分布式存储系统之Ceph集群存储池操作
 erasure-code-profile参数是用于指定纠删码池配置文件;未指定要使用的纠删编码配置文件时,创建命令会为其自动创建一个,并在创建相关的CRUSH规则集时使用到它;默认配置文件自动定义k=2和m=1,这意味着Ceph将通过三个OSD扩展对象数据,并且可以丢失其中一个OSD而不会丢失数据,因此,在冗余效果上,它相当于一个大小为2的副本池 ,不过,其存储空间有效利用率为2/3而非1/2。
erasure-code-profile参数是用于指定纠删码池配置文件;未指定要使用的纠删编码配置文件时,创建命令会为其自动创建一个,并在创建相关的CRUSH规则集时使用到它;默认配置文件自动定义k=2和m=1,这意味着Ceph将通过三个OSD扩展对象数据,并且可以丢失其中一个OSD而不会丢失数据,因此,在冗余效果上,它相当于一个大小为2的副本池 ,不过,其存储空间有效利用率为2/3而非1/2。
前文我们了解了ceph的存储池、PG、CRUSH、客户端IO的简要工作过程、Ceph客户端计算PG_ID的步骤的相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/16733806.html;今天我们来聊一聊在ceph上操作存储池相关命令的用法和说明;
在ceph上操作存储池不外乎就是查看列出、创建、重命名和删除等操作,常用相关的工具都是“ceph osd pool”的子命令,ls、create、rename和rm等;
1、创建存储池
副本型存储池创建命令格式
1 | ceph osd pool create <pool-name> <pg-num> [pgp-num] [replicated] [crush-rule-name] [expected-num-objects] |
提示:创建副本型存储池上面的必要选项有存储池的名称和PG的数量,后面可以不用跟pgp和replicated来指定存储池的pgp的数量和类型为副本型;即默认创建不指定存储池类型,都是创建的是副本池;
纠删码池存储池创建命令格式
1 | ceph osd pool create <pool-name> <pg-num> <pgp-num> erasure [erasure-code-profile] [crush-rule-name] [expected-num-objects] |
提示:创建纠删码池存储池,需要给定存储池名称、PG的数量、PGP的数量已经明确指定存储池类型为erasure;这里解释下PGP,所谓PGP(Placement Group for Placement purpose)就是用于归置的PG数量,其值应该等于PG的数量; crush-ruleset-name是用于指定此存储池所用的CRUSH规则集的名称,不过,引用的规则集必须事先存在;
erasure-code-profile参数是用于指定纠删码池配置文件;未指定要使用的纠删编码配置文件时,创建命令会为其自动创建一个,并在创建相关的CRUSH规则集时使用到它;默认配置文件自动定义k=2和m=1,这意味着Ceph将通过三个OSD扩展对象数据,并且可以丢失其中一个OSD而不会丢失数据,因此,在冗余效果上,它相当于一个大小为2的副本池 ,不过,其存储空间有效利用率为2/3而非1/2。
示例:创建一个副本池
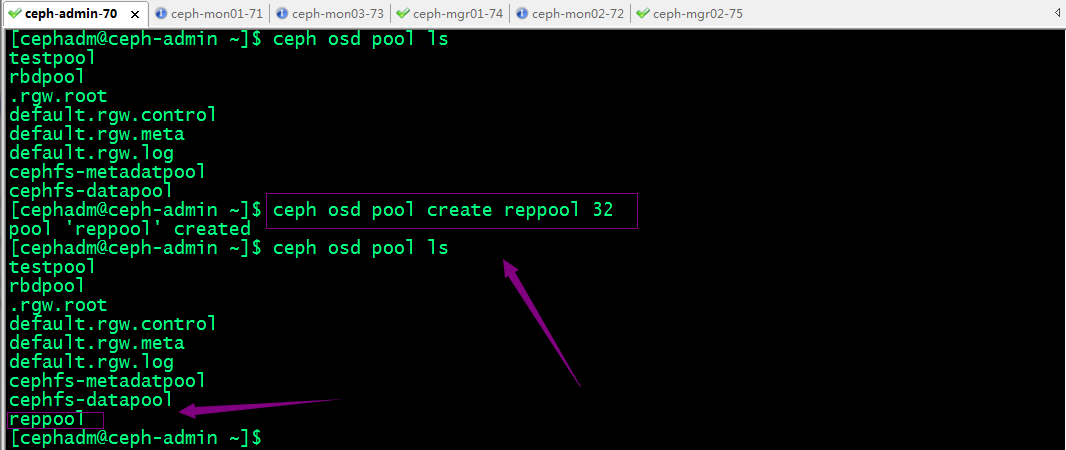
示例:创建一个纠删码池
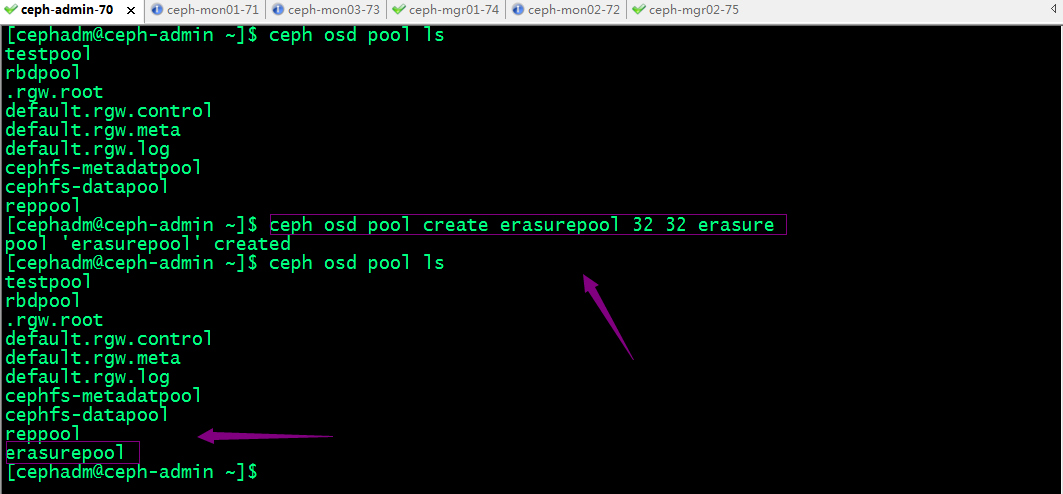
2、获取存储池的相关信息
列出存储池:ceph osd pool ls [detail]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | [cephadm@ceph-admin ~]$ ceph osd pool lstestpoolrbdpool.rgw.rootdefault.rgw.controldefault.rgw.metadefault.rgw.logcephfs-metadatpoolcephfs-datapoolreppoolerasurepool[cephadm@ceph-admin ~]$ ceph osd pool ls detail pool 1 'testpool' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 16 pgp_num 16 last_change 42 flags hashpspool stripe_width 0pool 2 'rbdpool' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 81 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd removed_snaps [1~3]pool 3 '.rgw.root' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 84 owner 18446744073709551615 flags hashpspool stripe_width 0 application rgwpool 4 'default.rgw.control' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 87 owner 18446744073709551615 flags hashpspool stripe_width 0 application rgwpool 5 'default.rgw.meta' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 89 owner 18446744073709551615 flags hashpspool stripe_width 0 application rgwpool 6 'default.rgw.log' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 91 owner 18446744073709551615 flags hashpspool stripe_width 0 application rgwpool 7 'cephfs-metadatpool' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 99 flags hashpspool stripe_width 0 application cephfspool 8 'cephfs-datapool' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 128 pgp_num 128 last_change 99 flags hashpspool stripe_width 0 application cephfspool 9 'reppool' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 last_change 126 flags hashpspool stripe_width 0pool 10 'erasurepool' erasure size 3 min_size 2 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 last_change 130 flags hashpspool stripe_width 8192[cephadm@ceph-admin ~]$ |
提示:后面接detail表示列出存储池的详细信息;
获取存储池的统计数据:ceph osd pool stats [pool-name]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | [cephadm@ceph-admin ~]$ ceph osd pool stats reppoolpool reppool id 9 nothing is going on[cephadm@ceph-admin ~]$ ceph osd pool stats pool testpool id 1 nothing is going onpool rbdpool id 2 nothing is going onpool .rgw.root id 3 nothing is going onpool default.rgw.control id 4 nothing is going onpool default.rgw.meta id 5 nothing is going onpool default.rgw.log id 6 nothing is going onpool cephfs-metadatpool id 7 nothing is going onpool cephfs-datapool id 8 nothing is going onpool reppool id 9 nothing is going onpool erasurepool id 10 nothing is going on[cephadm@ceph-admin ~]$ |
提示:不指定存储池名称表示查看所有存储池的统计数据;
显示存储池的用量信息:rados df 或者ceph df
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | [cephadm@ceph-admin ~]$ rados dfPOOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR .rgw.root 1.1 KiB 4 0 12 0 0 0 27 18 KiB 4 4 KiB cephfs-datapool 0 B 0 0 0 0 0 0 0 0 B 0 0 B cephfs-metadatpool 2.2 KiB 22 0 66 0 0 0 49 51 KiB 46 13 KiB default.rgw.control 0 B 8 0 24 0 0 0 0 0 B 0 0 B default.rgw.log 0 B 175 0 525 0 0 0 16733 16 MiB 11158 0 B default.rgw.meta 0 B 0 0 0 0 0 0 0 0 B 0 0 B erasurepool 0 B 0 0 0 0 0 0 0 0 B 0 0 B rbdpool 389 B 5 0 15 0 0 0 50 32 KiB 19 10 KiB reppool 0 B 0 0 0 0 0 0 0 0 B 0 0 B testpool 0 B 0 0 0 0 0 0 2 2 KiB 2 1 KiB total_objects 214total_used 10 GiBtotal_avail 890 GiBtotal_space 900 GiB[cephadm@ceph-admin ~]$ |
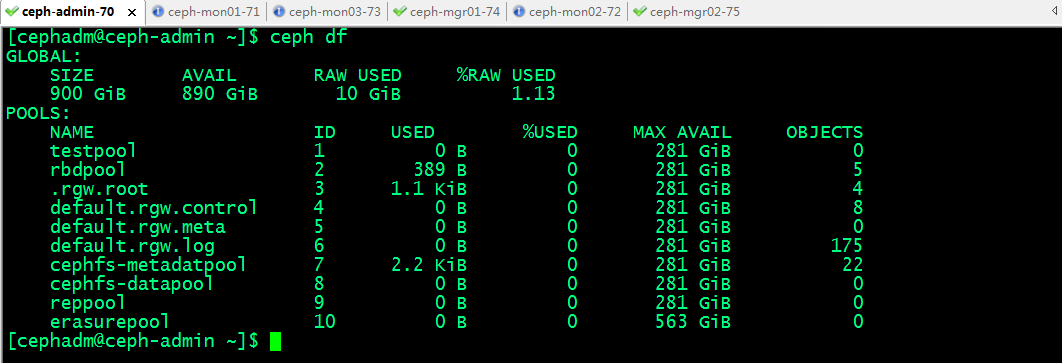
提示:rados df和ceph df显示稍微有点差别,rados 信息比较全面但偏底层;ceph df人类比较容易看懂;
3、存储池重命名
命令格式:ceph osd pool rename old-name new-name

4、删除存储池
我们知道删除存储池意味着数据的丢失;所以ceph为了防止我们意外删除存储池实施了两个机制;我们要删除存储池,必须先禁用这两个机制;
第一个机制是NODELETE标志,其值需要为false,默认也是false;即允许我们删除;第二个机制是集群范围的配置参数mon allow pool delete,其默认值为“false”,这表示默认不能删除存储池;即我们要删除存储池,需要将第二个机制mon allow pool delete 的值修改为true即可删除存储池;
查看nodelete的值命令格式:ceph osd pool get pool-name nodelete

修改命令nodelete的值命令格式:ceph osd pool set pool-name nodelete false|true

提示:我们要删存储池,需要将nodelete的值设置为false,即不允许删除为假,即表示允许删除;
修改mon allow pool delete的值命令格式:ceph tell mon.* injectargs --mon-allow-pool-delete={true|false}

提示:删除之前将其值设置为true,删除完成后再改为false;
删除rep-pool存储池

提示:虽然我们进用了上述的两个防止意外删除存储池的机制外,我们在直接删除存储池ceph还会提示我们需要将存储池的名称写两遍以及加--yes-i-really-really-mean-it选项来确定删除存储池的操作;
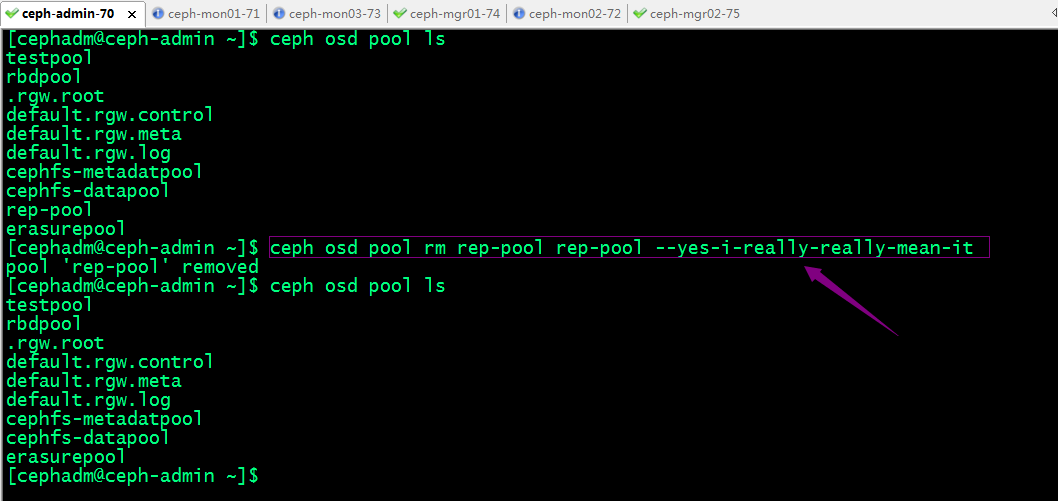
提示:删除需要删除的存储池以后,我们需要将mon allow pool delete的值修改为false防止后面误删除存储池;

5、设置存储池配额
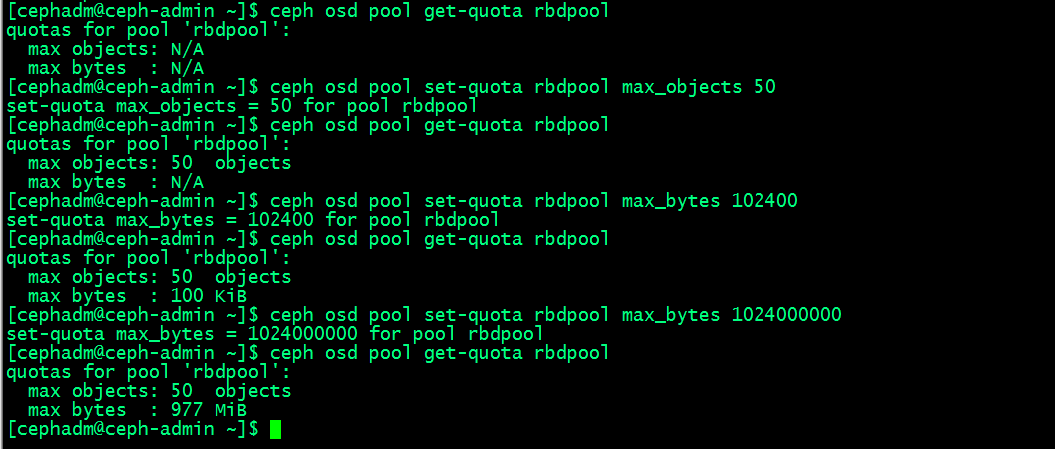
Ceph支持为存储池设置可存储对象的最大数量(max_objects)和可占用的最大空间(max_bytes)两个纬度的配额,命令格式ceph osd pool set-quota <pool-name> max_objects|max_bytes <val>;获取存储池配额的相关信息命令格式:ceph osd pool get-quota <pool-name>;
6、配置存储池参数
存储池的诸多配置属性保存于配置参数中,获取配置:ceph osd pool get <pool-name> <key>;设定配置:ceph osd pool set <pool-name> <key> <value>;
存储池常用的可配置参数
size:存储池中的对象副本数;
min_size:I/O所需要的最小副本数;
pg_num:存储池的PG数量;
pgp_num:计算数据归置时要使用的PG的有效数量;
crush_ruleset:用于在集群中映射对象归置的规则组;
nodelete:控制是否可删除存储池;
nopgchange:控制是否可更改存储池的pg_num和pgp_num;
nosizechange:控制是否可更改存储池的大小;
noscrub和nodeep-scrub:控制是否可整理或深层整理存储池以解决临时高I/O负载的问题;
scrub_min_interval:集群负载较低时整理存储池的最小时间间隔;默认值为0,表示其取值来自于配置文件中的osd_scrub_min_interval参数;
scrub_max_interval:整理存储池的最大时间间隔;默认值为0,表示其取值来自于配置文件中的osd_scrub_max_interval参数;
deep_scrub_interval:深层整理存储池的间隔;默认值为0,表示其取值来自于配置文件中的osd_deep_scrub参数;

7、存储池快照
关于存储池快照
• 存储池快照是指整个存储池的状态快照;
• 通过存储池快照,可以保留存储池状态的历史;
• 创建存储池快照可能需要大量存储空间,具体取决于存储池的大小;
创建存储池快照命令格式: ceph osd pool mksnap <pool-name> <snap-name>或者rados -p <pool-name> mksnap <snap-name>
列出存储池的快照命令格式:rados -p <pool-name> lssnap
1 2 3 4 5 6 | [cephadm@ceph-admin ~]$ ceph osd pool mksnap cephfs-metadatpool metadatasnap1created pool cephfs-metadatpool snap metadatasnap1[cephadm@ceph-admin ~]$ rados -p cephfs-metadatpool lssnap1 metadatasnap1 2022.09.30 00:20:551 snaps[cephadm@ceph-admin ~]$ |
回滚存储池至指定的快照命令格式: rados -p <pool-name> rollback <pool-name> <snap-name>
1 2 3 4 5 6 7 | [cephadm@ceph-admin ~]$ rados -p cephfs-metadatpool lssnap1 metadatasnap1 2022.09.30 00:20:552 metadatasnap2 2022.09.30 00:22:352 snaps[cephadm@ceph-admin ~]$ rados -p cephfs-metadatpool rollback cephfs-metadatpool metadatasnap2rolled back pool cephfs-metadatpool to snapshot metadatasnap2[cephadm@ceph-admin ~]$ |
删除存储池快照命令格式: ceph osd pool rmsnap <pool-name> <snap-name>或 rados -p <pool-name> rmsnap <snap-name>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | [cephadm@ceph-admin ~]$ rados -p cephfs-metadatpool lssnap1 metadatasnap1 2022.09.30 00:20:552 metadatasnap2 2022.09.30 00:22:352 snaps[cephadm@ceph-admin ~]$ ceph osd pool rmsnap cephfs-metadatpool metadatasnap1removed pool cephfs-metadatpool snap metadatasnap1[cephadm@ceph-admin ~]$ rados -p cephfs-metadatpool lssnap 2 metadatasnap2 2022.09.30 00:22:351 snaps[cephadm@ceph-admin ~]$ rados -p cephfs-metadatpool rmsnap metadatasnap2removed pool cephfs-metadatpool snap metadatasnap2[cephadm@ceph-admin ~]$ rados -p cephfs-metadatpool lssnap0 snaps[cephadm@ceph-admin ~]$ |
提示:不用的快照建议及时清除;
8、存储池数据压缩
BlueStore存储引擎提供即时数据压缩,以节省磁盘空间,启用压缩命令格式:ceph osd pool set <pool-name> compression_algorithm snappy;压缩算法有none、zlib、lz4、zstd和snappy等几种,默认为snappy;zstd有较好的压缩比,但比较消耗CPU;lz4和snappy对CPU占用比例较低;不建议使用zlib;
设置压缩模式命令格式:ceph osd pool set <pool-name> compression_mode aggressive ;压缩模式:none、aggressive、passive和force,默认值为none; none表示不压缩; passive表示若提示COMPRESSIBLE,则压缩;aggressive表示除非提示INCOMPRESSIBLE,否则就压缩; force表示始终压缩;
其它可用的压缩参数
compression_required_ratio:指定压缩比,取值格式为双精度浮点型,其值为SIZE_COMPRESSED/SIZE_ORIGINAL,即压缩后的大小与原始内容大小的比值,默认为.875;
compression_max_blob_size:压缩对象的最大体积,无符号整数型数值,默认为0,表示没有限制;
compression_min_blob_size:压缩对象的最小体积,无符号整数型数值,默认为0,表示没有限制;
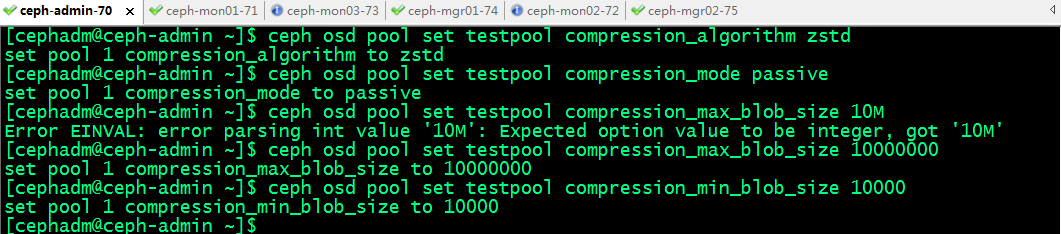
提示:压缩最小体积和最大体积都是以字节为单位;
全局压缩选项
可在ceph配置文件中设置压缩属性,它将对所有的存储池生效;可设置的相关参数如下
• bluestore_compression_algorithm
• bluestore_compression_mode
• bluestore_compression_required_ratio
• bluestore_compression_min_blob_size
• bluestore_compression_max_blob_size
• bluestore_compression_min_blob_size_ssd
• bluestore_compression_max_blob_size_ssd
• bluestore_compression_min_blob_size_hdd
• bluestore_compression_max_blob_size_hdd
9、纠删码池配置文件
列出纠删码配置文件命令格式: ceph osd erasure-code-profile ls
获取指定的配置文件的相关内容:ceph osd erasure-code-profile get default
1 2 3 4 5 6 7 8 | [cephadm@ceph-admin ~]$ ceph osd erasure-code-profile lsdefault[cephadm@ceph-admin ~]$ ceph osd erasure-code-profile get defaultk=2m=1plugin=jerasuretechnique=reed_sol_van[cephadm@ceph-admin ~]$ |
自定义纠删码配置文件
命令格式:ceph osd erasure-code-profile set <name> [<directory=directory>] [<plugin=plugin>] [<crush-device-class>] [<crush-failure-domain>] [<key=value> ...] [--force]
• - directory:加载纠删码插件的目录路径,默认为/usr/lib/ceph/erasure-code;
• - plugin:用于生成及恢复纠删码块的插件名称,默认为jerasure;
• - crush-device-class:设备类别,例如hdd或ssd,默认为none,即无视类别;
• - crush-failure-domain:故障域,默认为host,支持使用的包括osd、host、rack、row和room等;
• - --force:强制覆盖现有的同名配置文件;
例如,如果所需的体系结构必须承受两个OSD的丢失,并且存储开销为30%;
1 2 3 4 5 6 7 | [cephadm@ceph-admin ~]$ ceph osd erasure-code-profile lsdefault[cephadm@ceph-admin ~]$ ceph osd erasure-code-profile set myprofile k=4 m=2 crush-failure-domain=osd[cephadm@ceph-admin ~]$ ceph osd erasure-code-profile lsdefaultmyprofile[cephadm@ceph-admin ~]$ |
纠删码插件
Ceph支持以插件方式加载使用的纠删编码插件,存储管理员可根据存储场景的需要优化选择合用的插件。目前,Ceph支持的插件包括如下三个:
1、jerasure:最为通用的和灵活的纠删编码插件,它也是纠删码池默认使用的插件;不过,任何一个OSD成员的丢失,都需要余下的所有成员OSD参与恢复过程;另外,使用此类插件时,管理员还可以通过technique选项指定要使用的编码技术;
• reed_sol_van:最灵活的编码技术,管理员仅需提供k和m参数即可;
• cauchy_good:更快的编码技术,但需要小心设置PACKETSIZE参数;
• reed_sol_r6_op、liberation、blaum_roth或liber8tion:仅支持使用m=2的编码技术,功能特性类同于RAID 6;
2、 lrc:全称为Locally Repairable Erasure Code,即本地修复纠删码,除了默认的m个编码块之外,它会额外在本地创建指定数量(l)的奇偶校验块,从而在一个OSD丢失时,可以仅通过l个奇偶校验块完成恢复;
3、isa:仅支持运行在intel CPU之上的纠删编码插件,它支持reed_sol_van和cauchy两种技术;
例如,下面的命令创建了一个使用lrc插件的配置文件LRCprofile,其本地奇偶校验块为3,故障域为osd
1 2 3 4 5 6 | [cephadm@ceph-admin ~]$ ceph osd erasure-code-profile set LRCprofile plugin=lrc k=4 m=2 l=3 crush-failure-domain=osd[cephadm@ceph-admin ~]$ ceph osd erasure-code-profile lsLRCprofiledefaultmyprofile[cephadm@ceph-admin ~]$ |




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
2021-10-06 HCNP Routing&Switching之BGP基础
2018-10-06 MySQL数据库备份与恢复