容器编排系统K8s之HPA资源
 HPA的全称是Horizontal Pod Autoscaler,从字面意思理解它就是水平pod自动伸缩器;简单讲HPA的主要作用是根据指定的指标数据,监控对应的pod控制器,一旦对应pod控制器下的pod的对应指标数据达到我们定义的阀值,即HPA就会被触发,它会根据对应指标数据的值来扩展/缩减对应pod副本数量;扩展和缩减都是有上下限的,当pod数量达到上限,即便指标数据还是超过了我们定义的阀值它也不会再扩展,对于下线默认不指定就是为1;下限和上限都是一样的逻辑,即便一个访问都没有,它会保持最低有多少个pod运行;需注意hpa只能用于监控可扩缩的pod控制器,对DaemonSet类型控制器不支持;
HPA的全称是Horizontal Pod Autoscaler,从字面意思理解它就是水平pod自动伸缩器;简单讲HPA的主要作用是根据指定的指标数据,监控对应的pod控制器,一旦对应pod控制器下的pod的对应指标数据达到我们定义的阀值,即HPA就会被触发,它会根据对应指标数据的值来扩展/缩减对应pod副本数量;扩展和缩减都是有上下限的,当pod数量达到上限,即便指标数据还是超过了我们定义的阀值它也不会再扩展,对于下线默认不指定就是为1;下限和上限都是一样的逻辑,即便一个访问都没有,它会保持最低有多少个pod运行;需注意hpa只能用于监控可扩缩的pod控制器,对DaemonSet类型控制器不支持;
前文我们了解了用Prometheus监控k8s上的节点和pod资源,回顾请参考:https://www.cnblogs.com/qiuhom-1874/p/14287942.html;今天我们来了解下k8s上的HPA资源的使用;
HPA的全称是Horizontal Pod Autoscaler,从字面意思理解它就是水平pod自动伸缩器;简单讲HPA的主要作用是根据指定的指标数据,监控对应的pod控制器,一旦对应pod控制器下的pod的对应指标数据达到我们定义的阀值,即HPA就会被触发,它会根据对应指标数据的值来扩展/缩减对应pod副本数量;扩展和缩减都是有上下限的,当pod数量达到上限,即便指标数据还是超过了我们定义的阀值它也不会再扩展,对于下线默认不指定就是为1;下限和上限都是一样的逻辑,即便一个访问都没有,它会保持最低有多少个pod运行;需注意hpa只能用于监控可扩缩的pod控制器,对DaemonSet类型控制器不支持;
在k8s上HPA有两个版本v1和v2;v1只支持根据cpu这个指标数据来自动扩展/缩减pod数量;V2支持根据自定义指标数量来自动扩展/缩减pod数量;HPA是k8s上的标准资源,我们可以通过命令或资源清单的方式去创建它;
使用命令创建HPA资源的使用语法格式
Usage: kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min=MINPODS] --max=MAXPODS [--cpu-percent=CPU] [options]
提示:默认不指定hpa的名称,它会同对应的pod控制名称相同;--min选项用于指定对应pod副本最低数量,默认不指定其值为1,--max用于指定pod最大副本数量;--cpu-percent选项用于指定对应pod的cpu资源的占用比例,该占用比例是同对应pod的资源限制做比较;
示例:使用命令创建v1版本的hpa资源
使用deploy控制器创建pod资源
[root@master01 ~]# cat myapp.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
namespace: default
labels:
app: myapp
spec:
replicas: 2
selector:
matchLabels:
app: myapp
template:
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
resources:
requests:
cpu: 50m
memory: 64Mi
limits:
cpu: 50m
memory: 64Mi
---
apiVersion: v1
kind: Service
metadata:
name: myapp-svc
labels:
app: myapp
namespace: default
spec:
selector:
app: myapp
ports:
- name: http
port: 80
targetPort: 80
type: NodePort
[root@master01 ~]#
应用资源清单
[root@master01 ~]# kubectl apply -f myapp.yaml deployment.apps/myapp created service/myapp-svc created [root@master01 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE myapp-779867bcfc-657qr 1/1 Running 0 6s myapp-779867bcfc-txvj8 1/1 Running 0 6s [root@master01 ~]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 8d myapp-svc NodePort 10.111.14.219 <none> 80:31154/TCP 13s [root@master01 ~]#
查看pod的资源占比情况
[root@master01 ~]# kubectl top pods NAME CPU(cores) MEMORY(bytes) myapp-779867bcfc-657qr 0m 3Mi myapp-779867bcfc-txvj8 0m 3Mi [root@master01 ~]#
提示:现在没有访问对应pod,其cpu指标为0;
使用命令创建hpa资源,监控myapp deploy,指定对应pod的cpu资源使用率达到50%就触发hpa
[root@master01 ~]# kubectl autoscale deploy myapp --min=2 --max=10 --cpu-percent=50 horizontalpodautoscaler.autoscaling/myapp autoscaled [root@master01 ~]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE myapp Deployment/myapp <unknown>/50% 2 10 0 10s [root@master01 ~]# kubectl describe hpa/myapp Name: myapp Namespace: default Labels: <none> Annotations: <none> CreationTimestamp: Mon, 18 Jan 2021 15:26:49 +0800 Reference: Deployment/myapp Metrics: ( current / target ) resource cpu on pods (as a percentage of request): 0% (0) / 50% Min replicas: 2 Max replicas: 10 Deployment pods: 2 current / 2 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request) ScalingLimited False DesiredWithinRange the desired count is within the acceptable range Events: <none> [root@master01 ~]#
验证:使用ab压测工具,对pod进行压力访问,看看对应pod cpu资源使用率大于50%,对应pod是否会扩展?
安装ab工具
yum install httpd-tools -y
使用外部主机对pod svc 进行压力访问

查看pod的资源占比情况
[root@master01 ~]# kubectl top pods NAME CPU(cores) MEMORY(bytes) myapp-779867bcfc-657qr 51m 4Mi myapp-779867bcfc-txvj8 34m 4Mi [root@master01 ~]#
提示:可以看到对应pod的cpu资源都大于限制的资源上限的50%;这里需要注意hpa扩展pod它有一定的延迟,不是立刻马上就扩展;
查看对应hpa资源的详情
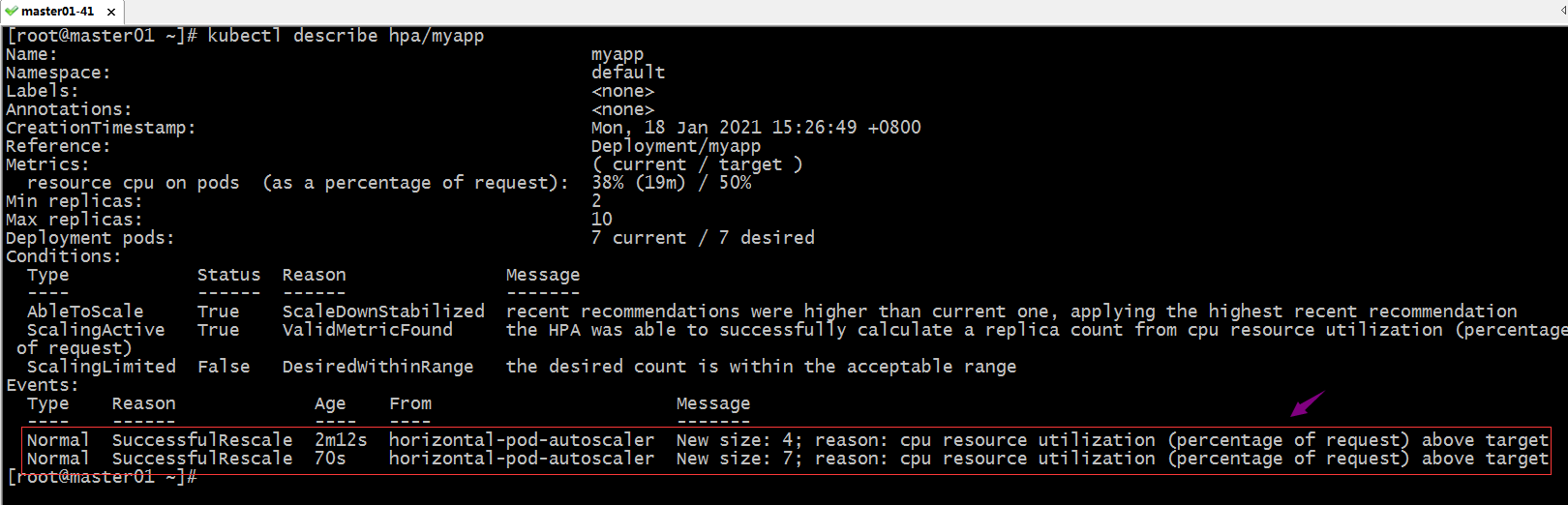
提示:hpa详情告诉我们对应pod扩展到7个;
查看pod数量是否被扩展到7个?
[root@master01 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE myapp-779867bcfc-657qr 1/1 Running 0 16m myapp-779867bcfc-7c4dt 1/1 Running 0 3m27s myapp-779867bcfc-b2jmn 1/1 Running 0 3m27s myapp-779867bcfc-fmw7v 1/1 Running 0 2m25s myapp-779867bcfc-hxhj2 1/1 Running 0 2m25s myapp-779867bcfc-txvj8 1/1 Running 0 16m myapp-779867bcfc-xvh58 1/1 Running 0 2m25s [root@master01 ~]#
提示:可以看到对应pod被控制到7个;
查看对应pod的资源占比是否还高于限制的50%?
[root@master01 ~]# kubectl top pods NAME CPU(cores) MEMORY(bytes) myapp-779867bcfc-657qr 49m 4Mi myapp-779867bcfc-7c4dt 25m 4Mi myapp-779867bcfc-b2jmn 36m 4Mi myapp-779867bcfc-fmw7v 42m 4Mi myapp-779867bcfc-hxhj2 46m 3Mi myapp-779867bcfc-txvj8 21m 4Mi myapp-779867bcfc-xvh58 49m 4Mi [root@master01 ~]#
提示:可以看到对应pod的cpu使用率还是高于限制的50%,说明扩展到pod数量不能够响应对应的请求,此时hpa还会扩展;
查看hpa详情,看看是否又一次扩展pod的数量?
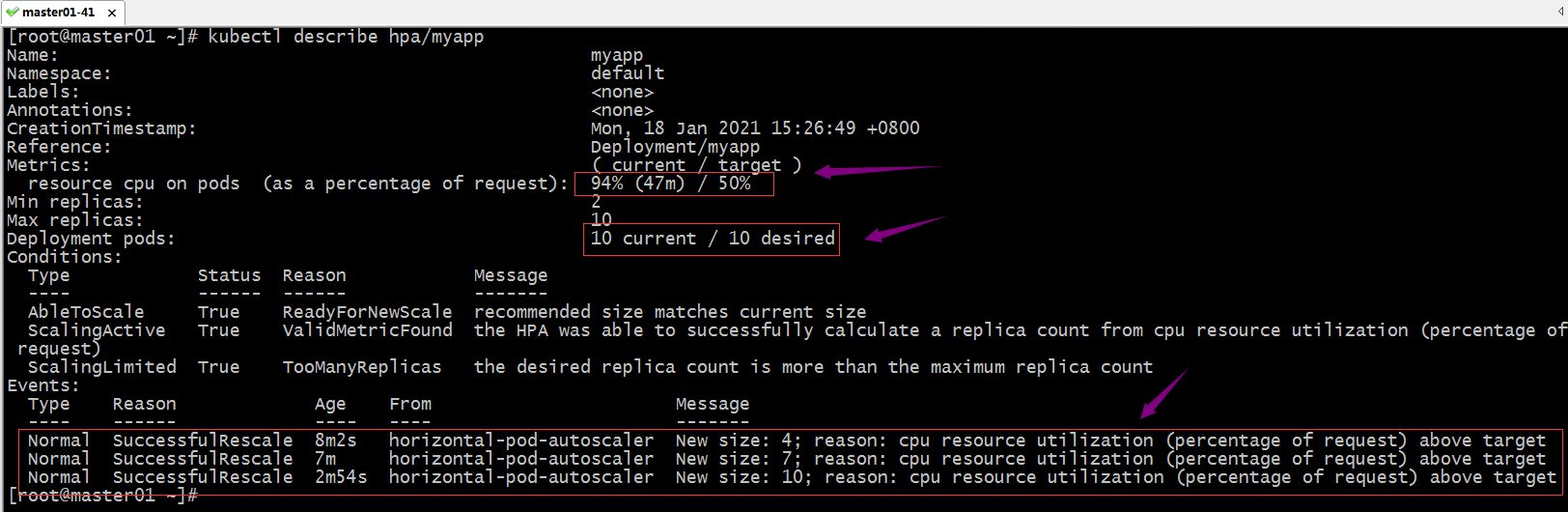
提示:可以看到对应pod被扩展到10个,但是对应cpu资源使用率为94%,此时pod数量已经到达上限,即便对应指标数据还是大于指定的阀值,它也不会扩展;
查看pod数量是否为10个?
[root@master01 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE myapp-779867bcfc-57zw7 1/1 Running 0 5m39s myapp-779867bcfc-657qr 1/1 Running 0 23m myapp-779867bcfc-7c4dt 1/1 Running 0 10m myapp-779867bcfc-b2jmn 1/1 Running 0 10m myapp-779867bcfc-dvq6k 1/1 Running 0 5m39s myapp-779867bcfc-fmw7v 1/1 Running 0 9m45s myapp-779867bcfc-hxhj2 1/1 Running 0 9m45s myapp-779867bcfc-n8lmf 1/1 Running 0 5m39s myapp-779867bcfc-txvj8 1/1 Running 0 23m myapp-779867bcfc-xvh58 1/1 Running 0 9m45s [root@master01 ~]#
停止压测,看看对应pod是否会缩减到最低pod数量为2个呢?
[root@master01 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE myapp-779867bcfc-57zw7 1/1 Running 0 8m8s myapp-779867bcfc-657qr 1/1 Running 0 26m myapp-779867bcfc-7c4dt 1/1 Running 0 13m myapp-779867bcfc-b2jmn 1/1 Running 0 13m myapp-779867bcfc-dvq6k 1/1 Running 0 8m8s myapp-779867bcfc-fmw7v 1/1 Running 0 12m myapp-779867bcfc-hxhj2 1/1 Running 0 12m myapp-779867bcfc-n8lmf 1/1 Running 0 8m8s myapp-779867bcfc-txvj8 1/1 Running 0 26m myapp-779867bcfc-xvh58 1/1 Running 0 12m [root@master01 ~]# kubectl top pods NAME CPU(cores) MEMORY(bytes) myapp-779867bcfc-57zw7 0m 4Mi myapp-779867bcfc-657qr 0m 4Mi myapp-779867bcfc-7c4dt 7m 4Mi myapp-779867bcfc-b2jmn 0m 4Mi myapp-779867bcfc-dvq6k 0m 4Mi myapp-779867bcfc-fmw7v 0m 4Mi myapp-779867bcfc-hxhj2 3m 3Mi myapp-779867bcfc-n8lmf 10m 4Mi myapp-779867bcfc-txvj8 0m 4Mi myapp-779867bcfc-xvh58 0m 4Mi [root@master01 ~]#
提示:pod缩减也是不会立刻执行;从上面信息可以看到停止压测对应pod的cpu资源使用率都降下来了;
再次查看对应pod数量
[root@master01 ~]# kubectl top pods NAME CPU(cores) MEMORY(bytes) myapp-779867bcfc-57zw7 0m 4Mi myapp-779867bcfc-657qr 0m 4Mi [root@master01 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE myapp-779867bcfc-57zw7 1/1 Running 0 13m myapp-779867bcfc-657qr 1/1 Running 0 31m [root@master01 ~]#
提示:可以看到对应pod缩减到最低pod副本数量;
查看hpa的详情
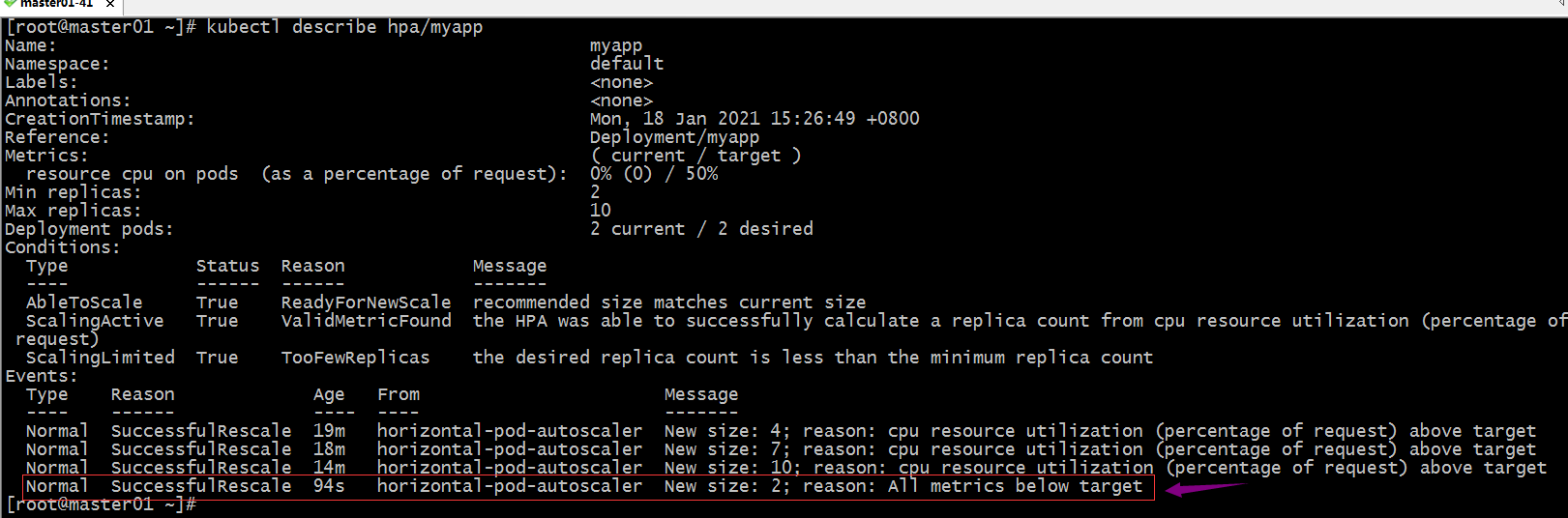
提示:可以看到对应pod的cpu使用率小于50%,它会隔一段时间就缩减对应pod;
示例:使用资源清单定义hpa资源
[root@master01 ~]# cat hpa-demo.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: hpa-demo
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 2
maxReplicas: 10
targetCPUUtilizationPercentage: 50
[root@master01 ~]#
提示:以上是hpa v1的资源清单定义示例,其中targetCPUUtilizationPercentage用于指定cpu资源使用率阀值,50表示50%,即达到pod上限的50%对应hpa就会被触发;
应用清单
[root@master01 ~]# kubectl apply -f hpa-demo.yaml horizontalpodautoscaler.autoscaling/hpa-demo created [root@master01 ~]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE hpa-demo Deployment/myapp <unknown>/50% 2 10 0 8s myapp Deployment/myapp 0%/50% 2 10 2 35m [root@master01 ~]# kubectl describe hpa/hpa-demo Name: hpa-demo Namespace: default Labels: <none> Annotations: <none> CreationTimestamp: Mon, 18 Jan 2021 16:02:25 +0800 Reference: Deployment/myapp Metrics: ( current / target ) resource cpu on pods (as a percentage of request): 0% (0) / 50% Min replicas: 2 Max replicas: 10 Deployment pods: 2 current / 2 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request) ScalingLimited False DesiredWithinRange the desired count is within the acceptable range Events: <none> [root@master01 ~]#
提示:可以看到使用命令创建hpa和使用资源清单创建hpa其创建出来的hpa都是一样的;以上是hpa v1的使用示例和相关说明;使用命令创建hpa,只能创建v1的hpa;v2必须使用资源清单,明确指定对应hpa的群组版本;
使用自定义资源指标定义hpa
部署自定义资源指标服务器
下载部署清单
[root@master01 ~]# mkdir custom-metrics-server [root@master01 ~]# cd custom-metrics-server [root@master01 custom-metrics-server]# git clone https://github.com/stefanprodan/k8s-prom-hpa Cloning into 'k8s-prom-hpa'... remote: Enumerating objects: 223, done. remote: Total 223 (delta 0), reused 0 (delta 0), pack-reused 223 Receiving objects: 100% (223/223), 102.23 KiB | 14.00 KiB/s, done. Resolving deltas: 100% (117/117), done. [root@master01 custom-metrics-server]# ls k8s-prom-hpa [root@master01 custom-metrics-server]#
查看custom-metrics-server的部署清单
[root@master01 custom-metrics-server]# cd k8s-prom-hpa/
[root@master01 k8s-prom-hpa]# ls
custom-metrics-api diagrams ingress LICENSE Makefile metrics-server namespaces.yaml podinfo prometheus README.md
[root@master01 k8s-prom-hpa]# cd custom-metrics-api/
[root@master01 custom-metrics-api]# ls
custom-metrics-apiserver-auth-delegator-cluster-role-binding.yaml custom-metrics-apiservice.yaml
custom-metrics-apiserver-auth-reader-role-binding.yaml custom-metrics-cluster-role.yaml
custom-metrics-apiserver-deployment.yaml custom-metrics-config-map.yaml
custom-metrics-apiserver-resource-reader-cluster-role-binding.yaml custom-metrics-resource-reader-cluster-role.yaml
custom-metrics-apiserver-service-account.yaml hpa-custom-metrics-cluster-role-binding.yaml
custom-metrics-apiserver-service.yaml
[root@master01 custom-metrics-api]# cat custom-metrics-apiserver-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: custom-metrics-apiserver
name: custom-metrics-apiserver
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: custom-metrics-apiserver
template:
metadata:
labels:
app: custom-metrics-apiserver
name: custom-metrics-apiserver
spec:
serviceAccountName: custom-metrics-apiserver
containers:
- name: custom-metrics-apiserver
image: quay.io/coreos/k8s-prometheus-adapter-amd64:v0.4.1
args:
- /adapter
- --secure-port=6443
- --tls-cert-file=/var/run/serving-cert/serving.crt
- --tls-private-key-file=/var/run/serving-cert/serving.key
- --logtostderr=true
- --prometheus-url=http://prometheus.monitoring.svc:9090/
- --metrics-relist-interval=30s
- --v=10
- --config=/etc/adapter/config.yaml
ports:
- containerPort: 6443
volumeMounts:
- mountPath: /var/run/serving-cert
name: volume-serving-cert
readOnly: true
- mountPath: /etc/adapter/
name: config
readOnly: true
volumes:
- name: volume-serving-cert
secret:
secretName: cm-adapter-serving-certs
- name: config
configMap:
name: adapter-config
[root@master01 custom-metrics-api]#
提示:上述清单中明确定义了把自定义指标服务器部署到monitoring名称空间下,对应server的启动还挂在了secret证书;所以应用上述清单前,我们要先创建名称空间和secret;在创建secret前还要先准备好证书和私钥;这里还需要注意custom-metrics-server是连接Prometheus server,把对应自定义数据通过apiservice注册到对应原生apiserver上,供k8s组件使用,所以这里要注意对应Prometheus的地址;
创建monitoring名称空间
[root@master01 custom-metrics-api]# cd .. [root@master01 k8s-prom-hpa]# ls custom-metrics-api diagrams ingress LICENSE Makefile metrics-server namespaces.yaml podinfo prometheus README.md [root@master01 k8s-prom-hpa]# cat namespaces.yaml --- apiVersion: v1 kind: Namespace metadata: name: monitoring [root@master01 k8s-prom-hpa]# kubectl apply -f namespaces.yaml namespace/monitoring created [root@master01 k8s-prom-hpa]# kubectl get ns NAME STATUS AGE default Active 41d ingress-nginx Active 27d kube-node-lease Active 41d kube-public Active 41d kube-system Active 41d kubernetes-dashboard Active 16d mongodb Active 4d20h monitoring Active 4s [root@master01 k8s-prom-hpa]#
生成serving.key和serving.csr
[root@master01 k8s-prom-hpa]# cd /etc/kubernetes/pki/ [root@master01 pki]# ls apiserver.crt apiserver.key ca.crt etcd front-proxy-client.crt sa.pub tom.key apiserver-etcd-client.crt apiserver-kubelet-client.crt ca.key front-proxy-ca.crt front-proxy-client.key tom.crt apiserver-etcd-client.key apiserver-kubelet-client.key ca.srl front-proxy-ca.key sa.key tom.csr [root@master01 pki]# openssl genrsa -out serving.key 2048 Generating RSA private key, 2048 bit long modulus .............................................................................................................................................................+++ ..............................+++ e is 65537 (0x10001) [root@master01 pki]# openssl req -new -key ./serving.key -out ./serving.csr -subj "/CN=serving" [root@master01 pki]# ll total 80 -rw-r--r-- 1 root root 1277 Dec 8 14:38 apiserver.crt -rw-r--r-- 1 root root 1135 Dec 8 14:38 apiserver-etcd-client.crt -rw------- 1 root root 1679 Dec 8 14:38 apiserver-etcd-client.key -rw------- 1 root root 1679 Dec 8 14:38 apiserver.key -rw-r--r-- 1 root root 1143 Dec 8 14:38 apiserver-kubelet-client.crt -rw------- 1 root root 1679 Dec 8 14:38 apiserver-kubelet-client.key -rw-r--r-- 1 root root 1066 Dec 8 14:38 ca.crt -rw------- 1 root root 1675 Dec 8 14:38 ca.key -rw-r--r-- 1 root root 17 Jan 17 13:03 ca.srl drwxr-xr-x 2 root root 162 Dec 8 14:38 etcd -rw-r--r-- 1 root root 1078 Dec 8 14:38 front-proxy-ca.crt -rw------- 1 root root 1675 Dec 8 14:38 front-proxy-ca.key -rw-r--r-- 1 root root 1103 Dec 8 14:38 front-proxy-client.crt -rw------- 1 root root 1679 Dec 8 14:38 front-proxy-client.key -rw------- 1 root root 1679 Dec 8 14:38 sa.key -rw------- 1 root root 451 Dec 8 14:38 sa.pub -rw-r--r-- 1 root root 887 Jan 18 16:54 serving.csr -rw-r--r-- 1 root root 1679 Jan 18 16:54 serving.key -rw-r--r-- 1 root root 993 Dec 30 00:29 tom.crt -rw-r--r-- 1 root root 907 Dec 30 00:27 tom.csr -rw-r--r-- 1 root root 1675 Dec 30 00:21 tom.key [root@master01 pki]#
用kubenetes CA的key和证书为custom-metrics-server签署证书
[root@master01 pki]# openssl x509 -req -in serving.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out serving.crt -days 3650 Signature ok subject=/CN=serving Getting CA Private Key [root@master01 pki]# ll serving.crt -rw-r--r-- 1 root root 977 Jan 18 16:55 serving.crt [root@master01 pki]#
在monitoring名称空间下创建secret资源
[root@master01 pki]# kubectl create secret generic cm-adapter-serving-certs --from-file=./serving.key --from-file=./serving.crt -n monitoring secret/cm-adapter-serving-certs created [root@master01 pki]# kubectl get secret -n monitoring NAME TYPE DATA AGE cm-adapter-serving-certs Opaque 2 10s default-token-k64tz kubernetes.io/service-account-token 3 2m27s [root@master01 pki]# kubectl describe secret/cm-adapter-serving-certs -n monitoring Name: cm-adapter-serving-certs Namespace: monitoring Labels: <none> Annotations: <none> Type: Opaque Data ==== serving.crt: 977 bytes serving.key: 1679 bytes [root@master01 pki]#
提示:这里一定要使用generic类型创建secret,保持对应的名称为serving.key和serving.crt;创建secret的名称,必须同custom-metrics部署清单中的名称保持一致;
部署prometheus
[root@master01 pki]# cd /root/custom-metrics-server/k8s-prom-hpa/prometheus/
[root@master01 prometheus]# ls
prometheus-cfg.yaml prometheus-dep.yaml prometheus-rbac.yaml prometheus-svc.yaml
[root@master01 prometheus]# cat prometheus-dep.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
annotations:
prometheus.io/scrape: 'false'
spec:
serviceAccountName: prometheus
containers:
- name: prometheus
image: prom/prometheus:v2.1.0
imagePullPolicy: Always
command:
- prometheus
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.retention=1h
ports:
- containerPort: 9090
protocol: TCP
resources:
limits:
memory: 2Gi
volumeMounts:
- mountPath: /etc/prometheus/prometheus.yml
name: prometheus-config
subPath: prometheus.yml
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
items:
- key: prometheus.yml
path: prometheus.yml
mode: 0644
[root@master01 prometheus]#
更改rbac资源清单中的群组版本为 rbac.authorization.k8s.io/v1
[root@master01 prometheus]# cat prometheus-rbac.yaml --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: prometheus rules: - apiGroups: [""] resources: - nodes - nodes/proxy - services - endpoints - pods verbs: ["get", "list", "watch"] - apiGroups: - extensions resources: - ingresses verbs: ["get", "list", "watch"] - nonResourceURLs: ["/metrics"] verbs: ["get"] --- apiVersion: v1 kind: ServiceAccount metadata: name: prometheus namespace: monitoring --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: prometheus subjects: - kind: ServiceAccount name: prometheus namespace: monitoring [root@master01 prometheus]#
应用prometheus目录下的所有资源清单
[root@master01 prometheus]# kubectl apply -f . configmap/prometheus-config created deployment.apps/prometheus created clusterrole.rbac.authorization.k8s.io/prometheus created serviceaccount/prometheus created clusterrolebinding.rbac.authorization.k8s.io/prometheus created service/prometheus created [root@master01 prometheus]# kubectl get pods -n monitoring NAME READY STATUS RESTARTS AGE prometheus-5c5dc6d6d4-drrht 1/1 Running 0 26s [root@master01 prometheus]# kubectl get svc -n monitoring NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE prometheus NodePort 10.99.1.110 <none> 9090:31190/TCP 35s [root@master01 prometheus]#
部署自定义指标服务,应用custom-metrics-server目录下的所有资源清单
[root@master01 prometheus]# cd ../custom-metrics-api/ [root@master01 custom-metrics-api]# ls custom-metrics-apiserver-auth-delegator-cluster-role-binding.yaml custom-metrics-apiservice.yaml custom-metrics-apiserver-auth-reader-role-binding.yaml custom-metrics-cluster-role.yaml custom-metrics-apiserver-deployment.yaml custom-metrics-config-map.yaml custom-metrics-apiserver-resource-reader-cluster-role-binding.yaml custom-metrics-resource-reader-cluster-role.yaml custom-metrics-apiserver-service-account.yaml hpa-custom-metrics-cluster-role-binding.yaml custom-metrics-apiserver-service.yaml [root@master01 custom-metrics-api]# kubectl apply -f . clusterrolebinding.rbac.authorization.k8s.io/custom-metrics:system:auth-delegator created rolebinding.rbac.authorization.k8s.io/custom-metrics-auth-reader created deployment.apps/custom-metrics-apiserver created clusterrolebinding.rbac.authorization.k8s.io/custom-metrics-resource-reader created serviceaccount/custom-metrics-apiserver created service/custom-metrics-apiserver created apiservice.apiregistration.k8s.io/v1beta1.custom.metrics.k8s.io created clusterrole.rbac.authorization.k8s.io/custom-metrics-server-resources created configmap/adapter-config created clusterrole.rbac.authorization.k8s.io/custom-metrics-resource-reader created clusterrolebinding.rbac.authorization.k8s.io/hpa-controller-custom-metrics created [root@master01 custom-metrics-api]# kubectl get pods -n monitoring NAME READY STATUS RESTARTS AGE custom-metrics-apiserver-754dfc87c7-cdhqj 1/1 Running 0 18s prometheus-5c5dc6d6d4-drrht 1/1 Running 0 6m9s [root@master01 custom-metrics-api]# kubectl get svc -n monitoring NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE custom-metrics-apiserver ClusterIP 10.99.245.190 <none> 443/TCP 31s prometheus NodePort 10.99.1.110 <none> 9090:31190/TCP 6m21s [root@master01 custom-metrics-api]#
提示:应用上述清单前,请把所有rbac.authorization.k8s.io/v1beta1更改为rbac.authorization.k8s.io/v1,把apiservice中的版本为apiregistration.k8s.io/v1;如果是1.17之前的k8s,不用修改;
验证:查看原生apiserver是否有custom.metrics.k8s.io的群组注册进来?
[root@master01 custom-metrics-api]# kubectl api-versions|grep custom custom.metrics.k8s.io/v1beta1 [root@master01 custom-metrics-api]#
验证:访问对应群组,看看是否能够请求到自定义资源指标?
[root@master01 custom-metrics-api]# kubectl get --raw "/apis/metrics.k8s.io/v1beta1/" | jq .
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "metrics.k8s.io/v1beta1",
"resources": [
{
"name": "nodes",
"singularName": "",
"namespaced": false,
"kind": "NodeMetrics",
"verbs": [
"get",
"list"
]
},
{
"name": "pods",
"singularName": "",
"namespaced": true,
"kind": "PodMetrics",
"verbs": [
"get",
"list"
]
}
]
}
[root@master01 custom-metrics-api]#
提示:如果访问对应群组能够响应数据,表示自定义资源指标服务器没有问题;
示例:创建podinfo pod,该pod输出http_requests资源指标
[root@master01 custom-metrics-api]# cd ..
[root@master01 k8s-prom-hpa]# ls
custom-metrics-api diagrams ingress LICENSE Makefile metrics-server namespaces.yaml podinfo prometheus README.md
[root@master01 k8s-prom-hpa]# cd podinfo/
[root@master01 podinfo]# ls
podinfo-dep.yaml podinfo-hpa-custom.yaml podinfo-hpa.yaml podinfo-ingress.yaml podinfo-svc.yaml
[root@master01 podinfo]# cat podinfo-dep.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
selector:
matchLabels:
app: podinfo
replicas: 2
template:
metadata:
labels:
app: podinfo
annotations:
prometheus.io/scrape: "true"
spec:
containers:
- name: podinfod
image: stefanprodan/podinfo:0.0.1
imagePullPolicy: Always
command:
- ./podinfo
- -port=9898
- -logtostderr=true
- -v=2
volumeMounts:
- name: metadata
mountPath: /etc/podinfod/metadata
readOnly: true
ports:
- containerPort: 9898
protocol: TCP
readinessProbe:
httpGet:
path: /readyz
port: 9898
initialDelaySeconds: 1
periodSeconds: 2
failureThreshold: 1
livenessProbe:
httpGet:
path: /healthz
port: 9898
initialDelaySeconds: 1
periodSeconds: 3
failureThreshold: 2
resources:
requests:
memory: "32Mi"
cpu: "1m"
limits:
memory: "256Mi"
cpu: "100m"
volumes:
- name: metadata
downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "annotations"
fieldRef:
fieldPath: metadata.annotations
[root@master01 podinfo]# cat podinfo-svc.yaml
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
labels:
app: podinfo
spec:
type: NodePort
ports:
- port: 9898
targetPort: 9898
nodePort: 31198
protocol: TCP
selector:
app: podinfo
[root@master01 podinfo]#
应用资源清单
[root@master01 podinfo]# kubectl apply -f podinfo-dep.yaml,./podinfo-svc.yaml deployment.apps/podinfo created service/podinfo created [root@master01 podinfo]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 8d myapp-svc NodePort 10.111.14.219 <none> 80:31154/TCP 4h35m podinfo NodePort 10.111.10.211 <none> 9898:31198/TCP 17s [root@master01 podinfo]# kubectl get pods NAME READY STATUS RESTARTS AGE myapp-779867bcfc-57zw7 1/1 Running 0 4h18m myapp-779867bcfc-657qr 1/1 Running 0 4h36m podinfo-56874dc7f8-5rb9q 1/1 Running 0 40s podinfo-56874dc7f8-t6jgn 1/1 Running 0 40s [root@master01 podinfo]#
验证:访问podinfo svc,看看对应pod是否能够正常访问?
[root@master01 podinfo]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 8d myapp-svc NodePort 10.111.14.219 <none> 80:31154/TCP 4h37m podinfo NodePort 10.111.10.211 <none> 9898:31198/TCP 116s [root@master01 podinfo]# curl 10.111.10.211:9898 runtime: arch: amd64 external_ip: "" max_procs: "4" num_cpu: "4" num_goroutine: "9" os: linux version: go1.9.2 labels: app: podinfo pod-template-hash: 56874dc7f8 annotations: cni.projectcalico.org/podIP: 10.244.3.133/32 cni.projectcalico.org/podIPs: 10.244.3.133/32 kubernetes.io/config.seen: 2021-01-18T19:57:31.325293640+08:00 kubernetes.io/config.source: api prometheus.io/scrape: "true" environment: HOME: /root HOSTNAME: podinfo-56874dc7f8-5rb9q KUBERNETES_PORT: tcp://10.96.0.1:443 KUBERNETES_PORT_443_TCP: tcp://10.96.0.1:443 KUBERNETES_PORT_443_TCP_ADDR: 10.96.0.1 KUBERNETES_PORT_443_TCP_PORT: "443" KUBERNETES_PORT_443_TCP_PROTO: tcp KUBERNETES_SERVICE_HOST: 10.96.0.1 KUBERNETES_SERVICE_PORT: "443" KUBERNETES_SERVICE_PORT_HTTPS: "443" MYAPP_SVC_PORT: tcp://10.111.14.219:80 MYAPP_SVC_PORT_80_TCP: tcp://10.111.14.219:80 MYAPP_SVC_PORT_80_TCP_ADDR: 10.111.14.219 MYAPP_SVC_PORT_80_TCP_PORT: "80" MYAPP_SVC_PORT_80_TCP_PROTO: tcp MYAPP_SVC_SERVICE_HOST: 10.111.14.219 MYAPP_SVC_SERVICE_PORT: "80" MYAPP_SVC_SERVICE_PORT_HTTP: "80" PATH: /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin PODINFO_PORT: tcp://10.111.10.211:9898 PODINFO_PORT_9898_TCP: tcp://10.111.10.211:9898 PODINFO_PORT_9898_TCP_ADDR: 10.111.10.211 PODINFO_PORT_9898_TCP_PORT: "9898" PODINFO_PORT_9898_TCP_PROTO: tcp PODINFO_SERVICE_HOST: 10.111.10.211 PODINFO_SERVICE_PORT: "9898" [root@master01 podinfo]#
验证:访问apiserver,看看对应pod输出的http_requests资源指标是否能够被访问到?
[root@master01 podinfo]# kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests" | jq .
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests"
},
"items": [
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "podinfo-56874dc7f8-5rb9q",
"apiVersion": "/v1"
},
"metricName": "http_requests",
"timestamp": "2021-01-18T12:01:41Z",
"value": "911m"
},
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "podinfo-56874dc7f8-t6jgn",
"apiVersion": "/v1"
},
"metricName": "http_requests",
"timestamp": "2021-01-18T12:01:41Z",
"value": "888m"
}
]
}
[root@master01 podinfo]#
提示:可以看到现在用kubectl 工具可以在apiserver上访问到对应pod提供的自定义指标数据;
示例:根据自定义指标数据,定义hpa资源
[root@master01 podinfo]# cat podinfo-hpa-custom.yaml
---
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: podinfo
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: podinfo
minReplicas: 2
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: http_requests
target:
type: AverageValue
averageValue: 10
[root@master01 podinfo]#
提示:使用自定义资源指标,对应hpa的群组必须为autoscale/v2beta2;对应自定义指标用metrics字段给定;type用来描述对应自定义指标数据是什么类型,pod表示是pod自身提供的自定义指标数据;上述资源清单表示引用pod自身的自定义指标数据,其名称为http_requests;对该指标数据的平均值做监控,如果对应指标平均值大于10,则触发hpa对其扩展,当对应指标数据小于10,对应hpa会对应进行缩减操作;
应用资源清单
[root@master01 podinfo]# kubectl apply -f podinfo-hpa-custom.yaml horizontalpodautoscaler.autoscaling/podinfo created [root@master01 podinfo]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE hpa-demo Deployment/myapp 0%/50% 2 10 2 4h1m myapp Deployment/myapp 0%/50% 2 10 2 4h37m podinfo Deployment/podinfo <unknown>/10 2 10 0 6s [root@master01 podinfo]# kubectl describe hpa/podinfo Name: podinfo Namespace: default Labels: <none> Annotations: <none> CreationTimestamp: Mon, 18 Jan 2021 20:04:14 +0800 Reference: Deployment/podinfo Metrics: ( current / target ) "http_requests" on pods: 899m / 10 Min replicas: 2 Max replicas: 10 Deployment pods: 2 current / 2 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric http_requests ScalingLimited False DesiredWithinRange the desired count is within the acceptable range Events: <none> [root@master01 podinfo]#
对podinfo 进行压测,看看对应hpa是否能够自动扩展?
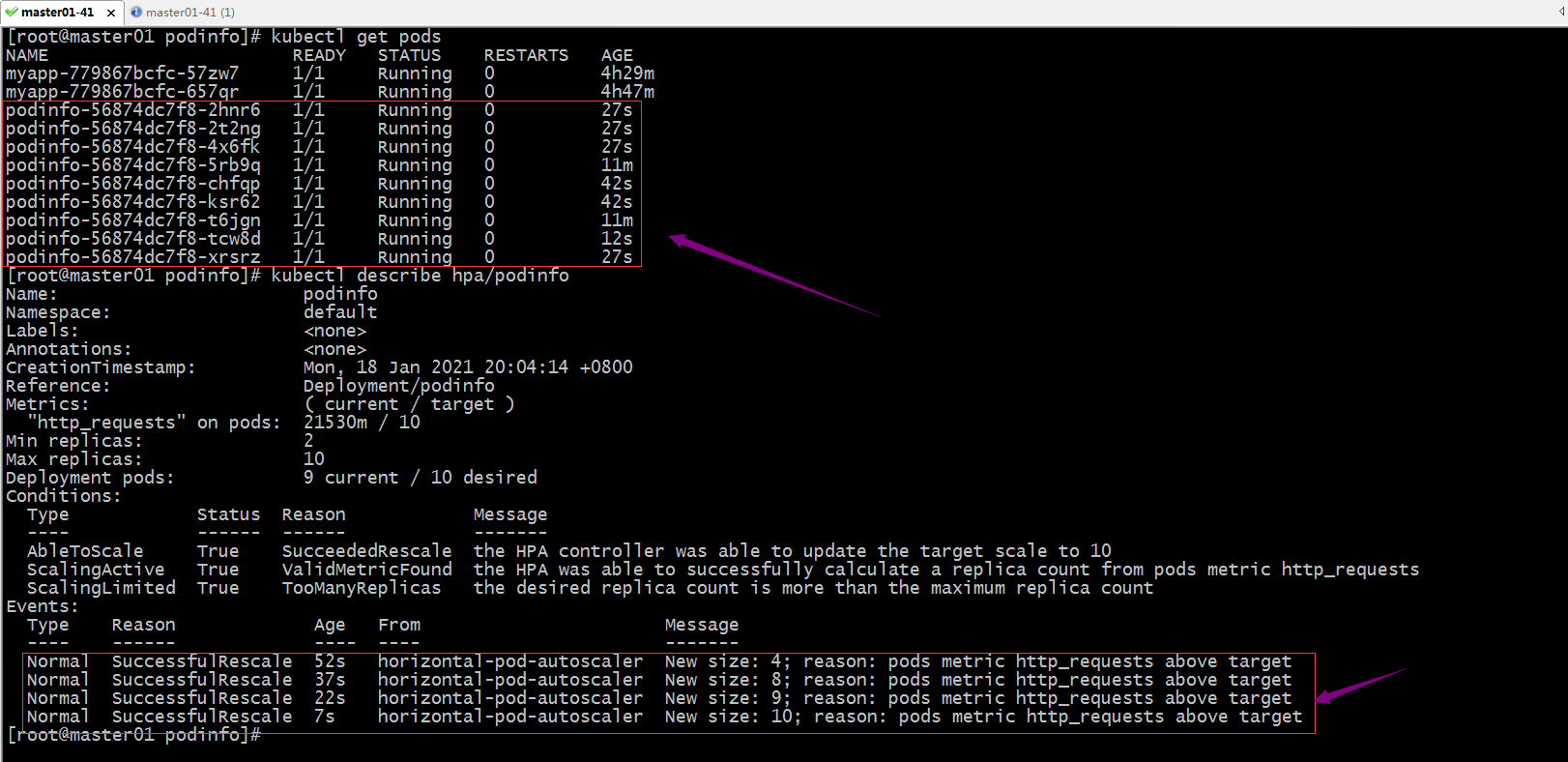
提示:可以看到对应pod能够被对应的hpa通过自定义指标来扩展pod数量;
停止压测,看看对应pod是否会自动缩减至最低数量? 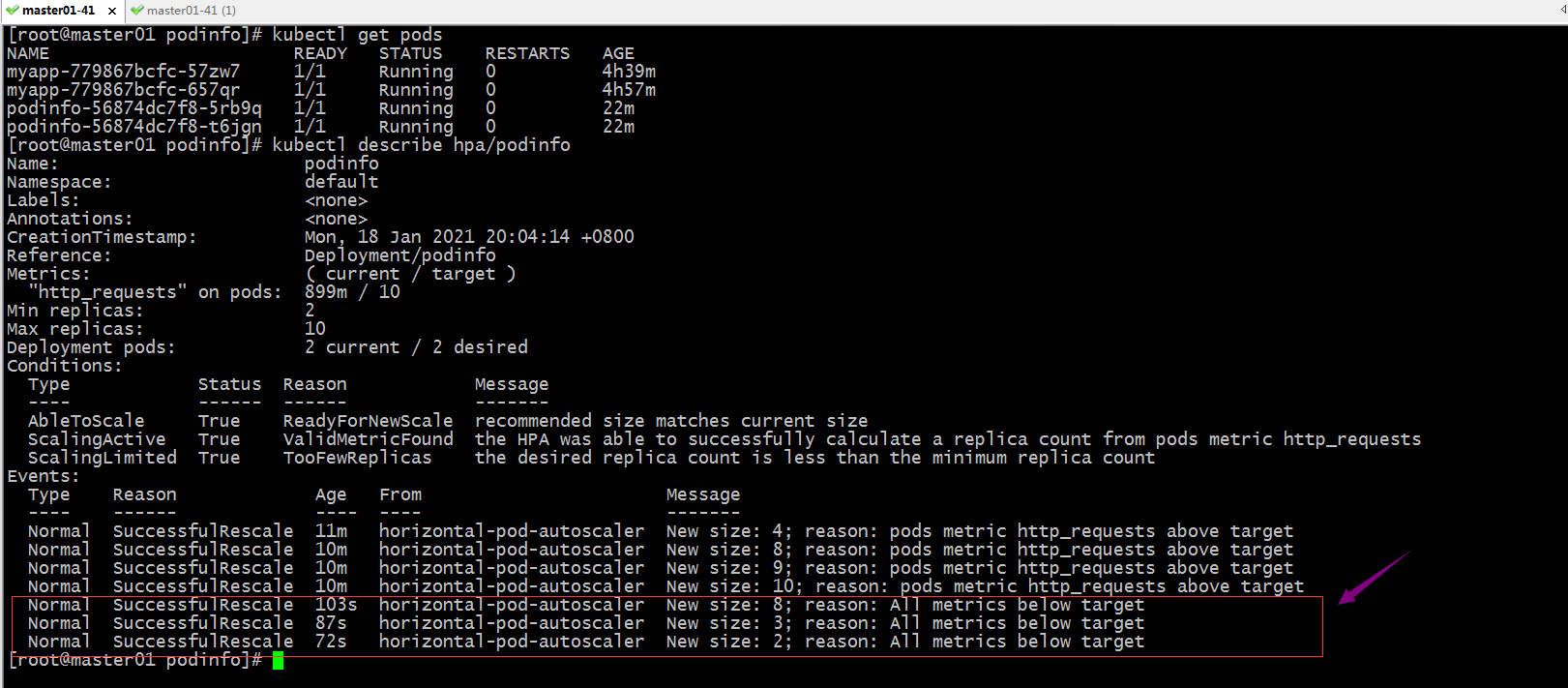
提示:可以看到停止压测以后,对应的指标数据降低下来,对应的pod也随之缩减到最低副本数量;以上就是hpa v2的简单使用方式,更多示例和说明请参考官方文档https://kubernetes.io/zh/docs/tasks/run-application/horizontal-pod-autoscale/;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号