
HBASE实战(1):亿级数据从 MySQL 到 Hbase 的三种同步方案与实践(一)环境搭建
原文:https://blog.csdn.net/rlnlo2pnefx9c/article/details/108288956
1.导语
大家好,我是光城,下面是我之前在gitchat上发布的一个资料,今天全部开源!源码全部存放在本人github仓库,地址:https://github.com/Light-City/dbSyncScheme,欢迎大家提issue与star!接下来进入本节chat内容!PPT点击阅读原文可直达。
本节亿级数据从 MySQL 到 Hbase 的三种同步方案与实践将主要围绕下面架构图中的三种方法进行实践与讲解。
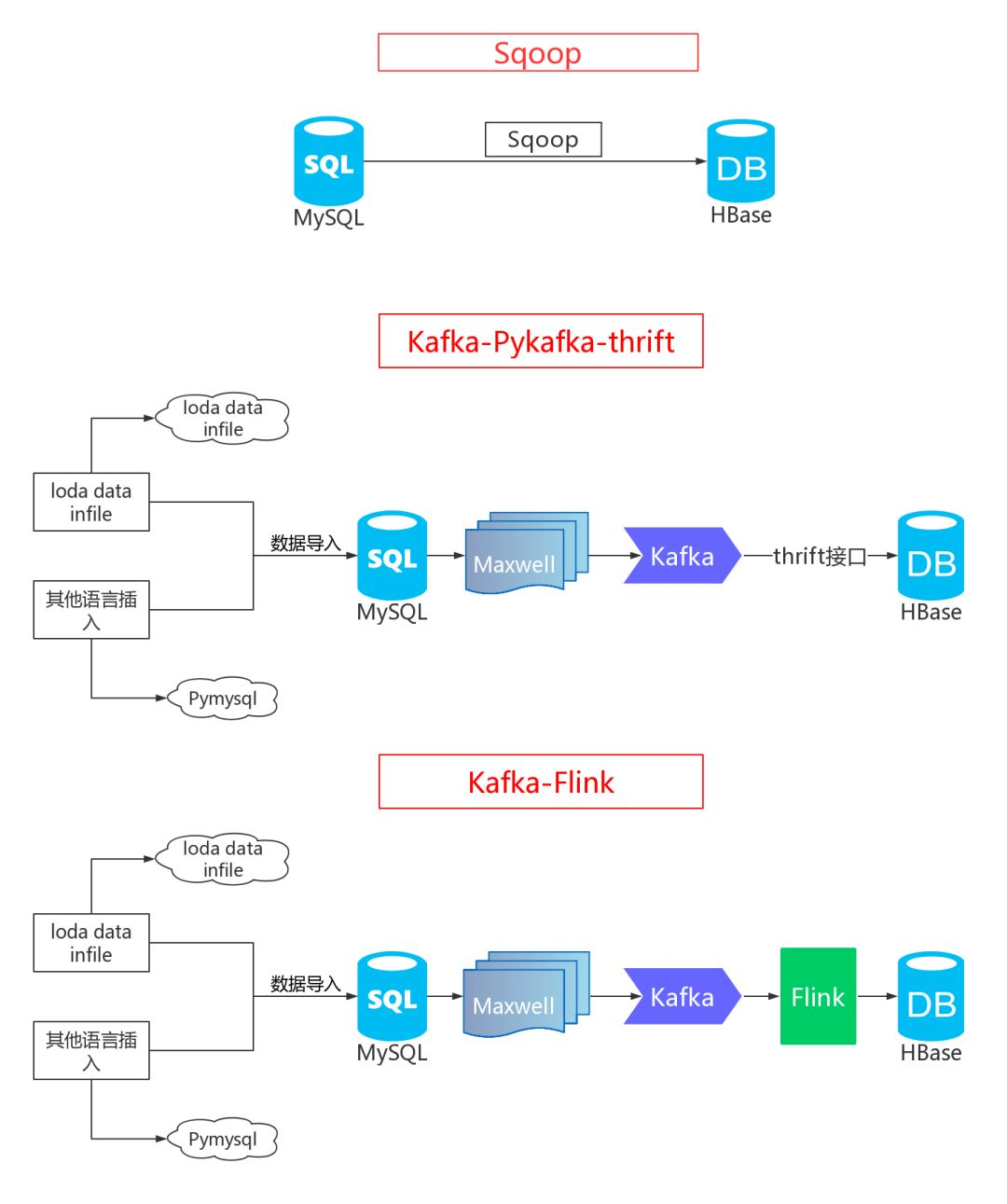
2.工欲善其事,必先利其器
2.1 环境需知
我的实验环境为:Ubuntu16.04+hadoop伪分布式(所以重点会介绍伪分布式环境部署),本节实验可以适用于大部分Linux。
实验的环境有:
-
MySQL
-
Hadoop伪分布式/完全分布式
-
HBase
-
Phoenix
-
Zookeeper
-
Kafka
-
Maxwell
-
Flink
所以,本节内容先从以上环境部署讲起,再来逐步分析亿级数据从 MySQL 到 Hbase 的三种同步方案与实践。
注意:本节不会非常深入的去讲解HBase、Phoenix、Kafka、Maxwell、Flink等内容,因为涉及的面非常多,光一个就可以讲很多天了,所以本节将具体的某一块与我们的场景相结合进行阐述,谈谈他们的具体应用与使用,相信大家看完后,对这些会有更加深入的理解!
2.2 伪分布式环境部署
2.2.1.准备工作
【JAVA】
Hadoop环境需要JAVA环境,所以首先得安装Java,而Ubuntu默认Java为OpenJdk,需要先卸载,再安装Oracle。除此之外,也可以不用卸载OpenJDK,将Oracle JAVA设为默认的即可。
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
关于java配置只要输入java或者javac看到输出,配置成功。
【用户】
在Ubuntu或者类Unix系统中,用户可以通过下列命令添加创建用户:
sudo useradd -s /bin/bash -g hadoop -d /home/hadoop -m hadoop
如果提示hadoop不再sudoers文件中,执行下列命令:
vi /etc/sudoers编辑上述文件:
# User privilege specification root ALL=(ALL:ALL) ALL hadoop ALL=(ALL:ALL) ALL # 添加此行
再执行上述命令:
light@city:~$ sudo useradd -s /bin/bash -g hadoop -d /home/hadoop -m hadoop
useradd:“hadoop”组不存在
添加用户组:
light@city:/home$ sudo groupadd hadoop
再次执行即可:
light@city:~$ sudo useradd -s /bin/bash -g hadoop -d /home/hadoop -m hadoop
设置或修改密码:
sudo passwd hadoop
【SSH】
安装ssh
sudo apt-get install openssh-server
配置免密登陆
su - hadoop ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
然后输入
ssh localhost
此时不需要输入密码,说明成功!
注意:关于ssh免秘登陆失败问题,大家可以通过以下方法进行尝试,大部分问题在于目录及文件权限!
sudo chmod 755 $HOME sudo chmod 600 id_rsa sudo chmod 600 id_rsa.pub sudo chmod 644 authorized_keys
2.2.2 伪分布式
【Hadoop】
-
下载及安装
在下列镜像中下载Hadoop版本,我下载的3.0.2。
https://mirrors.cnnic.cn/apache/hadoop/common/
wget https://mirrors.cnnic.cn/apache/hadoop/common/hadoop-3.0.2/hadoop-3.0.2.tar.gz tar zxvf hadoop-3.0.2.tar.gz sudo mv hadoop-3.0.2 /usr/local/hadoop
-
配置
编辑etc/hadoop/core-site.xml,configuration配置为
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
注意:一定要看本机的9000端口是否被占用,如果被占用了,后面就启动不出来NameNode!
关于查看本机的9000端口是否被占用:
sudo netstat -alnp | grep 9000

会发现9000端口被php-fpm给占用了,所以这里得修改为其他端口,比如我修改为9012,然后可以再次执行这个命令,会发现没被占用,说明可行!
编辑etc/hadoop/hdfs-site.xml,configuration配置为
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
-
初始化
格式化HDFS
bin/hdfs namenode -format
注意:格式化执行一次即可!
启动NameNode和DataNode
sbin/start-dfs.sh
这时在浏览器中访问http://localhost:9870/,可以看到NameNode相关信息。
http://localhost:9864/查看DataNode相关信息。
由于hadoop3.x版本与2.x版本监听端口不一样,所以如果还是原先的50070便访问不到相关信息,不知道上述9870或者9864,没关系,可以通过下面命令查看!
输入netstat命令即可查看tcp监听端口:
sudo netstat -ntlp
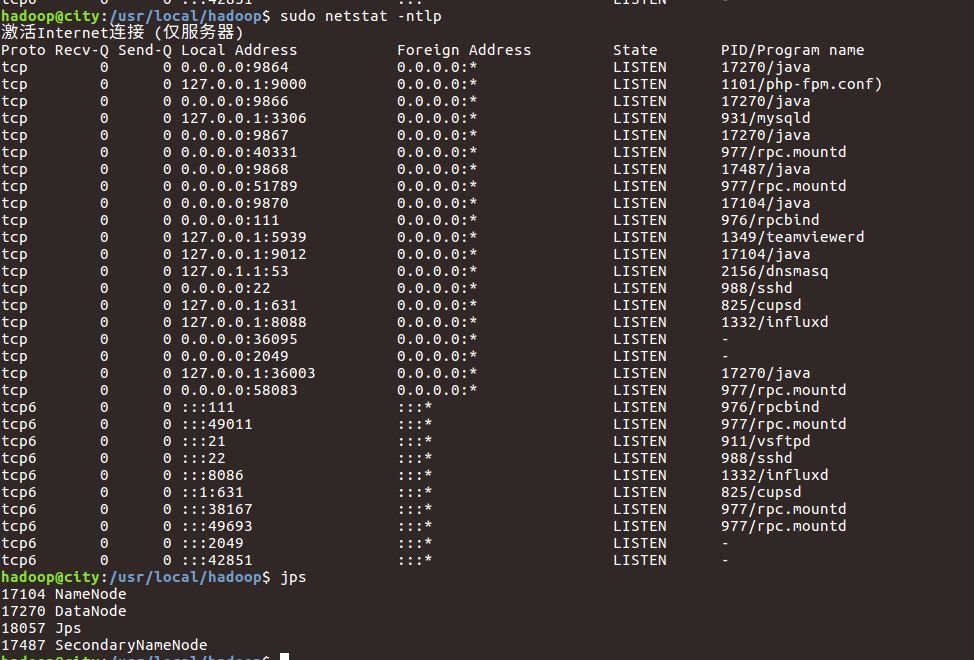
jps_ntlp
上述两个重要端口,9864后面可以看到进程ID为17270,通过JPS查看可以看到对应DataNode,9870类似方法。

hadoop
-
配置YARN
编辑etc/hadoop/mapred-site.xml,configuration配置为
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
编辑etc/hadoop/yarn-site.xml,configuration配置为
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动YARN
sbin/start-yarn.sh
查看进程:
Jps
NodeManager
SecondaryNameNode
NameNode
ResourceManager
DataNode
YARN就是上述的资源管理:ResourceManager。
同理,可以通过上述方法查看ResourceManager的端口,默认为8088。
浏览器输入:http://localhost:8088/cluster
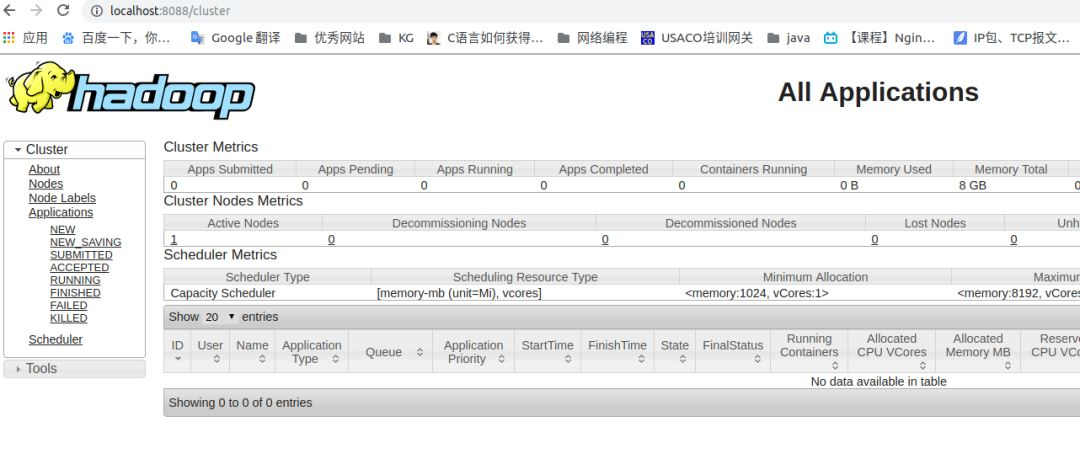
hadoop
-
启动与停止
启动:
sbin/start-dfs.sh
sbin/start-yarn.sh
停止:
sbin/stop-dfs.sh
sbin/stop-yarn.sh
至此,伪分布式搭建完毕!后面开始HBase与Phoenix搭建!
【HBase】
-
下载安装
https://mirrors.cnnic.cn/apache/hbase/
wget https://mirrors.cnnic.cn/apache/hbase/stable/hbase-1.4.9-bin.tar.gz tar zxvf hbase-1.4.9-bin.tar.gz sudo mv zxvf hbase-1.4.9-bin /usr/local/hbase
-
单机HBase配置
编辑conf/hbase-site.xml,configuration配置为
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9012/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper</value>
</property>
</configuration
启动
bin/start-hbase.sh
jps查看进程:
HMaster
Jps
终端
bin/hbase shell
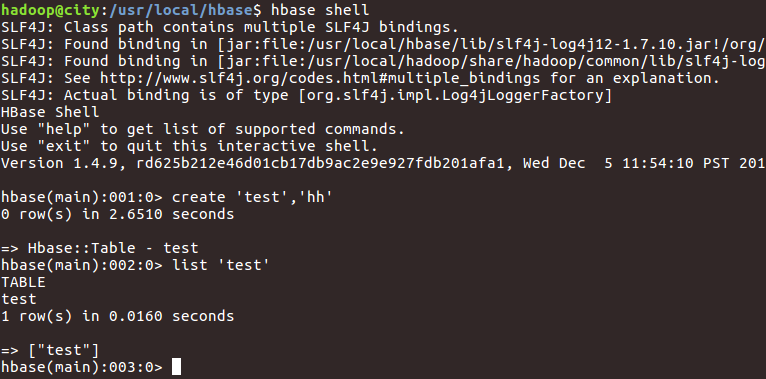
hbaseshell
如果想要关闭HBase,则输入:
bin/stop-hbase.sh
-
HBase伪分布式配置
编辑conf/hbase-site.xml,configuration中添加
<property> <name>hbase.cluster.distributed</name> <value>true</value> </property>
然后修改root由本地文件系统到HDFS,编辑conf/hbase-site.xml,hbase.rootdir值由
file:///home/hadoop/hbase
修改为
-
hdfs://localhost:9012/hbase
-
★注意后面的端口号9012,需要保证与Hadoop DFS配置中的fs.defaultFS相同!
”
这样子修改后,会在hdfs文件系统中看到HBase目录,当然你也可以不用配置此项!
上述配置完毕后,保存后,重启HBase即可!
【封装】
每次启动这些输入太多命令,太繁琐,直接一个bash脚本搞定,首先进入/usr/local,然后再运行这个脚本!
启动脚本:
#!/bin/bash hadoop/sbin/start-dfs.shkuangjia hadoop/sbin/start-yarn.sh hbase/bin/start-hbase.sh
停止脚本:
#!/bin/bash hadoop/sbin/stop-dfs.sh hadoop/sbin/stop-yarn.sh hbase/bin/stop-hbase.sh
【zookeeper】
由于Hbase自带了zookeeper,一开始使用自带的,后来发现出了很多问题,换成自己配置zookeeper,配置方法如下:
最近做的数据迁移,当上游数据流向下游过大的时候,HBase就会崩溃。HBase自带的Zookeeper出了问题,就尝试自己安装独立的Zookeeper。
(1)禁用HBase自带的Zookeeper
修改 ./conf/hbase-env.sh
export HBASE_MANAGES_ZK=false(如果值为true,则使用自带的Zookeeper,会随着HBase一起启动)
(2)安装及配置独立Zookeeper
Zookeeper最新的版本可以通过官网获取
wget http://apache.fayea.com/zookeeper/zookeeper-xxx/zookeeper-xxx.tar.gz tar xfz zookeeper-xxx.tar.gz mv zookeeper-xxx /usr/local/zookeeper
★
拷贝配置文件
”
cd zookeeper-xxx/conf/
cp zoo_sample.cfg zoo.cfg
★
修改配置项
”
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/logs
dataDir:Zookeeper保存节点数据的目录。dataLogDir:Zookeeper保存节点数据的日志。
如果没有这个目录,就创建一下。
(3)HBase配置
★拷贝 zoo.cfg 到 hbase/conf/ 目录下
”
-
cp zoo.cfg /usr/local/hbase/conf/
-
这是官方文档推荐的做法,如果不拷贝 zoo.cfg,在 hbase-site.xml 中也可以对Zookeeper进行相关配置,但HBase会优先使用 zoo.cfg(如果有的话)的配置
★修改 hbase-site.xml
”
在原文件上加入:
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
如果不加的话,在启动独立安装的Zookeeper后,HBase不能正常启动。
(4)启动Zookeeper
./bin/zkServer.sh start
(5)检查服务是否启动
-
ps -ef | grep zookeeper
-
(6)启动HBase
在成功启动Zookeeper后,就可以启动HBase了:
-
./bin/start-hbase.sh
-
【Phoenix】
版本要与HBase相匹配!
下载apache-phoenix-4.14.2-HBase-1.4-bin.tar.gz
★
安装
”
-
tar -xvf apache-phoenix-4.14.2-HBase-1.4-bin.tar.gz
-
mv apache-phoenix-4.14.2-HBase-1.4-bin.tar.gz /usr/local/phoenix
-
-
★配置
”
将hbase-site.xml配置文件拷贝到phoenix的bin目录下
★启动
”
首先启动zookeeper与hbase。
hadoop@city: ./start_zk.sh ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED hadoop@city: ./start_hbase.sh running master, logging to /usr/local/hbase/logs/hbase-hadoop-master-city.out : running regionserver, logging to /usr/local/hbase/logs/hbase-hadoop-regionserver-city.out
启动phoenix:
sqlline.py localhost

install_phoenix
【Kafka】
★什么是Kafka?
”
Kafka 是一种分布式的,基于发布 / 订阅的消息系统。在这里可以把Kafka理解为生产消费者模式。
Kafka是使用Java开发的应用程序,Kafka需要运行Zookeeper,两者都需要Java,所以在需要安装Zookeeper和Kafka之前,先安装Java环境。
★启动Zookeeper
”
直接输入zkServer.sh start即可!
zookeeper_start
★Kafka安装及配置
”
Kafka下载地址:
★http://kafka.apache.org/downloads
”
同上述安装,这里下载.tgz文件,也是解压后移动到/usr/local即可!
关于配置文件可以直接采用默认的即可。
★启动Kafka
”
-
./bin/kafka-server-start.sh ./config/server.properties
enter image description here
★Topic创建
”
当使用下面maxwell提取出来的binlog信息的时候,默认使用kafka进行消费。
-
./kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
-
★发布与订阅
”
向Topic上发布消息,按Ctrl+D结束:
-
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
-

enter image description here
从Topic上接收消息,按Ctrl+C结束:
-
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
-
recv_mesg
【Maxwell】
★Maxwell是什么?
”
官网原语:Maxwell's daemon, a mysql-to-json kafka producer。
这里解释一下Maxwell是将mysql binlog中的insert、update等操作提取出来,并以json数据返回作为kafka生产者。
当然自己也可以用编程实现binlog数据提取,并返回一个json数据。
★下载地址:http://maxwells-daemon.io/
”
安装方式同上。
★mysql配置Maxwell
”
Maxwell配置文件中默认用户名密码均为maxwell,所以需要在mysql中做相应的授权。
mysql> GRANT ALL on maxwell.* to'maxwell'@'%' identified by 'maxwell'; mysql> GRANT SELECT, REPLICATION CLIENT,REPLICATION SLAVE on *.* to 'maxwell'@'%'; mysql> flush privileges;
★配置Maxwell
”
-
cp config.properties.example config.properties
-
vi config.properties
-
maxwell配置:
log_level=info # 默认生产者 producer=kafka kafka.bootstrap.servers=localhost:9092 # mysql login info host=localhost user=maxwell password=maxwell # kafka配置 kafka_topic=test kafka.compression.type=snappy kafka.acks=all kinesis_stream=test
★启动maxwell
”
-
./maxwell/bin/maxwell --user='maxwell' --password='maxwell' --host='127.0.0.1' --producer=kafka --kafka.bootstrap.servers=localhost:9092 --kafka_topic=test
-
当然也可以把上述封装成一个启动脚本:
-
#!/bin/bash
-
./maxwell/bin/maxwell --user='maxwell' --password='maxwell' --host='127.0.0.1' --producer=kafka --kafka.bootstrap.servers=localhost:9092 --kafka_topic=test
-
直接启动:
-
./start_maxwell.sh
-
maxwell
【Flink】
★什么是Flink?
”
干说Flink比较抽象,直接举个例子吧,就拿本节的同步来说,本节使用的Flink就是做实时流计算的一个场景ETL,数据仓库的实时同步,当上游下发数据到Kafka队列中,然后通过Flink程序做window的收集,并将数据sink到Hbase中。
★下载:https://flink.apache.org/
”
安装的时候,直接进行解压缩并配置path环境即可!
★解压缩
”
-
tar -zxf xxx.tgz
-
mv xxx /usr/local
-
★配置环境变量
”
-
vim ~/.bashrc
-
export FLNK_HOME=/usr/local/flink
-
export PATH=$FLINK_HOME/bin:$PATH
-
使上述生效:
-
source ~/.bashrc
-
★启动与关闭flink
”
-
cd flink/bin
-
./start-cluster.sh # 启动
-
stop-cluster.sh # 关闭
本文来自博客园,作者:秋华,转载请注明原文链接:https://www.cnblogs.com/qiu-hua/p/14128348.html

