


Flink实战(102):配置(一)管理配置
来源:http://www.54tianzhisheng.cn/2019/03/28/flink-additional-data/
前言
如果你了解 Apache Flink 的话,那么你应该熟悉该如何向 Flink 发送数据或者如何从 Flink 获取数据。但是在某些情况下,我们需要将配置数据发送到 Flink 集群并从中接收一些额外的数据。
在本文的第一部分中,我将描述如何将配置数据发送到 Flink 集群。我们需要配置很多东西:方法参数、配置文件、机器学习模型。Flink 提供了几种不同的方法,我们将介绍如何使用它们以及何时使用它们。在本文的第二部分中,我将描述如何从 Flink 集群中获取数据。
一 如何发送数据给 TaskManager?
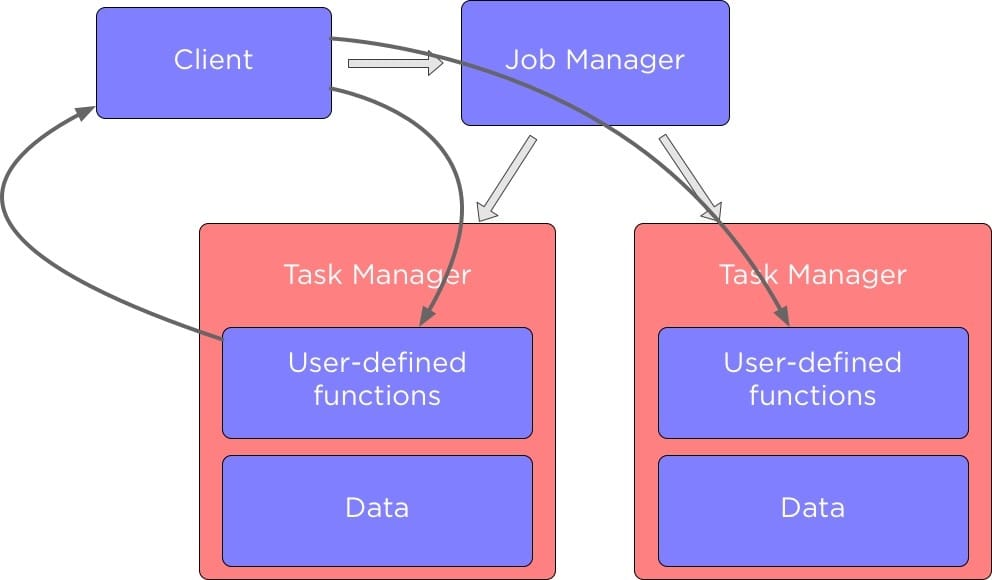
在我们深入研究如何在 Apache Flink 中的不同组件之间发送数据之前,让我们先谈谈 Flink 集群中的组件,下图展示了 Flink 中的主要组件以及它们是如何相互作用的:

当我们运行 Flink 应用程序时,它会与 Flink JobManager 进行交互,这个 Flink JobManager 存储了那些正在运行的 Job 的详细信息,例如执行图。
JobManager 它控制着 TaskManager,每个 TaskManager 中包含了一部分数据来执行我们定义的数据处理方法。
在许多的情况下,我们希望能够去配置 Flink Job 中某些运行的函数参数。根据用例,我们可能需要设置单个变量或者提交具有静态配置的文件,我们下面将讨论在 Flink 中该如何实现?
除了向 TaskManager 发送配置数据外,有时我们可能还希望从 Flink Job 的函数方法中返回数据。
如何配置用户自定义函数?
假设我们有一个从 CSV 文件中读取电影列表的应用程序(它要过滤特定类型的所有电影):
//读取电影列表数据集合 DataSet<Tuple3<Long, String, String>> lines = env.readCsvFile("movies.csv") .ignoreFirstLine() .parseQuotedStrings('"') .ignoreInvalidLines() .types(Long.class, String.class, String.class); lines.filter((FilterFunction<Tuple3<Long, String, String>>) movie -> { // 以“|”符号分隔电影类型 String[] genres = movie.f2.split("\\|"); // 查找所有 “动作” 类型的电影 return Stream.of(genres).anyMatch(g -> g.equals("Action")); }).print();
我们很可能想要提取不同类型的电影,为此我们需要能够配置我们的过滤功能。 当你要实现这样的函数时,最直接的配置方法是实现构造函数:
// 传递类型名称 lines.filter(new FilterGenre("Action")) .print(); ... class FilterGenre implements FilterFunction<Tuple3<Long, String, String>> { //类型 String genre; //初始化构造方法 public FilterGenre(String genre) { this.genre = genre; } @Override public boolean filter(Tuple3<Long, String, String> movie) throws Exception { String[] genres = movie.f2.split("\\|"); return Stream.of(genres).anyMatch(g -> g.equals(genre)); } }
或者,如果你使用 lambda 函数,你可以简单地使用它的闭包中的一个变量:
final String genre = "Action"; lines.filter((FilterFunction<Tuple3<Long, String, String>>) movie -> { String[] genres = movie.f2.split("\\|"); //使用变量 return Stream.of(genres).anyMatch(g -> g.equals(genre)); }).print();
Flink 将序列化此变量并将其与函数一起发送到集群。
如果你需要将大量变量传递给函数,那么这些方法就会变得非常烦人了。 为了解决这个问题,Flink 提供了 withParameters 方法。 要使用它,你需要实现那些 Rich 函数,比如你不必实现 MapFunction 接口,而是实现 RichMapFunction。
Rich 函数允许你使用 withParameters 方法传递许多参数:
// Configuration 类来存储参数 Configuration configuration = new Configuration(); configuration.setString("genre", "Action"); lines.filter(new FilterGenreWithParameters()) // 将参数传递给函数 .withParameters(configuration) .print();
要读取这些参数,我们需要实现 “open” 方法并读取其中的参数:
class FilterGenreWithParameters extends RichFilterFunction<Tuple3<Long, String, String>> { String genre; @Override public void open(Configuration parameters) throws Exception { //读取配置 genre = parameters.getString("genre", ""); } @Override public boolean filter(Tuple3<Long, String, String> movie) throws Exception { String[] genres = movie.f2.split("\\|"); return Stream.of(genres).anyMatch(g -> g.equals(genre)); } }
所有这些选项都可以使用,但如果需要为多个函数设置相同的参数,则可能会很繁琐。在 Flink 中要处理此种情况, 你可以设置所有 TaskManager 都可以访问的全局环境变量。
为此,首先需要使用 ParameterTool.fromArgs 从命令行读取参数:
public static void main(String... args) { //读取命令行参数 ParameterTool parameterTool = ParameterTool.fromArgs(args); ... }
然后使用 setGlobalJobParameters 设置全局作业参数:
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); env.getConfig().setGlobalJobParameters(parameterTool); ... //该函数将能够读取这些全局参数 lines.filter(new FilterGenreWithGlobalEnv()) //这个函数是自己定义的 .print();
现在我们来看看这个读取这些参数的函数,和上面说的一样,它是一个 Rich 函数:
class FilterGenreWithGlobalEnv extends RichFilterFunction<Tuple3<Long, String, String>> { @Override public boolean filter(Tuple3<Long, String, String> movie) throws Exception { String[] genres = movie.f2.split("\\|"); //获取全局的配置 ParameterTool parameterTool = (ParameterTool) getRuntimeContext().getExecutionConfig().getGlobalJobParameters(); //读取配置 String genre = parameterTool.get("genre"); return Stream.of(genres).anyMatch(g -> g.equals(genre)); } }
要读取配置,我们需要调用 getGlobalJobParameter 来获取所有全局参数,然后使用 get 方法获取我们要的参数。
广播变量
如果你想将数据从客户端发送到 TaskManager,上面文章中讨论的方法都适合你,但如果数据以数据集的形式存在于 TaskManager 中,该怎么办? 在这种情况下,最好使用 Flink 中的另一个功能 —— 广播变量。 它只允许将数据集发送给那些执行你 Job 里面函数的任务管理器。
假设我们有一个数据集,其中包含我们在进行文本处理时应忽略的单词,并且我们希望将其设置为我们的函数。 要为单个函数设置广播变量,我们需要使用 withBroadcastSet 方法和数据集。
DataSet<Integer> toBroadcast = env.fromElements(1, 2, 3); // 获取要忽略的单词集合 DataSet<String> wordsToIgnore = ... data.map(new RichFlatMapFunction<String, String>() { // 存储要忽略的单词集合. 这将存储在 TaskManager 的内存中 Collection<String> wordsToIgnore; @Override public void open(Configuration parameters) throws Exception { //读取要忽略的单词的集合 wordsToIgnore = getRuntimeContext().getBroadcastVariable("wordsToIgnore"); } @Override public String map(String line, Collector<String> out) throws Exception { String[] words = line.split("\\W+"); for (String word : words) //使用要忽略的单词集合 if (wordsToIgnore.contains(word)) out.collect(new Tuple2<>(word, 1)); } //通过广播变量传递数据集 }).withBroadcastSet(wordsToIgnore, "wordsToIgnore");
你应该记住,如果要使用广播变量,那么数据集将会存储在 TaskManager 的内存中,如果数据集和越大,那么占用的内存就会越大,因此使用广播变量适用于较小的数据集。
如果要向每个 TaskManager 发送更多数据并且不希望将这些数据存储在内存中,可以使用 Flink 的分布式缓存向 TaskManager 发送静态文件。 要使用 Flink 的分布式缓存,你首先需要将文件存储在一个分布式文件系统(如 HDFS)中,然后在缓存中注册该文件:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); //从 HDFS 注册文件 env.registerCachedFile("hdfs:///path/to/file", "machineLearningModel") ... env.execute()
为了访问分布式缓存,我们需要实现一个 Rich 函数:
class MyClassifier extends RichMapFunction<String, Integer> { @Override public void open(Configuration config) { File machineLearningModel = getRuntimeContext().getDistributedCache().getFile("machineLearningModel"); ... } @Override public Integer map(String value) throws Exception { ... } }
请注意,要访问分布式缓存中的文件,我们需要使用我们用于注册文件的 key,比如上面代码中的 machineLearningModel。
二、如何从 TaskManager 中返回数据
Accumulator(累加器)
我们前面已经介绍了如何将数据发送给 TaskManager,但现在我们将讨论如何从 TaskManager 中返回数据。 你可能想知道为什么我们需要做这种事情。 毕竟,Apache Flink 就是建立数据处理流水线,读取输入数据,处理数据并返回结果。
为了表达清楚,让我们来看一个例子。假设我们需要计算每个单词在文本中出现的次数,同时我们要计算文本中有多少行:
//要处理的数据集合 DataSet<String> lines = ... // Word count 算法 lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception { String[] words = line.split("\\W+"); for (String word : words) { out.collect(new Tuple2<>(word, 1)); } } }) .groupBy(0) .sum(1) .print(); // 计算要处理的文本中的行数 int linesCount = lines.count() System.out.println(linesCount);
问题是如果我们运行这个应用程序,它将运行两个 Flink 作业!首先得到单词统计数,然后计算行数。
这绝对是低效的,但我们怎样才能避免这种情况呢?一种方法是使用累加器。它们允许你从 TaskManager 发送数据,并使用预定义的功能聚合此数据。 Flink 有以下内置累加器:
-
IntCounter,LongCounter,DoubleCounter:允许将 TaskManager 发送的 int,long,double 值汇总在一起
-
AverageAccumulator:计算双精度值的平均值
-
LongMaximum,LongMinimum,IntMaximum,IntMinimum,DoubleMaximum,DoubleMinimum:累加器,用于确定不同类型的最大值和最小值
-
直方图 - 用于计算 TaskManager 的值分布
要使用累加器,我们需要创建并注册一个用户定义的函数,然后在客户端上读取结果。下面我们来看看该如何使用呢:
lines.flatMap(new RichFlatMapFunction<String, Tuple2<String, Integer>>() { //创建一个累加器 private IntCounter linesNum = new IntCounter(); @Override public void open(Configuration parameters) throws Exception { //注册一个累加器 getRuntimeContext().addAccumulator("linesNum", linesNum); } @Override public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception { String[] words = line.split("\\W+"); for (String word : words) { out.collect(new Tuple2<>(word, 1)); } // 处理每一行数据后 linesNum 递增 linesNum.add(1); } }) .groupBy(0) .sum(1) .print(); //获取累加器结果 int linesNum = env.getLastJobExecutionResult().getAccumulatorResult("linesNum"); System.out.println(linesNum);
这样计算就可以统计输入文本中每个单词出现的次数以及它有多少行。
如果需要自定义累加器,还可以使用 Accumulator 或 SimpleAccumulator 接口实现自己的累加器。
本文来自博客园,作者:秋华,转载请注明原文链接:https://www.cnblogs.com/qiu-hua/p/14087528.html

