利用Python爬虫获取NBA比赛数据并进行机器学习预测NBA比赛结果
一、选题背景
随着人工智能和数据科学的快速发展,运用机器学习算法进行体育比赛结果预测已成为一个引人注目的领域。在体育竞技中,尤其是像NBA这样的全球知名联赛中,比赛结果的预测对于球迷、投注者和分析师都具有重要意义。
然而,要准确地预测NBA比赛结果并不是一项容易的任务,因为涉及到多个因素,如球员的表现、球队的战术、伤病情况、主客场优势等等。为了解决这个问题,我们可以借助Python编程语言中的爬虫技术获取NBA比赛的历史数据,并利用机器学习算法进行预测。
二、程序设计方案
-
数据获取和准备:
- 使用Python的爬虫库从可靠的NBA数据源(如官方网站或统计网站)中获取比赛数据。
- 获取比赛结果、球队数据、球员数据等相关信息,并保存到本地文件或数据库中。
- 对获取的原始数据进行清洗和整理,处理缺失值和异常值。
- 数据来源:https://www.lanqiao.cn/courses/782/learning/?id=2647
-
数据分析和特征选择:
- 对获取的数据进行探索性分析,了解数据的分布和特征之间的关系。
- 选择对比赛结果有影响的关键特征,如球队胜率、得分、篮板、助攻等。
- 进行特征工程,如标准化、归一化、特征组合等,以提高模型的性能。
-
数据建模和训练:
- 划分数据集为训练集和测试集,通常采用交叉验证的方法进行模型评估。
- 选择适当的机器学习算法,如决策树、随机森林、支持向量机等,用于预测比赛结果。
- 针对选定的算法,根据训练集进行模型训练,并进行参数调优。
-
模型评估和预测:
- 使用测试集对训练好的模型进行评估,计算准确率、精确率、召回率等指标。
- 分析模型在不同场景下的性能,并进行必要的调整和改进。
- 使用训练好的模型对新的比赛数据进行预测,得出预测结果。
-
结果展示和应用:
- 将预测结果可视化展示,如制作比赛胜负预测的图表或报告。
- 将模型应用到实际场景中,如进行实时比赛结果预测或提供比赛推荐。
- 项目需要的数据文件
-
本项目中一共需要5张数据表,分别是Team Per Ganme Stats(各球队每场比赛数据统计)、Opponent Per Game Stats(对手平均平常比赛的数据统计)、Miscellaneous Stats(各球队综合统计数据表)、2015-2016 NBA Schedule and Results(2015-16赛季比赛安排与结果)、2016-2017 NBA Schedule and Results(2016-2015赛季比赛安排)。
-
三、项目原理介绍
- 比赛数据
本项目中,采用来自与NBA网站的数据。在该网站中,可以获取到任意球队、任意球员的各类比赛统计数据,如得分、投篮次数、犯规次数等等。
(注:NBA网站链接https://www.basketball-reference.com/)
在本网站中,主要使用2020-21赛季中的数据,分别是:
Team Per Ganme Stats表格:每支队伍平均每场比赛的表现统计;
Opponent Per Game Stats表格:所遇到的对手平均每场比赛的统计信息,所包含的统计数据与 Team Per Game Stats 中的一致,只是代表的是该球队对应的对手的统计信息;
Miscellaneous Stats:综合统计数据。(在网站中名为Advanced Stats。)
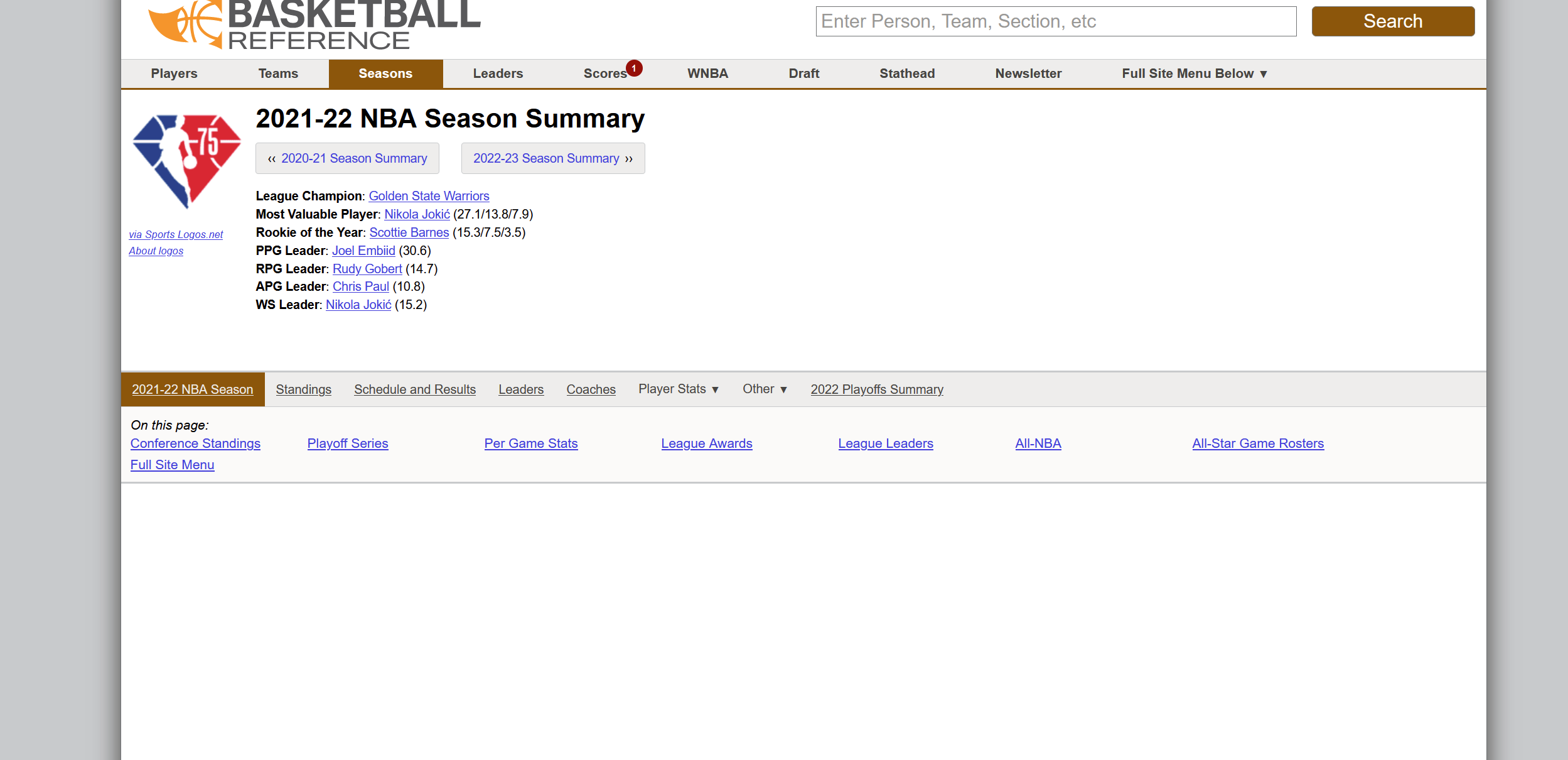
Team Per Game Stats表格、Opponent Per Game Stats表格、Miscellaneous Stats表格(在NBA网站中叫做“Advanced Stats”)中的数据字段含义如下图所示。
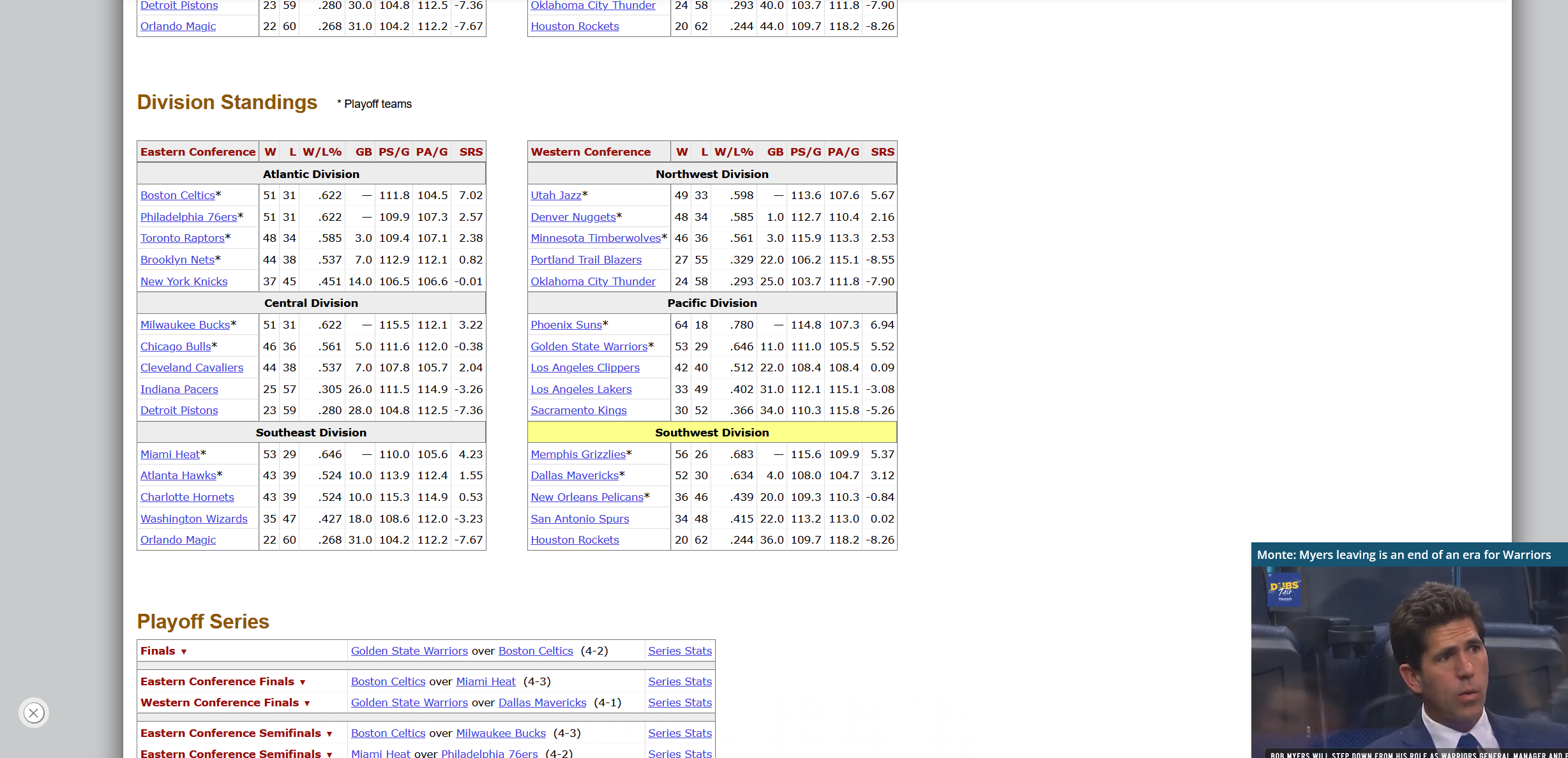
除了以上三个表外,还需要另外两个表数据,即:
2020-2021
NBA Schedule and Results:2020-2021 年的 NBA 常规赛及季后赛的每场比赛的比赛数据;2020-2021
NBA Schedule and Results 中 2020-2021 年的 NBA 的常规赛比赛安排数据。
获取数据后,需要对表中的字段进行修改。
表格数据字段含义说明:Vteam: 客场作战队伍。Hteam: 主场作战队伍
故综上所述一共需要5张NBA数据表。
2、数据分析原理
在获取到五个表格数据之后,将利用每支队伍过去的比赛情况和 Elo 等级分来分析每支比赛队伍的胜利概率。
分析与评价每支队伍过去的比赛表现时,将使用到上述五张表中的三张表,分别是 Team Per Game Stats、Opponent Per Game Stats 和 Miscellaneous Stats(后文中将简称为 T、O 和 M 表)。
这三张表的数据作为比赛中代表某支球队的比赛特征。代码会预测每场比赛最终哪支球队会获胜,但这并不给出绝对的胜利或失败,而是预测获胜球队获胜的概率。
因此将建立一个代表比赛的特征向量。由两支队伍的以往比赛统计情况(T、O 和M表)和两个队伍各自的 Elo 等级分构成。
四、网络爬虫程序设计
1.爬取NBA球队数据
import requests
import re
import csv
class NBASpider:
def __init__(self):
self.url = "https://www.basketball-reference.com/leagues/NBA_2020.html"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/65.0.3325.181 "
"Safari/537.36"
}
# 发送请求,获取数据
def send(self):
response = requests.get(self.url)
response.encoding = 'utf-8'
return response.text
# 解析html
def parse(self, html):
team_heads, team_datas = self.get_team_info(html)
opponent_heads, opponent_datas = self.get_opponent_info(html)
return team_heads, team_datas, opponent_heads, opponent_datas
def get_team_info(self, html):
"""
通过正则从获取到的html页面数据中team表的表头和各行数据
:param html 爬取到的页面数据
:return: team_heads表头
team_datas 列表内容
"""
# 1. 正则匹配数据所在的table
team_table = re.search('<table.*?id="per_game-team".*?>(.*?)</table>', html, re.S).group(1)
# 2. 正则从table中匹配出表头
team_head = re.search('<thead>(.*?)</thead>', team_table, re.S).group(1)
team_heads = re.findall('<th.*?>(.*?)</th>', team_head, re.S)
# 3. 正则从table中匹配出表的各行数据
team_datas = self.get_datas(team_table)
return team_heads, team_datas
# 解析opponent数据
def get_opponent_info(self, html):
"""
通过正则从获取到的html页面数据中opponent表的表头和各行数据
:param html 爬取到的页面数据
"""
# 1. 正则匹配数据所在的table
opponent_table = re.search('<table.*?id="per_game-opponent".*?>(.*?)</table>', html, re.S).group(1)
# 2. 正则从table中匹配出表头
opponent_head = re.search('<thead>(.*?)</thead>', opponent_table, re.S).group(1)
opponent_heads = re.findall('<th.*?>(.*?)</th>', opponent_head, re.S)
# 3. 正则从table中匹配出表的各行数据
opponent_datas = self.get_datas(opponent_table)
return opponent_heads, opponent_datas
# 获取表格body数据
def get_datas(self, table_html):
"""
从tboday数据中解析出实际数据(去掉页面标签)
:param table_html 解析出来的table数据
:return:
"""
tboday = re.search('<tbody>(.*?)</tbody>', table_html, re.S).group(1)
contents = re.findall('<tr.*?>(.*?)</tr>', tboday, re.S)
for oc in contents:
rk = re.findall('<th.*?>(.*?)</th>', oc)
datas = re.findall('<td.*?>(.*?)</td>', oc, re.S)
datas[0] = re.search('<a.*?>(.*?)</a>', datas[0]).group(1)
datas = rk + datas
# yield 声明这个方法是一个生成器, 返回的值是datas
yield datas
# 存储成csv文件
def save_csv(self, title, heads, rows):
f = open(title + '.csv', mode='w', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=heads)
csv_writer.writeheader()
for row in rows:
dict = {}
for i, v in enumerate(heads):
dict[v] = row[i]
csv_writer.writerow(dict)
def crawl(self):
# 1. 发送请求
res = self.send()
# 2. 解析数据
team_heads, team_datas, opponent_heads, opponent_datas = self.parse(res)
# 3. 保存数据为csv
self.save_csv("team", team_heads, team_datas)
self.save_csv("opponent", opponent_heads, opponent_datas)
if __name__ == '__main__':
# 运行爬虫
spider = NBASpider()
spider.crawl()
数据结果:

import requests
import re
import csv
class NBASpider:
def __init__(self):
self.url = "https://www.basketball-reference.com/leagues/NBA_2021.html"
self.schedule_url = "https://www.basketball-reference.com/leagues/NBA_2021_games-{}.html"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 "
"Safari/537.36"
}
# 发送请求,获取数据
def send(self, url):
response = requests.get(url, headers = self.headers)
response.encoding = 'utf-8'
return response.text
# 解析html
def parse(self, html):
team_heads, team_datas = self.get_team_info(html)
opponent_heads, opponent_datas = self.get_opponent_info(html)
return team_heads, team_datas, opponent_heads, opponent_datas
def get_team_info(self, html):
"""
通过正则从获取到的html页面数据中team表的表头和各行数据
:param html 爬取到的页面数据
:return: team_heads表头
team_datas 列表内容
"""
# 1. 正则匹配数据所在的table
team_table = re.search('<table.*?id="per_game-team".*?>(.*?)</table>', html, re.S).group(1)
# 2. 正则从table中匹配出表头
team_head = re.search('<thead>(.*?)</thead>', team_table, re.S).group(1)
team_heads = re.findall('<th.*?>(.*?)</th>', team_head, re.S)
# 3. 正则从table中匹配出表的各行数据
team_datas = self.get_datas(team_table)
return team_heads, team_datas
# 解析opponent数据
def get_opponent_info(self, html):
"""
通过正则从获取到的html页面数据中opponent表的表头和各行数据
:param html 爬取到的页面数据
:return:
"""
# 1. 正则匹配数据所在的table
opponent_table = re.search('<table.*?id="per_game-opponent".*?>(.*?)</table>', html, re.S).group(1)
# 2. 正则从table中匹配出表头
opponent_head = re.search('<thead>(.*?)</thead>', opponent_table, re.S).group(1)
opponent_heads = re.findall('<th.*?>(.*?)</th>', opponent_head, re.S)
# 3. 正则从table中匹配出表的各行数据
opponent_datas = self.get_datas(opponent_table)
return opponent_heads, opponent_datas
# 获取表格body数据
def get_datas(self, table_html):
"""
从tboday数据中解析出实际数据(去掉页面标签)
:param table_html 解析出来的table数据
:return:
"""
tboday = re.search('<tbody>(.*?)</tbody>', table_html, re.S).group(1)
contents = re.findall('<tr.*?>(.*?)</tr>', tboday, re.S)
for oc in contents:
rk = re.findall('<th.*?>(.*?)</th>', oc)
datas = re.findall('<td.*?>(.*?)</td>', oc, re.S)
datas[0] = re.search('<a.*?>(.*?)</a>', datas[0]).group(1)
datas = rk + datas
# yield 声明这个方法是一个生成器, 返回的值是datas
yield datas
def get_schedule_datas(self, table_html):
"""
从tboday数据中解析出实际数据(去掉页面标签)
:param table_html 解析出来的table数据
:return:
"""
tboday = re.search('<tbody>(.*?)</tbody>', table_html, re.S).group(1)
contents = re.findall('<tr.*?>(.*?)</tr>', tboday, re.S)
for oc in contents:
rk = re.findall('<th.*?><a.*?>(.*?)</a></th>', oc)
datas = re.findall('<td.*?>(.*?)</td>', oc, re.S)
if datas and len(datas) > 0:
datas[1] = re.search('<a.*?>(.*?)</a>', datas[1]).group(1)
datas[3] = re.search('<a.*?>(.*?)</a>', datas[3]).group(1)
datas[5] = re.search('<a.*?>(.*?)</a>', datas[5]).group(1)
datas = rk + datas
# yield 声明这个方法是一个生成器, 返回的值是datas
yield datas
def parse_schedule_info(self, html):
"""
通过正则从获取到的html页面数据中team表的表头和各行数据
:param html 爬取到的页面数据
:return: team_heads表头
team_datas 列表内容
"""
# 1. 正则匹配数据所在的table
table = re.search('<table.*?id="schedule" data-cols-to-freeze=",1">(.*?)</table>', html, re.S).group(1)
table = table + "</tbody>"
# 2. 正则从table中匹配出表头
head = re.search('<thead>(.*?)</thead>', table, re.S).group(1)
heads = re.findall('<th.*?>(.*?)</th>', head, re.S)
# 3. 正则从table中匹配出表的各行数据
datas = self.get_schedule_datas(table)
return heads, datas
# 存储成csv文件
def save_csv(self, title, heads, rows):
f = open(title + '.csv', mode='w', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=heads)
csv_writer.writeheader()
for row in rows:
dict = {}
if heads and len(heads) > 0:
for i, v in enumerate(heads):
dict[v] = row[i] if len(row) > i else ""
csv_writer.writerow(dict)
def crawl_team_opponent(self):
# 1. 发送请求
res = self.send(self.url)
# 2. 解析数据
team_heads, team_datas, opponent_heads, opponent_datas = self.parse(res)
# 3. 保存数据为csv
self.save_csv("team", team_heads, team_datas)
self.save_csv("opponent", opponent_heads, opponent_datas)
def crawl_schedule(self):
months = ["october", "november", "december", "january", "february", "march", "april", "may", "june"]
for month in months:
html = self.send(self.schedule_url.format(month))
# print(html)
heads, datas = self.parse_schedule_info(html)
# 3. 保存数据为csv
self.save_csv("schedule_"+month, heads, datas)
def crawl(self):
self.crawl_schedule()
if __name__ == '__main__':
# 运行爬虫
spider = NBASpider()
spider.crawl()
运行结果:
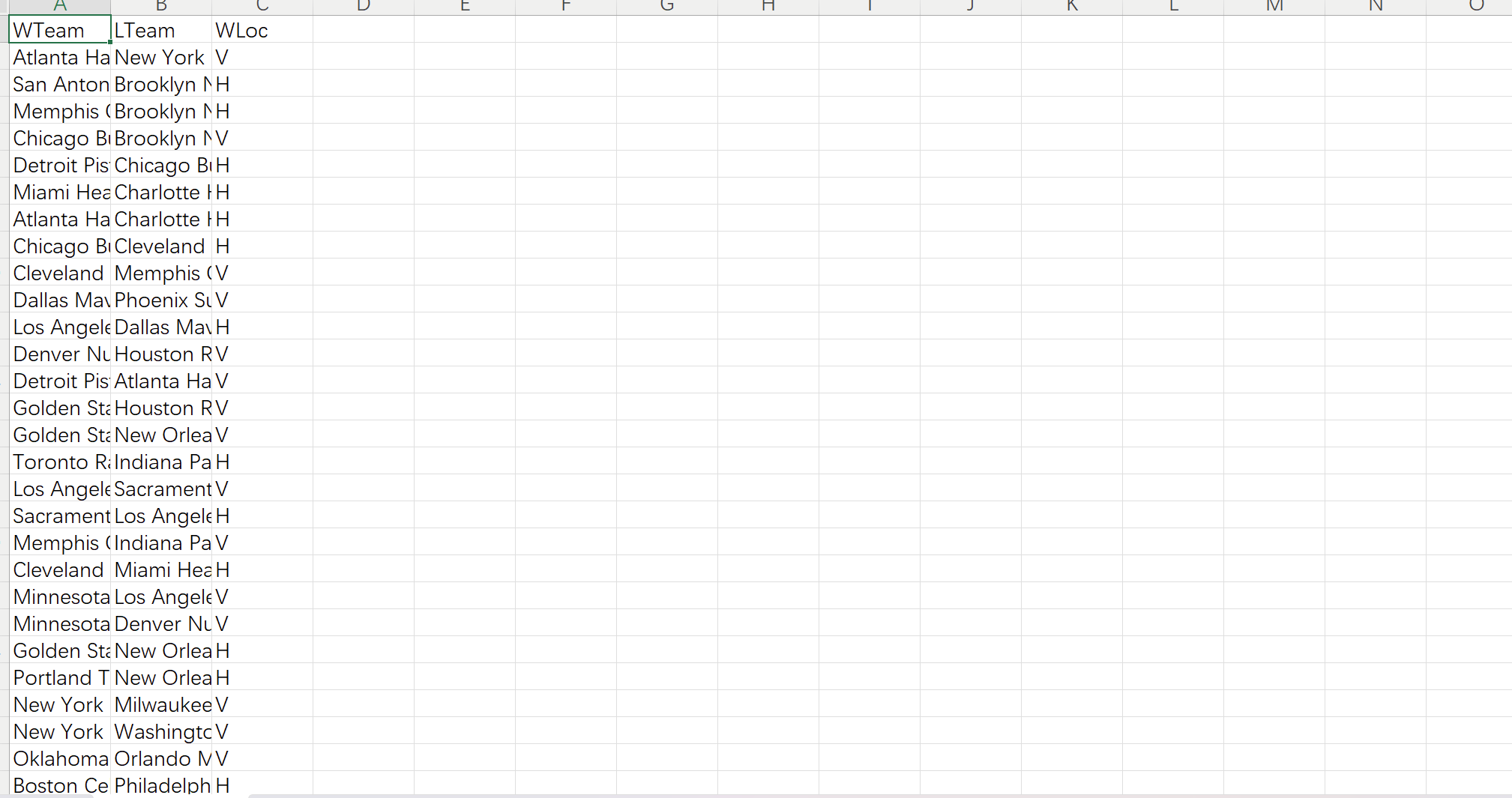
运行代码:
import requests
import re
import csv
from parsel import Selector
class NBASpider:
def __init__(self):
self.url = "https://www.basketball-reference.com/leagues/NBA_2021.html"
self.schedule_url = "https://www.basketball-reference.com/leagues/NBA_2016_games-{}.html"
self.advanced_team_url = "https://www.basketball-reference.com/leagues/NBA_2016.html"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 "
"Safari/537.36"
}
# 发送请求,获取数据
def send(self, url):
response = requests.get(url, headers=self.headers, timeout=30)
response.encoding = 'utf-8'
return response.text
# 解析html
def parse(self, html):
team_heads, team_datas = self.get_team_info(html)
opponent_heads, opponent_datas = self.get_opponent_info(html)
return team_heads, team_datas, opponent_heads, opponent_datas
def get_team_info(self, html):
"""
通过正则从获取到的html页面数据中team表的表头和各行数据
:param html 爬取到的页面数据
:return: team_heads表头
team_datas 列表内容
"""
# 1. 正则匹配数据所在的table
team_table = re.search('<table.*?id="per_game-team".*?>(.*?)</table>', html, re.S).group(1)
# 2. 正则从table中匹配出表头
team_head = re.search('<thead>(.*?)</thead>', team_table, re.S).group(1)
team_heads = re.findall('<th.*?>(.*?)</th>', team_head, re.S)
# 3. 正则从table中匹配出表的各行数据
team_datas = self.get_datas(team_table)
return team_heads, team_datas
# 解析opponent数据
def get_opponent_info(self, html):
"""
通过正则从获取到的html页面数据中opponent表的表头和各行数据
:param html 爬取到的页面数据
:return:
"""
# 1. 正则匹配数据所在的table
opponent_table = re.search('<table.*?id="per_game-opponent".*?>(.*?)</table>', html, re.S).group(1)
# 2. 正则从table中匹配出表头
opponent_head = re.search('<thead>(.*?)</thead>', opponent_table, re.S).group(1)
opponent_heads = re.findall('<th.*?>(.*?)</th>', opponent_head, re.S)
# 3. 正则从table中匹配出表的各行数据
opponent_datas = self.get_datas(opponent_table)
return opponent_heads, opponent_datas
# 获取表格body数据
def get_datas(self, table_html):
"""
从tboday数据中解析出实际数据(去掉页面标签)
:param table_html 解析出来的table数据
:return:
"""
tboday = re.search('<tbody>(.*?)</tbody>', table_html, re.S).group(1)
contents = re.findall('<tr.*?>(.*?)</tr>', tboday, re.S)
for oc in contents:
rk = re.findall('<th.*?>(.*?)</th>', oc)
datas = re.findall('<td.*?>(.*?)</td>', oc, re.S)
datas[0] = re.search('<a.*?>(.*?)</a>', datas[0]).group(1)
datas.insert(0, rk[0])
# yield 声明这个方法是一个生成器, 返回的值是datas
yield datas
def get_schedule_datas(self, table_html):
"""
从tboday数据中解析出实际数据(去掉页面标签)
:param table_html 解析出来的table数据
:return:
"""
tboday = re.search('<tbody>(.*?)</tbody>', table_html, re.S).group(1)
contents = re.findall('<tr.*?>(.*?)</tr>', tboday, re.S)
for oc in contents:
rk = re.findall('<th.*?><a.*?>(.*?)</a></th>', oc)
datas = re.findall('<td.*?>(.*?)</td>', oc, re.S)
if datas and len(datas) > 0:
datas[1] = re.search('<a.*?>(.*?)</a>', datas[1]).group(1)
datas[3] = re.search('<a.*?>(.*?)</a>', datas[3]).group(1)
datas[5] = re.search('<a.*?>(.*?)</a>', datas[5]).group(1)
datas.insert(0, rk[0])
# yield 声明这个方法是一个生成器, 返回的值是datas
yield datas
def get_advanced_team_datas(self, table):
trs = table.xpath('./tbody/tr')
for tr in trs:
rk = tr.xpath('./th/text()').get()
datas = tr.xpath('./td[@data-stat!="DUMMY"]/text()').getall()
datas[0] = tr.xpath('./td/a/text()').get()
datas.insert(0, rk)
yield datas
def parse_schedule_info(self, html):
"""
通过正则从获取到的html页面数据中的表头和各行数据
:param html 爬取到的页面数据
:return: heads表头
datas 列表内容
"""
# 1. 正则匹配数据所在的table
table = re.search('<table.*?id="schedule" data-cols-to-freeze=",1">(.*?)</table>', html, re.S).group(1)
table = table + "</tbody>"
# 2. 正则从table中匹配出表头
head = re.search('<thead>(.*?)</thead>', table, re.S).group(1)
heads = re.findall('<th.*?>(.*?)</th>', head, re.S)
# 3. 正则从table中匹配出表的各行数据
datas = self.get_schedule_datas(table)
return heads, datas
def parse_advanced_team(self, html):
"""