
实时电商数仓(九)之数据采集(八)数据库数据采集(三)canal安装
1 mysql的准备
1.1 导入模拟业务数据库
1.2 赋权限
在mysql中执行
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal' ;
1.3 修改/etc/my.cnf文件
server-id= 1 log-bin=mysql-bin binlog_format=row binlog-do-db=gmallXXXXX
1.4 重启Mysql
2 canal 安装
2.1 canal的下载
https://github.com/alibaba/canal/releases
把canal.deployer-1.1.4.tar.gz拷贝到linux,解压缩
2.2 修改canal的配置
vim conf/canal.properties
这个文件是canal的基本通用配置,主要关心一下端口号,不改的话默认就是11111


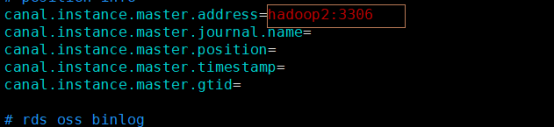
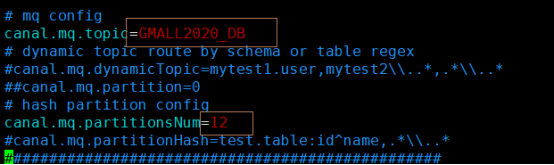
vim conf/example/instance.properties
instance.properties是针对要追踪的mysql的实例配置

2.3 把canal目录分发给其他虚拟机
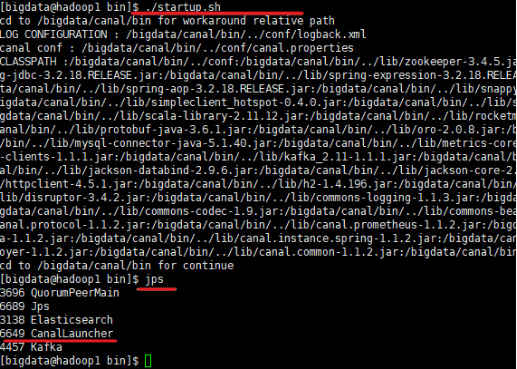
2.4 在2-3台节点中启动canal
启动canal
./bin/startup.sh
2.5 只是高可用,不是高负载
这种zookeeper为观察者监控的模式,只能实现高可用,而不是负载均衡,即同一时点只有一个canal-server节点能够监控某个数据源,只要这个节点能够正常工作,那么其他监控这个数据源的canal-server只能做stand-by,直到工作节点停掉,其他canal-server节点才能抢占。
3 kafka客户端测试
/bigdata/kafka_2.11-0.11.0.2/bin/kafka-console-consumer.sh --bootstrap-server hadoop1:9092,hadoop2:9092,hadoop3:9092 --topic GMALL2020_DB
分布式架构图

本文来自博客园,作者:秋华,转载请注明原文链接:https://www.cnblogs.com/qiu-hua/p/13658759.html

