

Hive实战(2):Hive 函数(4)HiveSQL 高阶函数合集实战(二)集合相关、URL相关、JSON相关、列转行相关
来源:https://mp.weixin.qq.com/s/PLWovsMDxO0wUrDTMaOh4w
集合
collect_set:使用频率 ★★★★★
将分组内的数据放入到一个集合中,具有去重的功能;
1 --统计每个用户具体哪些天访问过 2 select 3 user_id, 4 collect_set(visit_date) over(partition by user_id) as visit_date_set 5 from wedw_tmp.tmp_url_info
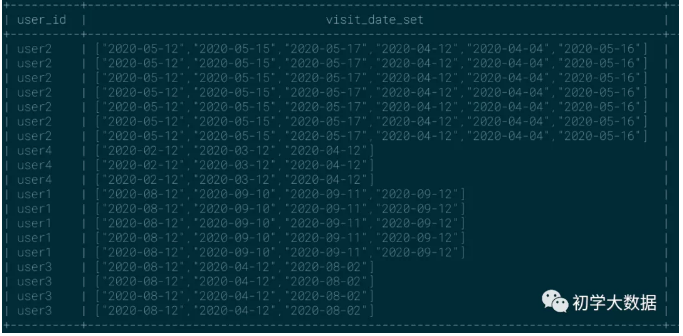
collect_list:使用频率 ★★★★★
和collect_set一样,但是没有去重功能
1 select 2 user_id, 3 collect_set(visit_date) over(partition by user_id) as visit_date_set 4 from wedw_tmp.tmp_url_info 5 6 --如下图可见,user2在2020-05-15号多次访问,这里也算进去了
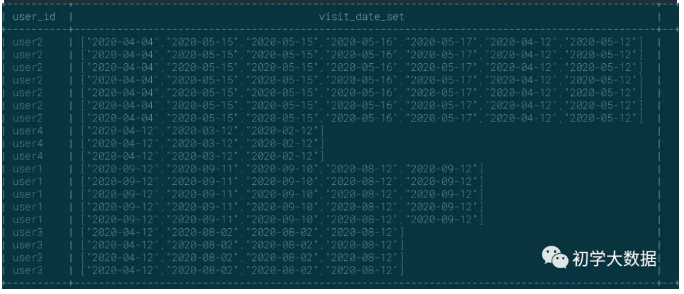
sort_array:使用频率 ★★★
数组内排序;通常结合collect_set或者collect_list使用;
如collect_list为例子,可以发现日期并不是按照顺序组合的,这里有需求需要按照时间升序的方式来组合
1 --按照时间升序来组合 2 select 3 user_id, 4 sort_array(collect_list(visit_date) over(partition by user_id)) as visit_date_set 5 from wedw_tmp.tmp_url_info 6 --结果如下图所示;
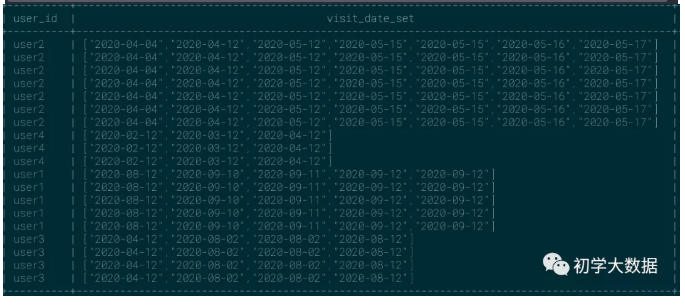
如果突然业务方改需求了,想要按照时间降序来组合,那基于上面的sql该如何变通呢?哈哈哈哈,其实没那么复杂,这里根据没必要按照sort_array来实现,在collect_list中的分组函数内直接按照visit_date降序即可,这里只是为了演示sort_array如何使用
1 --按照时间降序排序 2 select 3 user_id, 4 collect_list(visit_date) over(partition by user_id order by visit_date desc) as visit_date_set 5 from wedw_tmp.tmp_url_info
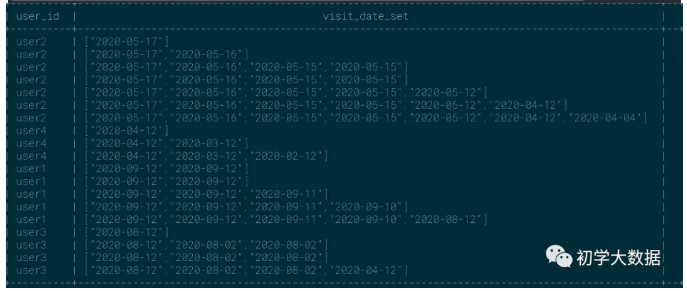
这里还有一个小技巧,对于数值类型统计多列或者数组内的最大值,可以使用sort_array来实现
1 --具体思路就是先把数值变成负数,然后升序排序即可 2 select -sort_array(array(-a,-b,-c))[0] as max_value 3 from ( 4 select 1 as a, 3 as b, 2 as c 5 ) as data 6 7+------------+--+ 8| max_value | 9+------------+--+ 10| 3 | 11+------------+--+
size:
集合中元素的个数
select size(friends) from test3;
map_keys:
返回map中的key
select map_keys(children) from test3;
map_values:
返回map中的value
select map_values(children) from test3;
array_contains:
判断array中是否包含某个元素
select array_contains(friends,'bingbing') from test3;
URL相关
parse_url:使用频率 ★★★★
用于解析url相关的参数,直接上sql
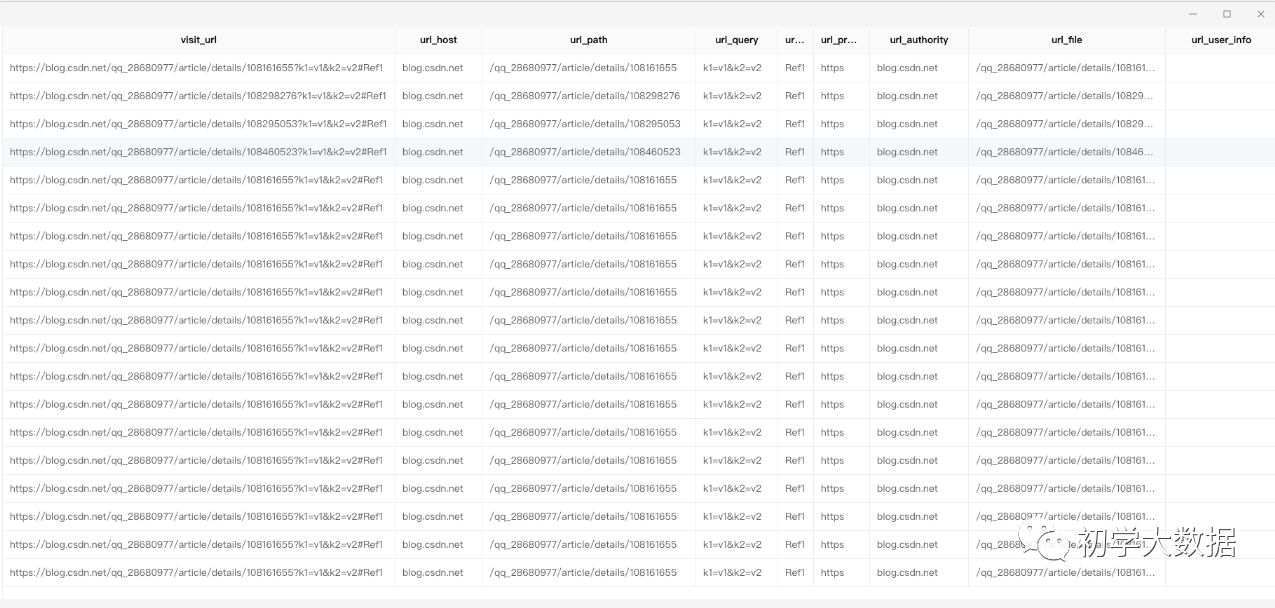
1 select 2 visit_url, 3 parse_url(visit_url, 'HOST') as url_host, --解析host 4 parse_url(visit_url, 'PATH') as url_path, --解析path 5 parse_url(visit_url, 'QUERY') as url_query,--解析请求参数 6 parse_url(visit_url, 'REF') as url_ref, --解析ref 7 parse_url(visit_url, 'PROTOCOL') as url_protocol, --解析协议 8 parse_url(visit_url, 'AUTHORITY') as url_authority,--解析author 9 parse_url(visit_url, 'FILE') as url_file, --解析filepath 10 parse_url(visit_url, 'USERINFO') as url_user_info --解析userinfo 11 from wedw_tmp.tmp_url_info
reflect:使用频率 ★★
该函数是利用java的反射来实现一些功能,目前笔者只用到了关于url编解码
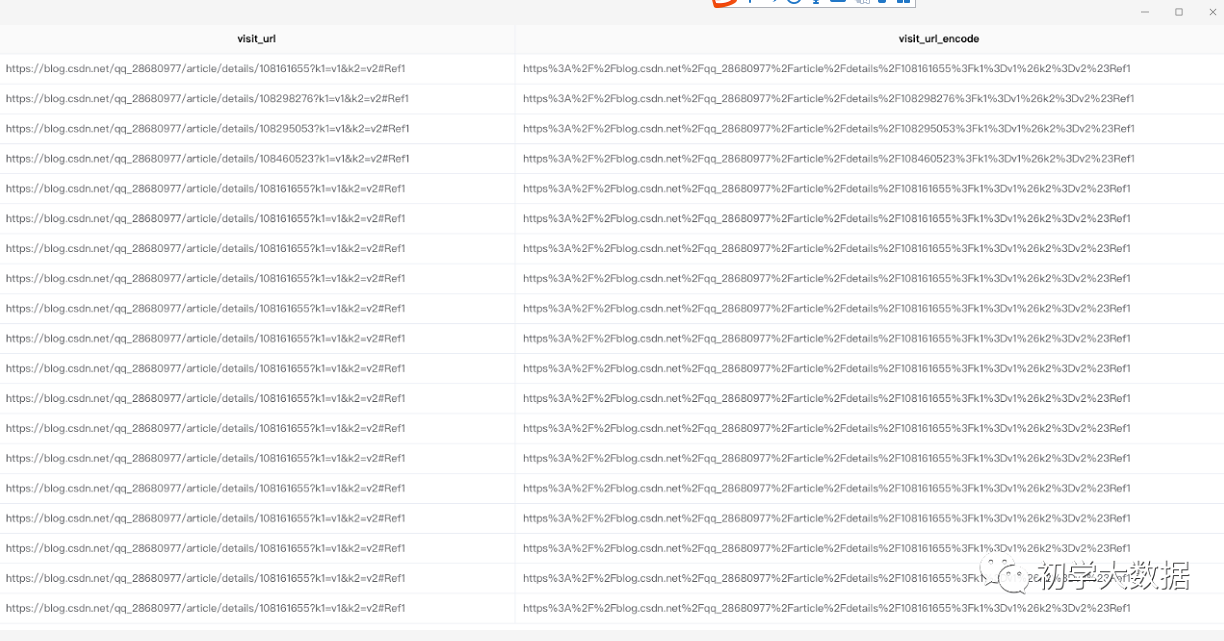
1 --url编码 2 select 3 visit_url, 4 reflect("java.net.URLEncoder", "encode", visit_url, "UTF-8") as visit_url_encode 5 from wedw_tmp.tmp_url_info
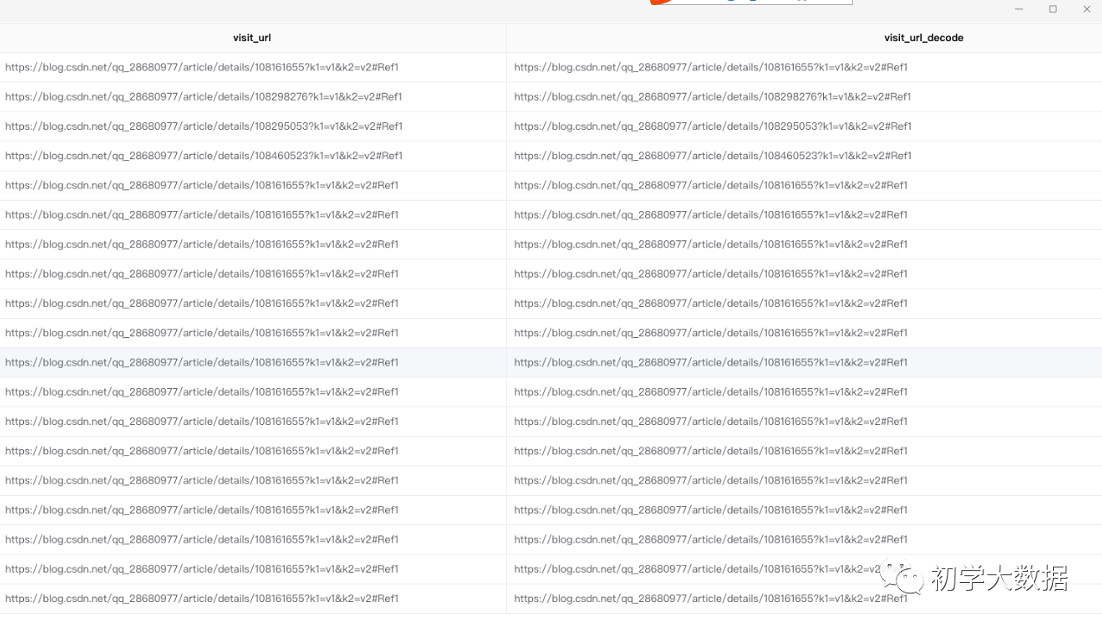
1 --url解码 2 select 3 visit_url, 4 reflect("java.net.URLDecoder", "decode", visit_url_encode, "UTF-8") as visit_url_decode 5 from 6 ( 7 select 8 visit_url, 9 reflect("java.net.URLEncoder", "encode", visit_url, "UTF-8") as visit_url_encode 10 from wedw_tmp.tmp_url_info 11 )t
JSON相关
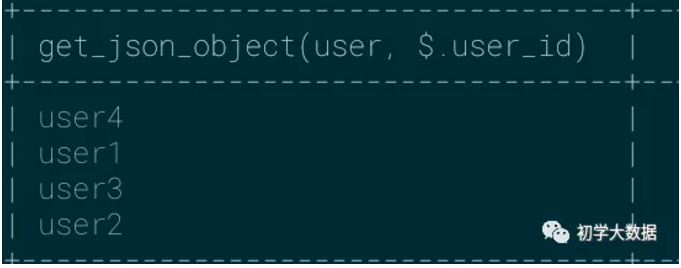
get_json_object:使用频率 ★★★★★
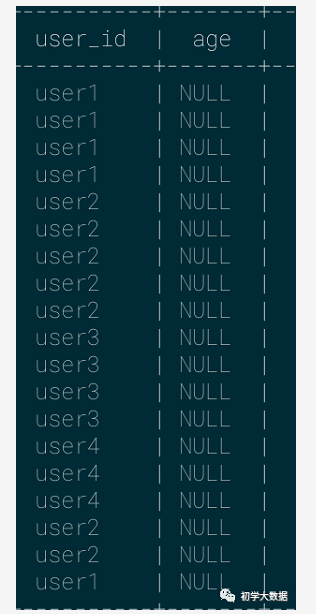
通常用于获取json字符串中的key,如果不存在则返回null
1 select 2 get_json_object(json_data,'$.user_id') as user_id, 3 get_json_object(json_data,'$.age') as age --不存在age,则返回null 4 from 5 ( 6 select 7 concat('{"user_id":"',user_id,'"}') as json_data 8 from wedw_tmp.tmp_url_info 9 )t
列转行相关
explode:使用频率 ★★★★★
列转行,通常是将一个数组内的元素打开,拆成多行
1 --简单例子 2 select explode(array(1,2,3,4,5)) 3+------+--+ 4| col | 5+------+--+ 6| 1 | 7| 2 | 8| 3 | 9| 4 | 10| 5 | 11+------+- 12 --结合lateral view 使用 13 select 14 get_json_object(user,'$.user_id') 15 from 16( 17 select 18 distinct collect_set(concat('{"user_id":"',user_id,'"}')) over(partition by year(visit_date)) as user_list 19 from wedw_tmp.tmp_url_info 20 )t 21 lateral view explode(user_list) user_list as user
本文来自博客园,作者:秋华,转载请注明原文链接:https://www.cnblogs.com/qiu-hua/p/14224395.html
