


ALINK(二十二):特征工程(一)特征离散化简介(一)
来源:https://blog.csdn.net/weixin_39552874/article/details/112325629
1 特征离散化方法和实现
特征离散化指的是将连续特征划分离散的过程:将原始定量特征的一个区间一一映射到单一的值。
在下文中,我们也将离散化过程表述为 分箱(Binning) 的过程。
特征离散化常应用于逻辑回归和金融领域的评分卡中,同时在规则提取、特征分类中同样有应用价值。
特征离散化后将带来如下优势:
数据被规约和简化,便于理解和解释,同时有助于模型部署和应用,加快了模型迭代;
增强模型鲁棒性:对于异常值、无效值、缺失值、未见值可统一归为一类,降低噪声,从而避免此类极端值对模型的影响;
增加非线性表达能力:连续特征不同区间对模型贡献或重要度不一样时,分箱后不同的权重能直接体现这种差异,当离散化后的特征再进行特征交叉衍生能进一步加强这种表达能力;
提升模型的泛化能力:总体来说分箱后模型表现更为稳定;
此外,还能扩展数据在不同类型算法中的应用范围;减少存储空间和加速计算等。
当然,离散化也有缺点,例如:
信息损失:分箱必然造成一定程度的信息损失;
增加流程:建模过程加入额外的离散化步骤;
影响模型稳定性:当一个特征值处在分箱点的边缘,微小的偏差会造成该特征值的归属从一箱跃迁到另外一箱,从而影响稳定性。
离散化/分箱可以从不同的角度进行划分。当分箱方法中使用了目标y的信息,那么该分箱方法就属于有监督的分箱方法,反之为无监督的分箱方法。
当分箱的算法策略是不断增加分隔点达到分箱的目的,那么称之为分裂式;反之,当策略是不断的合并原始或粗分箱时则称合并式。
相应的,算法层面上,有监督的方法一般属于贪心算法;分裂式称为自上而下的算法;合并式则称为自底向上的算法。
6.3.1节将讲述常用的分箱算法,图6-5总结了这些算法的分类。
分箱算法的流程总结如下:
预设分箱条件,例如箱数、停止阈值等;
选择某个点作为候选分隔点,由算法中的评价指标衡量该分隔点的效用;
根据该效用是否满足预设的条件,选择分裂/合并或放弃;
当满足预设的停止条件时停止。
算法不同的评价指标代表不同的分箱算法,除了书中给出的分箱算法外,读者完全可以尝试新的方法和策略。
笔者认为离散化的本质是箱/组内差异小,组间差异大。但以下两个不同的目标有不同的权衡:当分箱是作为特征处理方法时,分箱的目标应是为建模服务;
当分箱的目标直接作为规则和预测时则可追求箱内的纯度。
实际上,即使尝试多种分箱方法,我们依然难以找到一个最优解。下文的分箱方法来自工程实践,实验数据依然使用“Breast Cancer Wisconsin (Diagnostic) Database”数据集。
from sklearn.datasets import load_breast_cancer bc = load_breast_cancer() y = bc.target X = pd.DataFrame.from_records(data=bc.data, columns=bc.feature_names) # 转化为df df = X df['target'] = y
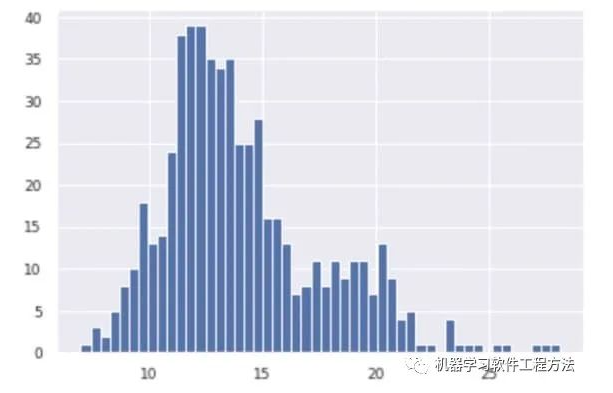
取其中的字段 “mean radius”,其原始分布可视化如图6-6所示。
2 等宽和等频离散法
等宽、等频分箱都属于无监督分箱方法,不需要标签y的信息。由于两者实现简单,应用广泛,例如,便于快速粗筛特征、监控和可视化等。
等宽分箱(Equal-Width Binning):指的是每个分隔点/划分点的距离一样(等宽)。实践中一般指定分隔的箱数,等分计算后得到每个分隔点,例如将数据序列分为n份,则分隔点的宽度计算式为(6-4):
一般情况下,等宽分箱的每个箱内的样本数量不一致,使用Pandas中的cut为例说明如下:
按上述分隔点划分后,数据分布如图6-7所示。
value,cutoff = pd.cut(df['mean radius'],bins=8,retbins=True,precision=2) # cutoff 输出 array([ 6.959871, 9.622125, 12.26325 , 14.904375, 17.5455 , 20.186625, 22.82775 , 25.468875, 28.11 ]) c2 = cutoff.copy() c2[1:] - cutoff[:-1] # 输出:可以看出每个分隔点距离相等 array([2.662254, 2.641125, 2.641125, 2.641125, 2.641125, 2.641125, 2.641125, 2.641125])
等宽方便计算,但是如果数值有很大的差距时,可能会出现没有数据的空箱(如图6-7所示的最后一箱数量非常少)。这个问题可以通过自适应数据分布的分箱方法——等频分箱避免。
3 等频分箱(Equal-Frequency Binning)
等频分箱理论上分隔后的箱内数据量大小一致,但当某个值出现次数较多时,会出现等分边界是同一个值,导致同一数值分到不同的箱内,这是不正确的。具体实现时可去除分界处的重复值,但这也导致每箱的数量不一致。
同样,我们对df['mean radius']使用等频分箱,该数据分布正常,等频分箱后每箱数量基本一致。value的分布如图6-8所示。
value = pd.qcut(df['mean radius'],8,precision=1)
等频分箱的一个特例为分位数分箱,下面以4分位数为例进行说明:
#两者数据的分隔点都是: # array([ 6.981, 11.7 , 13.37 , 15.78 , 28.11 ]) np.array(np.percentile(df['mean radius'], [0,25, 50, 75,100])) # cutoff和上面的分隔点相同 value,cutoff = pd.qcut(df['mean radius'],4,retbins=True)
上述的等宽和等频分箱容易出现的问题是每箱中信息量变化不大。
例如等宽分箱不太适合分布不均匀的数据集、离群值;
等频方法不太适合特定的值占比过多的数据集,如长尾分布。
此外,当将“年龄”这样的特征等频分箱后,极有可能出现每箱中好坏样本的差异不显著,对算法的帮助有限,那么如何才能得到更有意义的分箱呢?
4 信息熵分箱原理与实现
以往离散化的方式常由等宽等频、专家建议、直觉经验等确定,但这对模型构建和效果优化有限。
如果分箱后箱内样本对y的区分度好,那么这是一个较好的分箱。我们从信息论理论出发,可知信息熵衡量了这种区分能力。当特征按某个点划分成上下两部分后能达到最大的信息增益,那么这是一个优选的分箱点。
图6-9演示了信息增益的计算过程,该示例中特征x=(1,2,3,4,5),y=(0,1,0,1,1),以x为3的点作为分隔点,带来的信息增益为0.420。
类似的可以继续计算其他分隔点的信息增益,最终选取信息增益最大时对应的点为分隔点。
同时我们也可以看出,当分箱后某个箱中因变量y各类别(二分类时:0和1)的比例相等时,那么其熵值达到最大,相反,当某个箱中因变量为单个类别值时,那么该箱的熵值达到最小的0(纯度最纯)。
从结果上看,最大信息增益对应分箱后的总熵值最小,即最大信息增益划分和最小熵分箱的含义是一致的.
关于信息熵和信息增益,下面给出一个实现参考:
class entropy: '''计算离散随机变量的熵 x,y:pd.Series 类型 ''' @staticmethod def entropy(x): '''信息熵''' p = x.value_counts(normalize=True) p = p[p > 0] e = -(p * np.log2(p)).sum() return e @staticmethod def cond_entropy(x, y): '''条件熵''' p = y.value_counts(normalize=True) e = 0 for yi in y.unique(): e += p[yi] * entropy.entropy(x[y == yi]) return e @staticmethod def info_gain(x, y): '''信息增益''' g = entropy.entropy(x) - entropy.cond_entropy(x, y) return g
使用上面的数据计算:
y= pd.Series([0,1,0,1,1]) entropy.entropy(y) # 输出 0.97095 x = pd.Series([1,2,3,4,5]) entropy.info_gain(y, (x 4).astype(int)) #输出 0.41997
基于Sklearn决策树离散化
经典的决策树算法中,信息熵是特征选择和划分的背后实现:
from sklearn.tree import DecisionTreeClassifier # max_depth=3,表示进行3次划分构造3层的树结构 def dt_entropy_cut(x, y, max_depth=3, criterion='entropy'): # gini dt = DecisionTreeClassifier(criterion=criterion, max_depth=max_depth) dt.fit(x.values.reshape(-1, 1), y) qts = dt.tree_.threshold[np.where(dt.tree_.children_left > -1)] if qts.shape[0] == 0: qts = np.array([np.median(data[:, feature])]) else: qts = np.sort(qts) return qts
使用该方法对数据划分示例如下,cutoff中的点即是Sklearn的决策树基于信息熵的分隔点。
cutoff = dt_entropy_cut(df['mean radius'],df['target'] ) cutoff = cutoff.tolist() [np.round(x,3) for x in cutoff] # 输出 [10.945, 13.095, 13.705, 15.045, 17.8, 17.88]
最小熵离散化
DecisionTreeClassifier的初衷并不是数据的离散化。我们并不能自由控制分箱的过程,比如倒数第2箱的数据很少,但无法干预。
下文给出了一个自定义的基于信息熵的数据离散化方法,供读者参考。
1.计算原始信息熵;
2.对于数据中的每个潜在分割点计算以该点划分后各部分的信息熵;
3.计算信息(熵)增益;
4.选择信息增益最大值对应的分割点;
5.递归地对每个分箱后的部分执行2、3、4,直到满足终止条件为止。终止条件一般为:
a.到达指定的分箱数。
b.当信息增益小于某一阈值。
c.其他经验条件。
算法结束后得到一系列的分隔点,这些点作为最终的分箱点(Cutoff),由这些分箱点得到分箱(Bins)。
停止条件直接指定箱数即可,但考虑到算法递归实现,每进行一次递归,分隔点将翻倍,代码设计时使用了递归的轮数,这样实现比较直接。该算法实现参考6.3.2.3。
5 Best-KS分箱原理与实现
介绍Best-KS的资料非常少,笔者暂未找到详细资料,但业内确实有许多应用实践,也许它是实践得出的特征工程方法吧。
KS(Kolmogorov-Smirnov)是模型区分能力的一个常用评价指标,该指标衡量的是好坏样本累计之间的差异。
KS原理:由苏联数学家Kolmogorow和Smirnov联合发明的这一统计方法。Kolmogorov-Smirnov检验(K-S检验)基于累积分布函数,用于检验一个经验分布是否符合某种理论分布或比较两个经验分布是否有显著性差异,属于非参数检验方法,其优点是不假设数据的分布。
该检验的统计量称为KS值,在几何上可直观解释为:累计好、坏样本分布曲线的最大间隔。
在数值上可解释为:累计好、坏样本分布差值绝对值的最大值。
KS与K统计量无关。
K统计量:是由R.A.Fisher于1928引进的一种对称统计量,是累积量的无偏估计量。
常见3种KS:
K-S test(K-S检验)
模型KS(KS统计量)
特征KS(KS统计量)
其背后的原理都是一致的,其中第2点和第3点实际在做的事情是:比较预测y和真实y分布是否一致或计算差距的度量。
KS为好坏样本累计分布差异的最大值,其计算逻辑描述如下:
1.计算每个区间或值对应的好坏样本数。
2.计算累计好样本数占总好样本数比率(good%)和累计坏样本数占总坏样本数比率(bad%)。
3.计算两者的差值:累计good%-累计bad%;
4.取绝对值中的最大值记为KS值。
下面给出一个实现参考,CalKS;
当然,KS应用多年,自然有相关的开源实现:
Sklearn中的实现:
import numpy as np from sklearn import metrics
Scipy中的实现:
from scipy.stats import ks_2samp
Best-KS离散化
Best-KS分箱逻辑和基于熵的分箱逻辑基本一致。
Best-KS分箱算法属于二分递归分割的技术,递归将产生一棵二叉树
每次递归时独立计算特征序列的KS,与上一步无关。
特征分箱后特征的KS值必将小于等于原特征KS值。
主要算法逻辑可参考上述基于熵的分箱方法的实现,而算法第3点可以由上述的CalKS实现,得到KS最大值对应的点,考虑相关的实现细节后,最终代码如下:def bestks_cut (df,...) 参考6.3.2.3。
6 卡方分箱原理与实现
卡方分箱算法最早见于Randy Kerber的卡方分箱论文 ,后续关于卡方分箱的内容基本都是基于该版本的优化或改进。
卡方分箱基于卡方检验,而卡方检验的背后则是卡方分布(Chi-Square Distribution或χ2-distribution)。
卡方基础
卡方分布、卡方检验:一般指的是Pearson卡方检验(Pearson's chi-squared test)(由Pearson提出并证明式(6-8)在一定条件下满足卡方分布),属于非参数假设检验的一种。
有两种类型的卡方检验,但其本质都是频数之间差异的度量。其原假设为:观察频数与期望频数无差异或两组变量相互独立不相关。
卡方拟合优度检验(Chi-Square Goodness of Fit Test):用于检验样本是否来自某一个分布,比如检验某样本是否为正态分布
独立性卡方检验(Chi-Square Test for Independence),查看两组类别变量分布是否有差异或相关,以列联表(contingency table,如2×2表格)的形式比较。以列连表形式的卡方检验中,卡方统计量由式(6-8)给出
其中,O表示观察到的频数(即实际的频数),E表示期望的频数。
很明显,越小的卡方值,表明两者相差越小,反之,越大的卡方值表明两者差异越大。
示例如图6-14所示,左侧表示观察到的两组样本分布,右侧演示了期望频数的计算过程。由观察频数和期望频数带入式(6-8)即可求得卡方值。
从计算方式来看,调换行列,卡方值不变,但一般约定是自变量放在列中,因变量放在行中。
科学计算库scipy包含了卡方检验的实现,使用示例如下:
from scipy.stats import chi2_contingency obs = np.array([[25,50],[30,15]]) # 注意,默认有校准 chi2, p, dof, ex = chi2_contingency(obs,correction=False)
该接口输出解释如下:
chi2:表示卡方值,此处值为12.587413;
p:p_value,此处值为0.000388;
dof:表示自由度,此处值为1;
ex:表示期望频率,此处值如图6-14所示。
另外,scipy库中具有计算卡方值的chisquare()函数,但该函数需要手动计算期望值,而chi2_contingency()的易用性更好.
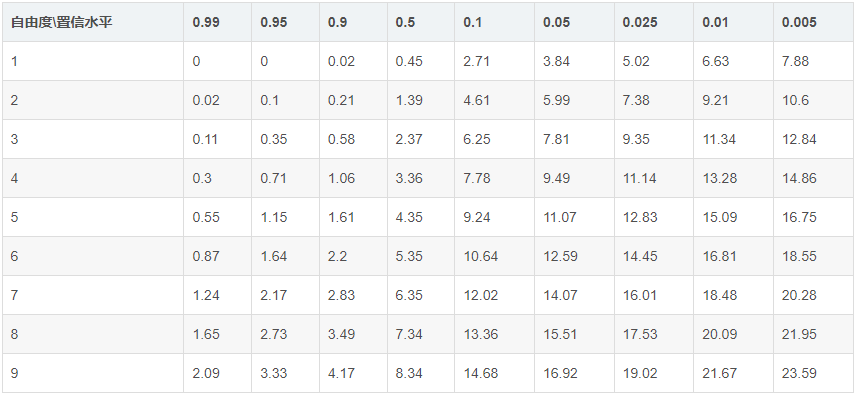
from scipy.stats import chi2 def chi2_table(freedom=10, alpha=None): '''使用示例 1. chi2_table() 2.chi2_table(alpha=[0.1]) ''' if alpha is None: alpha = [0.99, 0.95, 0.90, 0.5, 0.1, 0.05, 0.025, 0.01, 0.005] df = pd.DataFrame([chi2.isf(alpha, df=i) for i in range(1, freedom)]) df.columns = alpha df.index = df.index + 1 return df
执行chi2_table()将得到表6-1。
换个角度描述卡方检验的物理含义:当两个分箱/组中,好坏(正负)分布是一致时,卡方为0,相似时接近0,对应到卡方分箱算法中,应该合并这两箱/组样本。

7 卡方离散化
卡方分箱采用的是自底向上的算法逻辑,算法执行的过程是逐级合并的过程,正是文献41使用的“ChiMerge”——卡方合并的原因。
该过程表示如图6-15所示。图中显示了算法的实现过程:计算相邻组的卡方值,卡方值满足条件的相邻组逐层向上合并。
卡方合并的原则是:组内差异小,组间差异大,也就是说卡方值小的(分布差异小)合并,直到和相邻的分布差异大时停止
算法实现过程分为:
1) 计算卡方值
2) 粗分箱,此处简单通过数值精度和等分12份实现粗分箱来便于演示
3) 生成列联表
4) 计算各相邻箱的卡方值
5) 设定卡方阈值,常使用0.90、0.95、0.99的置信度
6) 设置合并的条件:小于阈值时进行合并
7) 循环直到卡方值不满足阈值条件
其中chi2_merge_core()实现的功能是合并最小卡方值的相邻组(合并到左边组):
def chi2_merge_core(cvs, freq, cutoffs, minidx): '''卡方合并逻辑''' print('最小卡方值索引:',minidx,';分割点:',cutoffs) # minidx后一箱合并到前一组 tmp = freq[minidx] + freq[minidx + 1] freq[minidx] = tmp # 删除minidx后一组 freq = np.delete(freq, minidx + 1, 0) # 删除对应的分隔点 cutoffs = np.delete(cutoffs, minidx + 1, 0) cvs = np.delete(cvs, minidx, 0) # 更新前后两个组的卡方值,其他部分卡方值未变化 if minidx <= (len(cvs) - 1): cvs[minidx] = chi2_value(freq[minidx:minidx + 2]) if minidx - 1 >= 0: cvs[minidx - 1] = chi2_value(freq[minidx - 1:minidx + 1]) return cvs, freq, cutoffs
该循环输出如下: 最小卡方值索引: 0 ;分割点: [ 7. 9. 10. 12. 14. 16. 18. 19. 21. 23. 24. 26. 28.] 最小卡方值索引: 5 ;分割点: [ 7. 10. 12. 14. 16. 18. 19. 21. 23. 24. 26. 28.] 最小卡方值索引: 5 ;分割点: [ 7. 10. 12. 14. 16. 18. 21. 23. 24. 26. 28.] 最小卡方值索引: 5 ;分割点: [ 7. 10. 12. 14. 16. 18. 23. 24. 26. 28.] 最小卡方值索引: 5 ;分割点: [ 7. 10. 12. 14. 16. 18. 24. 26. 28.] 最小卡方值索引: 5 ;分割点: [ 7. 10. 12. 14. 16. 18. 26. 28.] 最小卡方值索引: 4 ;分割点: [ 7. 10. 12. 14. 16. 18. 28.]]
本章小结
随着开源算法包集成越来越强大,必然出现更多开箱即用的特征工程方法,部分开源包已经将特征工程作为内置功能的一部分,对用户无感知。
例如CatBoost开源库对类别变量的自动处理。这在简化使用的同时,也带来了副作用:底层的细节越来越不为大众所知了。
本章提供了所有上述特征处理方法的Python代码,这些代码都源于笔者的工程实践,值得读者详细参考学习。
节选自《机器学习:软件工程方法与实现》第6章
本文来自博客园,作者:秋华,转载请注明原文链接:https://www.cnblogs.com/qiu-hua/p/14897646.html

