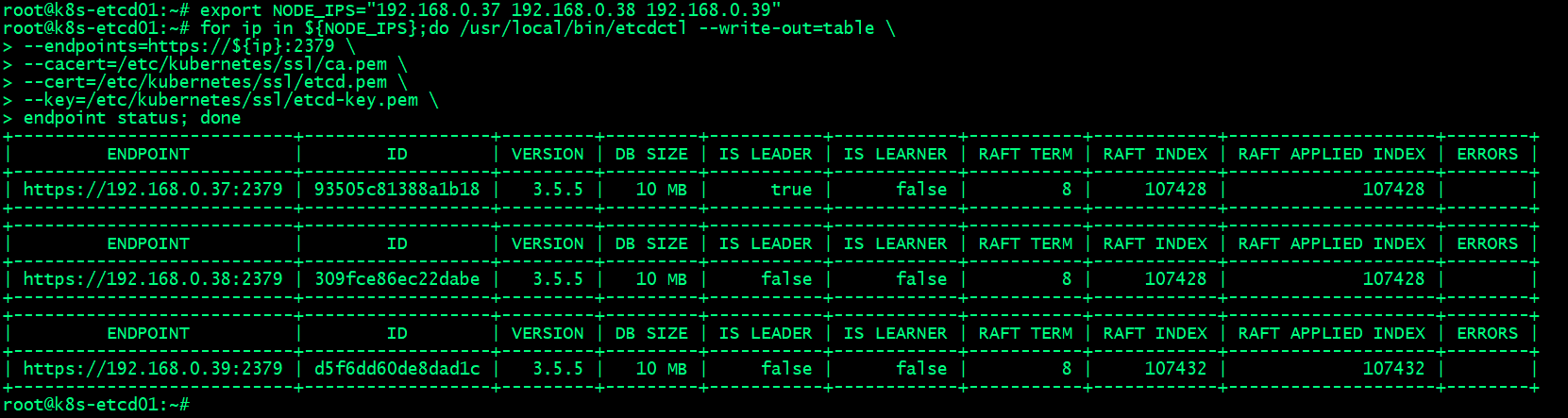
查看etcd数据
查看etcd所有key的信息
1 | root@k8s-etcd01:~# etcdctl get / --prefix --keys-only |

查看pod信息
1 2 3 | root@k8s-etcd01:~# etcdctl get / --prefix --keys-only |grep pods/registry/pods/argocd/devops-argocd-application-controller-0/registry/pods/argocd/devops-argocd-applicationset-controller-76f8bfb488-l7s95 |
查看namespace信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | root@k8s-etcd01:~# etcdctl get / --prefix --keys-only |grep namespaces/registry/namespaces/argocd/registry/namespaces/default/registry/namespaces/kube-node-lease/registry/namespaces/kube-public/registry/namespaces/kube-system/registry/namespaces/kubernetes-dashboard/registry/namespaces/kubesphere-controls-system/registry/namespaces/kubesphere-devops-system/registry/namespaces/kubesphere-logging-system/registry/namespaces/kubesphere-monitoring-federated/registry/namespaces/kubesphere-monitoring-system/registry/namespaces/kubesphere-system/registry/namespaces/kuboard/registry/namespaces/nfsroot@k8s-etcd01:~# |
查看deployment控制器信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | root@k8s-etcd01:~# etcdctl get / --prefix --keys-only |grep deployments/registry/deployments/argocd/devops-argocd-applicationset-controller/registry/deployments/argocd/devops-argocd-dex-server/registry/deployments/argocd/devops-argocd-notifications-controller/registry/deployments/argocd/devops-argocd-redis/registry/deployments/argocd/devops-argocd-repo-server/registry/deployments/argocd/devops-argocd-server/registry/deployments/kube-system/calico-kube-controllers/registry/deployments/kube-system/coredns/registry/deployments/kubernetes-dashboard/dashboard-metrics-scraper/registry/deployments/kubernetes-dashboard/kubernetes-dashboard/registry/deployments/kubesphere-controls-system/default-http-backend/registry/deployments/kubesphere-controls-system/kubectl-admin/registry/deployments/kubesphere-logging-system/fluentbit-operator/registry/deployments/kubesphere-logging-system/logsidecar-injector-deploy/registry/deployments/kubesphere-monitoring-system/kube-state-metrics/registry/deployments/kubesphere-monitoring-system/prometheus-operator/registry/deployments/kubesphere-system/ks-apiserver/registry/deployments/kubesphere-system/ks-console/registry/deployments/kubesphere-system/ks-controller-manager/registry/deployments/kubesphere-system/ks-installer/registry/deployments/kubesphere-system/minio/registry/deployments/kubesphere-system/redis/registry/deployments/kuboard/kuboard-v3/registry/deployments/nfs/nfs-client-provisionerroot@k8s-etcd01:~# |
查看calico组件信息
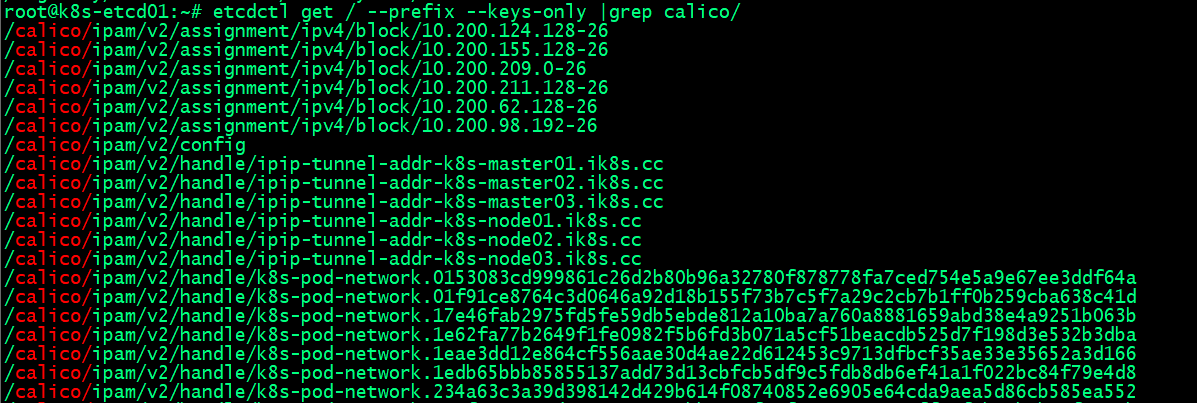
etcd增删改查
添加数据
1 2 3 | root@k8s-etcd01:~# etcdctl put /name "tom"OKroot@k8s-etcd01:~# |
查询数据
1 2 3 4 | root@k8s-etcd01:~# etcdctl get /name/nametomroot@k8s-etcd01:~# |
修改数据
1 2 3 4 5 6 | root@k8s-etcd01:~# etcdctl put /name "jerry"OKroot@k8s-etcd01:~# etcdctl get /name /namejerryroot@k8s-etcd01:~# |
提示:修改数据是直接通过对key的值覆盖来更新数据;
删除数据
1 2 3 4 | root@k8s-etcd01:~# etcdctl del /name1root@k8s-etcd01:~# etcdctl get /nameroot@k8s-etcd01:~# |
etcd数据watch机制
etcd数据watch机制是指基于不断监看数据,发生变化就主动触发通知客户端,Etcd v3 的watch机制支持watch某个固定的key,也支持watch一个范围。

etcd V3 API版本数据备份与恢复
WAL是write ahead log的缩写(预写日志);所谓预写日志是指在执行真正的写操作之前先写一个日志,这个和mysql的bin-log类似;在etcd中,所有数据的修改在提交前,都要先写入到WAL中。wal最大的作用就是记录整个数据变化的全部历程;
V3版本备份数据
1 2 3 4 5 6 7 8 9 10 | root@k8s-etcd01:~# mkdir -p /dataroot@k8s-etcd01:~# etcdctl snapshot save /data/snapshot.db{"level":"info","ts":"2023-04-26T14:54:43.081Z","caller":"snapshot/v3_snapshot.go:65","msg":"created temporary db file","path":"/data/snapshot.db.part"}{"level":"info","ts":"2023-04-26T14:54:43.093Z","logger":"client","caller":"v3/maintenance.go:211","msg":"opened snapshot stream; downloading"}{"level":"info","ts":"2023-04-26T14:54:43.094Z","caller":"snapshot/v3_snapshot.go:73","msg":"fetching snapshot","endpoint":"127.0.0.1:2379"}{"level":"info","ts":"2023-04-26T14:54:43.379Z","logger":"client","caller":"v3/maintenance.go:219","msg":"completed snapshot read; closing"}{"level":"info","ts":"2023-04-26T14:54:43.409Z","caller":"snapshot/v3_snapshot.go:88","msg":"fetched snapshot","endpoint":"127.0.0.1:2379","size":"10 MB","took":"now"}{"level":"info","ts":"2023-04-26T14:54:43.409Z","caller":"snapshot/v3_snapshot.go:97","msg":"saved","path":"/data/snapshot.db"}Snapshot saved at /data/snapshot.dbroot@k8s-etcd01:~# |
V3版本恢复数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | root@k8s-etcd01:~# etcdctl snapshot restore /data/snapshot.db --data-dir=/opt/etcd-testdirDeprecated: Use `etcdutl snapshot restore` instead.2023-04-26T14:56:51Z info snapshot/v3_snapshot.go:248 restoring snapshot {"path": "/data/snapshot.db", "wal-dir": "/opt/etcd-testdir/member/wal", "data-dir": "/opt/etcd-testdir", "snap-dir": "/opt/etcd-testdir/member/snap", "stack": "go.etcd.io/etcd/etcdutl/v3/snapshot.(*v3Manager).Restore\n\t/tmp/etcd-release-3.5.5/etcd/release/etcd/etcdutl/snapshot/v3_snapshot.go:254\ngo.etcd.io/etcd/etcdutl/v3/etcdutl.SnapshotRestoreCommandFunc\n\t/tmp/etcd-release-3.5.5/etcd/release/etcd/etcdutl/etcdutl/snapshot_command.go:147\ngo.etcd.io/etcd/etcdctl/v3/ctlv3/command.snapshotRestoreCommandFunc\n\t/tmp/etcd-release-3.5.5/etcd/release/etcd/etcdctl/ctlv3/command/snapshot_command.go:129\ngithub.com/spf13/cobra.(*Command).execute\n\t/usr/local/google/home/siarkowicz/.gvm/pkgsets/go1.16.15/global/pkg/mod/github.com/spf13/cobra@v1.1.3/command.go:856\ngithub.com/spf13/cobra.(*Command).ExecuteC\n\t/usr/local/google/home/siarkowicz/.gvm/pkgsets/go1.16.15/global/pkg/mod/github.com/spf13/cobra@v1.1.3/command.go:960\ngithub.com/spf13/cobra.(*Command).Execute\n\t/usr/local/google/home/siarkowicz/.gvm/pkgsets/go1.16.15/global/pkg/mod/github.com/spf13/cobra@v1.1.3/command.go:897\ngo.etcd.io/etcd/etcdctl/v3/ctlv3.Start\n\t/tmp/etcd-release-3.5.5/etcd/release/etcd/etcdctl/ctlv3/ctl.go:107\ngo.etcd.io/etcd/etcdctl/v3/ctlv3.MustStart\n\t/tmp/etcd-release-3.5.5/etcd/release/etcd/etcdctl/ctlv3/ctl.go:111\nmain.main\n\t/tmp/etcd-release-3.5.5/etcd/release/etcd/etcdctl/main.go:59\nruntime.main\n\t/usr/local/google/home/siarkowicz/.gvm/gos/go1.16.15/src/runtime/proc.go:225"}2023-04-26T14:56:51Z info membership/store.go:141 Trimming membership information from the backend...2023-04-26T14:56:51Z info membership/cluster.go:421 added member {"cluster-id": "cdf818194e3a8c32", "local-member-id": "0", "added-peer-id": "8e9e05c52164694d", "added-peer-peer-urls": ["http://localhost:2380"]}2023-04-26T14:56:51Z info snapshot/v3_snapshot.go:269 restored snapshot {"path": "/data/snapshot.db", "wal-dir": "/opt/etcd-testdir/member/wal", "data-dir": "/opt/etcd-testdir", "snap-dir": "/opt/etcd-testdir/member/snap"}root@k8s-etcd01:~# ll /opt/etcd-testdir/total 12drwx------ 3 root root 4096 Apr 26 14:56 ./drwxr-xr-x 3 root root 4096 Apr 26 14:56 ../drwx------ 4 root root 4096 Apr 26 14:56 member/root@k8s-etcd01:~# ll /opt/etcd-testdir/member/total 16drwx------ 4 root root 4096 Apr 26 14:56 ./drwx------ 3 root root 4096 Apr 26 14:56 ../drwx------ 2 root root 4096 Apr 26 14:56 snap/drwx------ 2 root root 4096 Apr 26 14:56 wal/root@k8s-etcd01:~# ll /opt/etcd-testdir/member/wal/total 62508drwx------ 2 root root 4096 Apr 26 14:56 ./drwx------ 4 root root 4096 Apr 26 14:56 ../-rw------- 1 root root 64000000 Apr 26 14:56 0000000000000000-0000000000000000.walroot@k8s-etcd01:~# |
提示:恢复的目录必须为空目录,否者会报错对应目录不为空;
自动备份脚本
1 2 3 4 5 6 7 8 | root@k8s-etcd01:~# cat etcd-backup.sh#!/bin/bashsource /etc/profileDATE=`date +%Y-%m-%d_%H-%M-%S`DATA_DIR="/data/etcd-backup-dir/"/usr/bin/mkdir -p ${DATA_DIR}ETCDCTL_API=3 /usr/local/bin/etcdctl snapshot save ${DATA_DIR}etcd-snapshot-${DATE}.dbroot@k8s-etcd01:~# |
测试:执行备份脚本,看看对应数据是否能够正常备份?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | root@k8s-etcd01:~# bash etcd-backup.sh{"level":"info","ts":"2023-04-26T15:15:58.341Z","caller":"snapshot/v3_snapshot.go:65","msg":"created temporary db file","path":"/data/etcd-backup-dir/etcd-snapshot-2023-04-26_15-15-58.db.part"}{"level":"info","ts":"2023-04-26T15:15:58.346Z","logger":"client","caller":"v3/maintenance.go:211","msg":"opened snapshot stream; downloading"}{"level":"info","ts":"2023-04-26T15:15:58.346Z","caller":"snapshot/v3_snapshot.go:73","msg":"fetching snapshot","endpoint":"127.0.0.1:2379"}{"level":"info","ts":"2023-04-26T15:15:58.585Z","logger":"client","caller":"v3/maintenance.go:219","msg":"completed snapshot read; closing"}{"level":"info","ts":"2023-04-26T15:15:58.608Z","caller":"snapshot/v3_snapshot.go:88","msg":"fetched snapshot","endpoint":"127.0.0.1:2379","size":"10 MB","took":"now"}{"level":"info","ts":"2023-04-26T15:15:58.609Z","caller":"snapshot/v3_snapshot.go:97","msg":"saved","path":"/data/etcd-backup-dir/etcd-snapshot-2023-04-26_15-15-58.db"}Snapshot saved at /data/etcd-backup-dir/etcd-snapshot-2023-04-26_15-15-58.dbroot@k8s-etcd01:~# ll /data/etcd-backup-dir/total 10096drwxr-xr-x 2 root root 4096 Apr 26 15:15 ./drwxr-xr-x 3 root root 4096 Apr 26 15:15 ../-rw------- 1 root root 10326048 Apr 26 15:15 etcd-snapshot-2023-04-26_15-15-58.dbroot@k8s-etcd01:~# |
提示:上述脚本只适用于etcd本机执行备份操作,如果需要远程执行备份操作,需要指定对应证书相关文件;
基于kubeasz对etcd进行数据备份及恢复,并验证etcd集群一leader多follower
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | root@k8s-deploy:/etc/kubeasz# cat playbooks/94.backup.yml# cluster-backup playbook# read the guide: 'op/cluster_restore.md'- hosts: - localhost tasks: # step1: find a healthy member in the etcd cluster - name: set NODE_IPS of the etcd cluster set_fact: NODE_IPS="{% for host in groups['etcd'] %}{{ host }} {% endfor %}" - name: get etcd cluster status shell: 'for ip in {{ NODE_IPS }};do \ ETCDCTL_API=3 {{ base_dir }}/bin/etcdctl \ --endpoints=https://"$ip":2379 \ --cacert={{ cluster_dir }}/ssl/ca.pem \ --cert={{ cluster_dir }}/ssl/etcd.pem \ --key={{ cluster_dir }}/ssl/etcd-key.pem \ endpoint health; \ done' register: ETCD_CLUSTER_STATUS ignore_errors: true - debug: var="ETCD_CLUSTER_STATUS" - name: get a running ectd node shell: 'echo -e "{{ ETCD_CLUSTER_STATUS.stdout }}" \ "{{ ETCD_CLUSTER_STATUS.stderr }}" \ |grep "is healthy"|sed -n "1p"|cut -d: -f2|cut -d/ -f3' register: RUNNING_NODE - debug: var="RUNNING_NODE.stdout" - name: get current time shell: "date +'%Y%m%d%H%M'" register: timestamp # step2: backup data to the ansible node - name: make a backup on the etcd node shell: "mkdir -p {{ cluster_dir }}/backup && cd {{ cluster_dir }}/backup && \ ETCDCTL_API=3 {{ base_dir }}/bin/etcdctl \ --endpoints=https://{{ RUNNING_NODE.stdout }}:2379 \ --cacert={{ cluster_dir }}/ssl/ca.pem \ --cert={{ cluster_dir }}/ssl/etcd.pem \ --key={{ cluster_dir }}/ssl/etcd-key.pem \ snapshot save snapshot_{{ timestamp.stdout }}.db" args: warn: false - name: update the latest backup shell: 'cd {{ cluster_dir }}/backup/ && /bin/cp -f snapshot_{{ timestamp.stdout }}.db snapshot.db'root@k8s-deploy:/etc/kubeasz# |
提示:上述是kubeasz备份k8s集群数据所需做的操作;从上面的信息可以看到,kubeasz备份k8s集群数据,将备份文件存放在{{ cluster_dir }}/backup,即/etc/kubeasz/clusters/k8s-cluster01/backup目录下;
kubeasz备份k8s集群数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | root@k8s-deploy:~# cd /etc/kubeasz/root@k8s-deploy:/etc/kubeasz# ./ezctl backup k8s-cluster01ansible-playbook -i clusters/k8s-cluster01/hosts -e @clusters/k8s-cluster01/config.yml playbooks/94.backup.yml2023-04-26 15:19:38 INFO cluster:k8s-cluster01 backup begins in 5s, press any key to abort:PLAY [localhost] **************************************************************************************************************************************TASK [Gathering Facts] ********************************************************************************************************************************ok: [localhost]TASK [set NODE_IPS of the etcd cluster] ***************************************************************************************************************ok: [localhost]TASK [get etcd cluster status] ************************************************************************************************************************changed: [localhost]TASK [debug] ******************************************************************************************************************************************ok: [localhost] => { "ETCD_CLUSTER_STATUS": { "changed": true, "cmd": "for ip in 192.168.0.37 192.168.0.38 192.168.0.39 ;do ETCDCTL_API=3 /etc/kubeasz/bin/etcdctl --endpoints=https://\"$ip\":2379 --cacert=/etc/kubeasz/clusters/k8s-cluster01/ssl/ca.pem --cert=/etc/kubeasz/clusters/k8s-cluster01/ssl/etcd.pem --key=/etc/kubeasz/clusters/k8s-cluster01/ssl/etcd-key.pem endpoint health; done", "delta": "0:00:00.460786", "end": "2023-04-26 15:19:51.367059", "failed": false, "rc": 0, "start": "2023-04-26 15:19:50.906273", "stderr": "", "stderr_lines": [], "stdout": "https://192.168.0.37:2379 is healthy: successfully committed proposal: took = 36.574257ms\nhttps://192.168.0.38:2379 is healthy: successfully committed proposal: took = 33.589094ms\nhttps://192.168.0.39:2379 is healthy: successfully committed proposal: took = 31.259782ms", "stdout_lines": [ "https://192.168.0.37:2379 is healthy: successfully committed proposal: took = 36.574257ms", "https://192.168.0.38:2379 is healthy: successfully committed proposal: took = 33.589094ms", "https://192.168.0.39:2379 is healthy: successfully committed proposal: took = 31.259782ms" ] }}TASK [get a running ectd node] ************************************************************************************************************************changed: [localhost]TASK [debug] ******************************************************************************************************************************************ok: [localhost] => { "RUNNING_NODE.stdout": "192.168.0.37"}TASK [get current time] *******************************************************************************************************************************changed: [localhost]TASK [make a backup on the etcd node] *****************************************************************************************************************changed: [localhost]TASK [update the latest backup] ***********************************************************************************************************************changed: [localhost]PLAY RECAP ********************************************************************************************************************************************localhost : ok=9 changed=5 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 root@k8s-deploy:/etc/kubeasz# |
查看备份数据文件
1 2 3 4 5 6 7 | root@k8s-deploy:/etc/kubeasz# ll clusters/k8s-cluster01/backup/total 20184drwxr-xr-x 2 root root 4096 Apr 26 15:19 ./drwxr-xr-x 5 root root 4096 Apr 22 14:57 ../-rw------- 1 root root 10326048 Apr 26 15:19 snapshot.db-rw------- 1 root root 10326048 Apr 26 15:19 snapshot_202304261519.dbroot@k8s-deploy:/etc/kubeasz# |
验证:删除k8s中的pod数据,然后使用上述备份文件来恢复数据
1 2 3 4 5 6 7 8 9 10 11 12 | root@k8s-deploy:/etc/kubeasz# kubectl get pods NAME READY STATUS RESTARTS AGEtest 1/1 Running 4 (160m ago) 4d1htest1 1/1 Running 4 (160m ago) 4d1htest2 1/1 Running 4 (160m ago) 4d1hroot@k8s-deploy:/etc/kubeasz# kubectl delete pods test test1 test2pod "test" deletedpod "test1" deletedpod "test2" deletedroot@k8s-deploy:/etc/kubeasz#kubectl get pods No resources found in default namespace.root@k8s-deploy:/etc/kubeasz# |
使用kubasz来恢复数据
查看恢复文件
1 2 3 4 5 6 7 8 9 | root@k8s-deploy:/etc/kubeasz# ll clusters/k8s-cluster01/backup/total 20184drwxr-xr-x 2 root root 4096 Apr 26 15:19 ./drwxr-xr-x 5 root root 4096 Apr 22 14:57 ../-rw------- 1 root root 10326048 Apr 26 15:19 snapshot.db-rw------- 1 root root 10326048 Apr 26 15:19 snapshot_202304261519.dbroot@k8s-deploy:/etc/kubeasz# grep db_to_restore ./roles/ -R ./roles/cluster-restore/defaults/main.yml:db_to_restore: "snapshot.db"root@k8s-deploy:/etc/kubeasz# |
提示:kubeasz恢复文件是选择的是snapshot.db这个文件,这个文件和当前备份最新的文件是保持一致的,即如果你的集群有多个备份,snapshot.db是和最新备份文件是一摸一样的;
查看数据恢复任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | root@k8s-deploy:/etc/kubeasz# cat roles/cluster-restore/tasks/main.yml- name: 停止ectd 服务 service: name=etcd state=stopped- name: 清除etcd 数据目录 file: name={{ ETCD_DATA_DIR }}/member state=absent- name: 清除 etcd 备份目录 file: name={{ cluster_dir }}/backup/etcd-restore state=absent delegate_to: 127.0.0.1 run_once: true- name: etcd 数据恢复 shell: "cd {{ cluster_dir }}/backup && \ ETCDCTL_API=3 {{ base_dir }}/bin/etcdctl snapshot restore snapshot.db \ --data-dir={{ cluster_dir }}/backup/etcd-restore" delegate_to: 127.0.0.1 run_once: true- name: 分发恢复文件到 etcd 各个节点 copy: src={{ cluster_dir }}/backup/etcd-restore/member dest={{ ETCD_DATA_DIR }}- name: 重启etcd 服务 service: name=etcd state=restarted- name: 以轮询的方式等待服务同步完成 shell: "systemctl is-active etcd.service" register: etcd_status until: '"active" in etcd_status.stdout' retries: 8 delay: 8root@k8s-deploy:/etc/kubeasz# |
执行数据恢复操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 | root@k8s-deploy:/etc/kubeasz# ./ezctl restore k8s-cluster01ansible-playbook -i clusters/k8s-cluster01/hosts -e @clusters/k8s-cluster01/config.yml playbooks/95.restore.yml2023-04-26 15:48:07 INFO cluster:k8s-cluster01 restore begins in 5s, press any key to abort:PLAY [kube_master] ************************************************************************************************************************************TASK [Gathering Facts] ********************************************************************************************************************************ok: [192.168.0.32]ok: [192.168.0.33]ok: [192.168.0.31]TASK [stopping kube_master services] ******************************************************************************************************************changed: [192.168.0.31] => (item=kube-apiserver)changed: [192.168.0.33] => (item=kube-apiserver)changed: [192.168.0.32] => (item=kube-apiserver)changed: [192.168.0.31] => (item=kube-controller-manager)changed: [192.168.0.32] => (item=kube-controller-manager)changed: [192.168.0.33] => (item=kube-controller-manager)changed: [192.168.0.32] => (item=kube-scheduler)changed: [192.168.0.33] => (item=kube-scheduler)changed: [192.168.0.31] => (item=kube-scheduler)PLAY [kube_master,kube_node] **************************************************************************************************************************TASK [Gathering Facts] ********************************************************************************************************************************ok: [192.168.0.34]ok: [192.168.0.36]ok: [192.168.0.35]TASK [stopping kube_node services] ********************************************************************************************************************changed: [192.168.0.33] => (item=kubelet)changed: [192.168.0.32] => (item=kubelet)changed: [192.168.0.31] => (item=kubelet)changed: [192.168.0.34] => (item=kubelet)changed: [192.168.0.36] => (item=kubelet)changed: [192.168.0.33] => (item=kube-proxy)changed: [192.168.0.32] => (item=kube-proxy)changed: [192.168.0.31] => (item=kube-proxy)changed: [192.168.0.36] => (item=kube-proxy)changed: [192.168.0.34] => (item=kube-proxy)changed: [192.168.0.35] => (item=kubelet)changed: [192.168.0.35] => (item=kube-proxy)PLAY [etcd] *******************************************************************************************************************************************TASK [Gathering Facts] ********************************************************************************************************************************ok: [192.168.0.37]ok: [192.168.0.38]ok: [192.168.0.39]TASK [cluster-restore : 停止ectd 服务] ********************************************************************************************************************changed: [192.168.0.38]changed: [192.168.0.39]changed: [192.168.0.37]TASK [cluster-restore : 清除etcd 数据目录] ******************************************************************************************************************changed: [192.168.0.37]changed: [192.168.0.39]changed: [192.168.0.38]TASK [cluster-restore : 清除 etcd 备份目录] *****************************************************************************************************************ok: [192.168.0.37]TASK [cluster-restore : etcd 数据恢复] ********************************************************************************************************************changed: [192.168.0.37]TASK [cluster-restore : 分发恢复文件到 etcd 各个节点] ************************************************************************************************************changed: [192.168.0.38]changed: [192.168.0.37]changed: [192.168.0.39]TASK [cluster-restore : 重启etcd 服务] ********************************************************************************************************************changed: [192.168.0.38]changed: [192.168.0.37]changed: [192.168.0.39]TASK [cluster-restore : 以轮询的方式等待服务同步完成] ***************************************************************************************************************changed: [192.168.0.37]changed: [192.168.0.38]changed: [192.168.0.39]PLAY [kube_master] ************************************************************************************************************************************TASK [starting kube_master services] ******************************************************************************************************************changed: [192.168.0.33] => (item=kube-apiserver)changed: [192.168.0.32] => (item=kube-apiserver)changed: [192.168.0.33] => (item=kube-controller-manager)changed: [192.168.0.32] => (item=kube-controller-manager)changed: [192.168.0.31] => (item=kube-apiserver)changed: [192.168.0.33] => (item=kube-scheduler)changed: [192.168.0.32] => (item=kube-scheduler)changed: [192.168.0.31] => (item=kube-controller-manager)changed: [192.168.0.31] => (item=kube-scheduler)PLAY [kube_master,kube_node] **************************************************************************************************************************TASK [starting kube_node services] ********************************************************************************************************************changed: [192.168.0.33] => (item=kubelet)changed: [192.168.0.32] => (item=kubelet)changed: [192.168.0.31] => (item=kubelet)changed: [192.168.0.33] => (item=kube-proxy)changed: [192.168.0.32] => (item=kube-proxy)changed: [192.168.0.36] => (item=kubelet)changed: [192.168.0.31] => (item=kube-proxy)changed: [192.168.0.34] => (item=kubelet)changed: [192.168.0.35] => (item=kubelet)changed: [192.168.0.34] => (item=kube-proxy)changed: [192.168.0.36] => (item=kube-proxy)changed: [192.168.0.35] => (item=kube-proxy)PLAY RECAP ********************************************************************************************************************************************192.168.0.31 : ok=5 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.32 : ok=5 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.33 : ok=5 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.34 : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.35 : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.36 : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.37 : ok=8 changed=6 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.38 : ok=6 changed=5 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.39 : ok=6 changed=5 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 root@k8s-deploy:/etc/kubeasz# |
提示:在恢复数据期间 API server 不可用,必须在业务低峰期操作或者是在其它紧急场景进行;
验证:k8s数据是否恢复?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | root@k8s-deploy:/etc/kubeasz# kubectl get podsNAME READY STATUS RESTARTS AGEtest 1/1 Running 0 4d1htest1 0/1 ContainerCreating 4 (174m ago) 4d1htest2 0/1 ContainerCreating 4 (174m ago) 4d1hroot@k8s-deploy:/etc/kubeasz# kubectl get podsNAME READY STATUS RESTARTS AGEtest 0/1 ContainerCreating 4 (174m ago) 4d1htest1 1/1 Running 4 (174m ago) 4d1htest2 1/1 Running 4 (174m ago) 4d1hroot@k8s-deploy:/etc/kubeasz# kubectl get podsNAME READY STATUS RESTARTS AGEtest 1/1 Running 4 (174m ago) 4d1htest1 1/1 Running 0 4d1htest2 1/1 Running 0 4d1hroot@k8s-deploy:/etc/kubeasz# kubectl get podsNAME READY STATUS RESTARTS AGEtest 1/1 Running 0 4d1htest1 0/1 ContainerCreating 4 (174m ago) 4d1htest2 0/1 ContainerCreating 4 (174m ago) 4d1hroot@k8s-deploy:/etc/kubeasz# kubectl get podsNAME READY STATUS RESTARTS AGEtest 0/1 ContainerCreating 4 (174m ago) 4d1htest1 1/1 Running 4 (174m ago) 4d1htest2 1/1 Running 4 (174m ago) 4d1hroot@k8s-deploy:/etc/kubeasz# |
提示:从上面的信息可以看到,对应pods恢复了,但是状态不对;
验证:在etcd节点验证节点状态信息

提示:从上面的信息可以看到,现在etcd集群有三个leader,相当于etcd集群变成了三台etcd server,这也解释了上面查看pod信息显示不同的的状态的原因了;这里的原因是kubeasz 3.5.2的版本存在bug,在集群恢复数据时,没有将etcd按集群的方式恢复数据;解决办法,修改恢复数据role;如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | root@k8s-deploy:/etc/kubeasz# cat roles/cluster-restore/tasks/main.yml- name: 停止ectd 服务 service: name=etcd state=stopped- name: 清除etcd 数据目录 file: name={{ ETCD_DATA_DIR }}/member state=absent- name: 清除 etcd 备份目录 file: name={{ cluster_dir }}/backup/etcd-restore state=absent delegate_to: 127.0.0.1 run_once: true- name: 生成备份目录 file: name=/etcd_backup state=directory- name: 准备指定的备份etcd 数据 copy: src: "{{ cluster_dir }}/backup/{{ db_to_restore }}" dest: "/etcd_backup/snapshot.db"- name: etcd 数据恢复 shell: "cd /etcd_backup && \ ETCDCTL_API=3 {{ bin_dir }}/etcdctl snapshot restore snapshot.db \ --name etcd-{{ inventory_hostname }} \ --initial-cluster {{ ETCD_NODES }} \ --initial-cluster-token etcd-cluster-0 \ --initial-advertise-peer-urls https://{{ inventory_hostname }}:2380"- name: 恢复数据至etcd 数据目录 shell: "cp -rf /etcd_backup/etcd-{{ inventory_hostname }}.etcd/member {{ ETCD_DATA_DIR }}/"- name: 重启etcd 服务 service: name=etcd state=restarted- name: 以轮询的方式等待服务同步完成 shell: "systemctl is-active etcd.service" register: etcd_status until: '"active" in etcd_status.stdout' retries: 8 delay: 8root@k8s-deploy:/etc/kubeasz# |
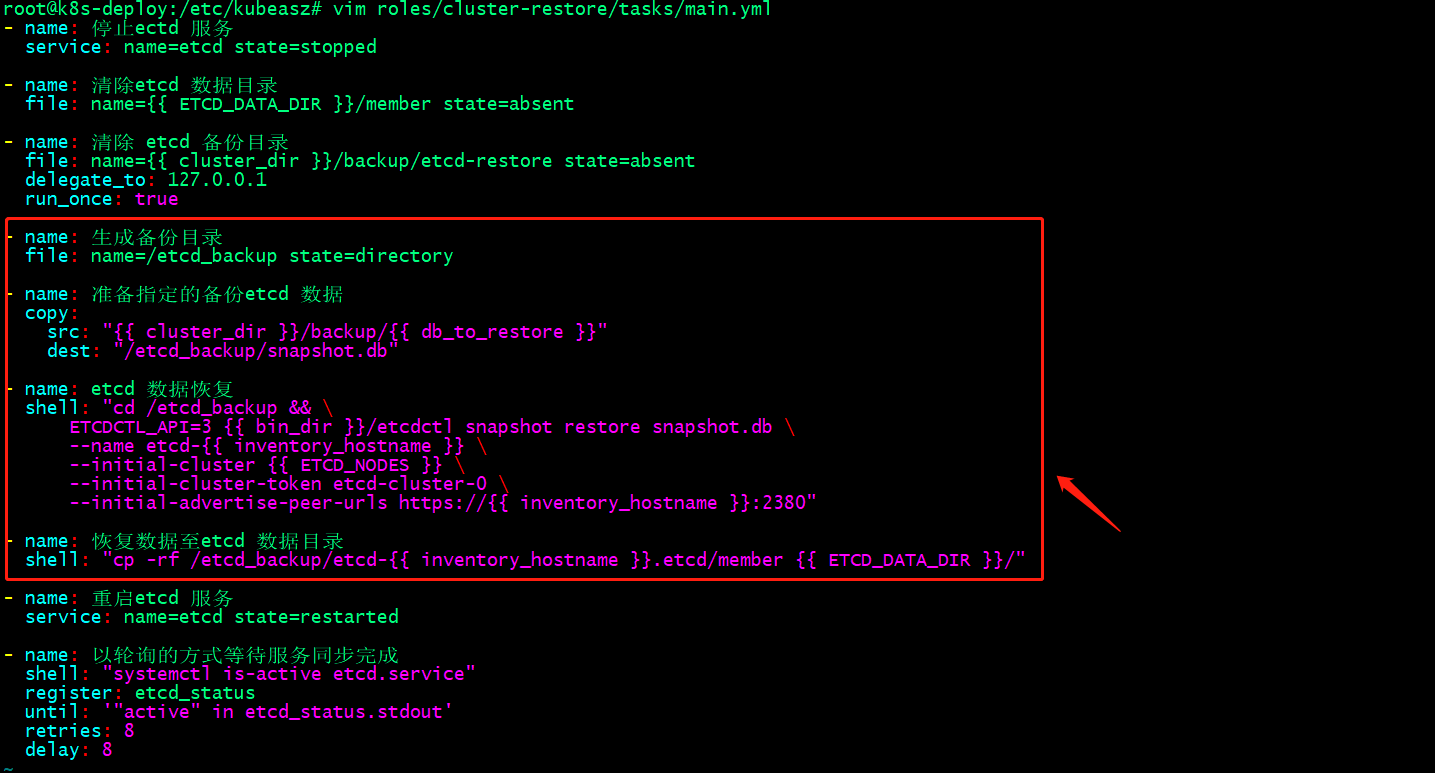
提示:恢复etcd集群数据时,需要指定node节点所在etcd集群中的名称标识,集群名称,集群token和node通告的集群端口地址;
验证:再次执行集群数据恢复操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 | root@k8s-deploy:/etc/kubeasz# ./ezctl restore k8s-cluster01ansible-playbook -i clusters/k8s-cluster01/hosts -e @clusters/k8s-cluster01/config.yml playbooks/95.restore.yml2023-04-26 16:27:46 INFO cluster:k8s-cluster01 restore begins in 5s, press any key to abort:PLAY [kube_master] ********************************************************************************************************************************************************TASK [Gathering Facts] ****************************************************************************************************************************************************ok: [192.168.0.33]ok: [192.168.0.31]ok: [192.168.0.32]TASK [stopping kube_master services] **************************************************************************************************************************************ok: [192.168.0.31] => (item=kube-apiserver)ok: [192.168.0.32] => (item=kube-apiserver)ok: [192.168.0.33] => (item=kube-apiserver)ok: [192.168.0.31] => (item=kube-controller-manager)ok: [192.168.0.33] => (item=kube-controller-manager)ok: [192.168.0.32] => (item=kube-controller-manager)ok: [192.168.0.31] => (item=kube-scheduler)ok: [192.168.0.33] => (item=kube-scheduler)ok: [192.168.0.32] => (item=kube-scheduler)PLAY [kube_master,kube_node] **********************************************************************************************************************************************TASK [Gathering Facts] ****************************************************************************************************************************************************ok: [192.168.0.35]ok: [192.168.0.34]ok: [192.168.0.36]TASK [stopping kube_node services] ****************************************************************************************************************************************ok: [192.168.0.33] => (item=kubelet)ok: [192.168.0.32] => (item=kubelet)ok: [192.168.0.31] => (item=kubelet)ok: [192.168.0.36] => (item=kubelet)ok: [192.168.0.34] => (item=kubelet)ok: [192.168.0.36] => (item=kube-proxy)ok: [192.168.0.34] => (item=kube-proxy)ok: [192.168.0.33] => (item=kube-proxy)ok: [192.168.0.32] => (item=kube-proxy)ok: [192.168.0.31] => (item=kube-proxy)ok: [192.168.0.35] => (item=kubelet)ok: [192.168.0.35] => (item=kube-proxy)PLAY [etcd] ***************************************************************************************************************************************************************TASK [Gathering Facts] ****************************************************************************************************************************************************ok: [192.168.0.38]ok: [192.168.0.37]ok: [192.168.0.39]TASK [cluster-restore : 停止ectd 服务] ****************************************************************************************************************************************ok: [192.168.0.37]ok: [192.168.0.38]ok: [192.168.0.39]TASK [cluster-restore : 清除etcd 数据目录] **************************************************************************************************************************************ok: [192.168.0.37]ok: [192.168.0.38]ok: [192.168.0.39]TASK [cluster-restore : 清除 etcd 备份目录] *************************************************************************************************************************************ok: [192.168.0.37]TASK [cluster-restore : 生成备份目录] *******************************************************************************************************************************************changed: [192.168.0.37]changed: [192.168.0.38]changed: [192.168.0.39]TASK [cluster-restore : 准备指定的备份etcd 数据] ***********************************************************************************************************************************changed: [192.168.0.37]changed: [192.168.0.39]changed: [192.168.0.38]TASK [cluster-restore : etcd 数据恢复] ****************************************************************************************************************************************changed: [192.168.0.37]changed: [192.168.0.38]changed: [192.168.0.39]TASK [cluster-restore : 恢复数据至etcd 数据目录] ***********************************************************************************************************************************changed: [192.168.0.37]changed: [192.168.0.38]changed: [192.168.0.39]TASK [cluster-restore : 重启etcd 服务] ****************************************************************************************************************************************changed: [192.168.0.39]changed: [192.168.0.37]changed: [192.168.0.38]TASK [cluster-restore : 以轮询的方式等待服务同步完成] ***********************************************************************************************************************************changed: [192.168.0.37]changed: [192.168.0.38]changed: [192.168.0.39]PLAY [kube_master] ********************************************************************************************************************************************************TASK [starting kube_master services] **************************************************************************************************************************************changed: [192.168.0.32] => (item=kube-apiserver)changed: [192.168.0.33] => (item=kube-apiserver)changed: [192.168.0.31] => (item=kube-apiserver)changed: [192.168.0.32] => (item=kube-controller-manager)changed: [192.168.0.33] => (item=kube-controller-manager)changed: [192.168.0.32] => (item=kube-scheduler)changed: [192.168.0.31] => (item=kube-controller-manager)changed: [192.168.0.33] => (item=kube-scheduler)changed: [192.168.0.31] => (item=kube-scheduler)PLAY [kube_master,kube_node] **********************************************************************************************************************************************TASK [starting kube_node services] ****************************************************************************************************************************************changed: [192.168.0.31] => (item=kubelet)changed: [192.168.0.33] => (item=kubelet)changed: [192.168.0.32] => (item=kubelet)changed: [192.168.0.31] => (item=kube-proxy)changed: [192.168.0.32] => (item=kube-proxy)changed: [192.168.0.33] => (item=kube-proxy)changed: [192.168.0.36] => (item=kubelet)changed: [192.168.0.34] => (item=kubelet)changed: [192.168.0.36] => (item=kube-proxy)changed: [192.168.0.34] => (item=kube-proxy)changed: [192.168.0.35] => (item=kubelet)changed: [192.168.0.35] => (item=kube-proxy)PLAY RECAP ****************************************************************************************************************************************************************192.168.0.31 : ok=5 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.32 : ok=5 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.33 : ok=5 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.34 : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.35 : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.36 : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.37 : ok=10 changed=6 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.38 : ok=9 changed=6 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 192.168.0.39 : ok=9 changed=6 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 root@k8s-deploy:/etc/kubeasz# |
验证:查看k8s集群pods信息是否显示正常?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | root@k8s-deploy:/etc/kubeasz# kubectl get pods NAME READY STATUS RESTARTS AGEtest 1/1 Running 0 4d2htest1 1/1 Running 0 4d2htest2 1/1 Running 0 4d1hroot@k8s-deploy:/etc/kubeasz# kubectl get pods NAME READY STATUS RESTARTS AGEtest 1/1 Running 0 4d2htest1 1/1 Running 0 4d2htest2 1/1 Running 0 4d1hroot@k8s-deploy:/etc/kubeasz# kubectl get pods NAME READY STATUS RESTARTS AGEtest 1/1 Running 0 4d2htest1 1/1 Running 0 4d2htest2 1/1 Running 0 4d1hroot@k8s-deploy:/etc/kubeasz# kubectl get pods NAME READY STATUS RESTARTS AGEtest 1/1 Running 0 4d2htest1 1/1 Running 0 4d2htest2 1/1 Running 0 4d1hroot@k8s-deploy:/etc/kubeasz# kubectl get pods NAME READY STATUS RESTARTS AGEtest 1/1 Running 0 4d2htest1 1/1 Running 0 4d2htest2 1/1 Running 0 4d1hroot@k8s-deploy:/etc/kubeasz# |
在etcd节点验证etcd集群状态,看看现在etcd是否还是3个leader?
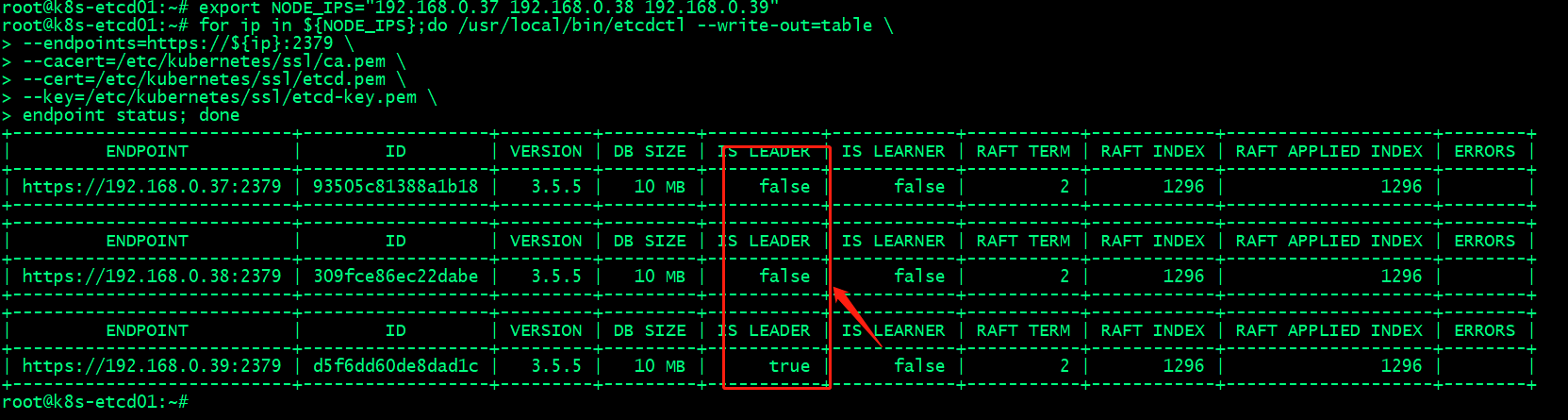
提示:可以看到现在etcd集群就只有一个leader了;至此,基于kubeasz备份和恢复etcd集群数据就完成了;




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
2020-05-03 负载均衡服务之HAProxy https配置、四层负载均衡以及访问控制