
Flink基础(十四):DS简介(14) 搭建Flink运行流式应用
1 部署方式
1.1 独立集群
独立集群包含至少一个master进程,以及至少一个TaskManager进程,TaskManager进程运行在一台或者多台机器上。所有的进程都是JVM进程。下图展示了独立集群的部署。
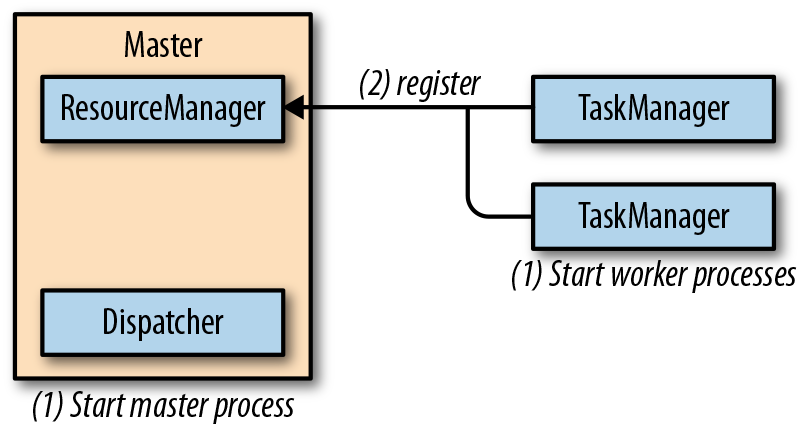
master进程在不同的线程中运行了一个Dispatcher和一个ResourceManager。一旦它们开始运行,所有TaskManager都将在Resourcemanager中进行注册。下图展示了一个任务如何提交到一个独立集群中去。
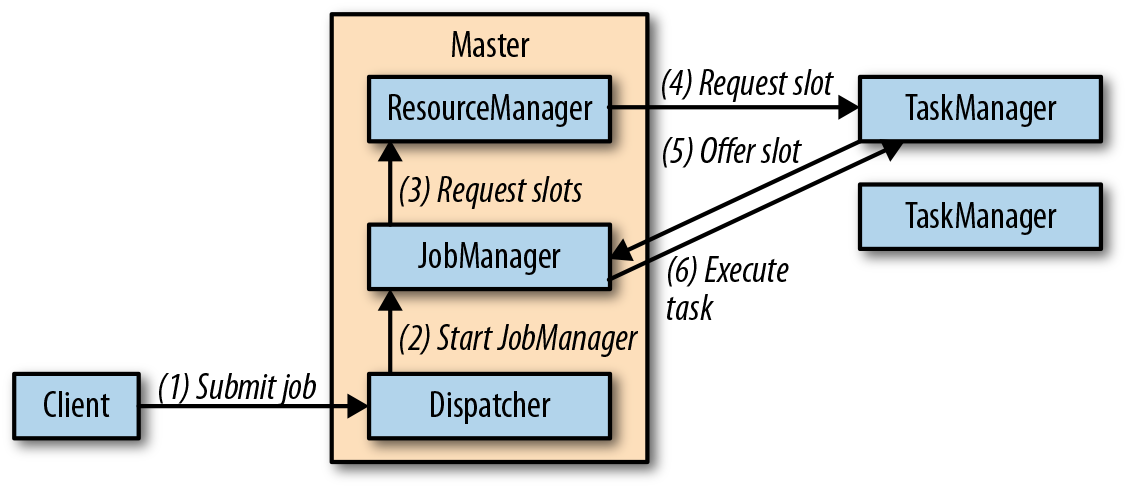
客户端向Dispatcher提交了一个任务,Dispatcher将会启动一个作业管理器线程,并提供执行所需的JobGraph。作业管理器向ResourceManager请求必要的task slots。一旦请求的slots分配好,作业管理器就会部署job。
在standalone这种部署方式中,master和worker进程在失败以后,并不会自动重启。如果有足够的slots可供使用,job是可以从一次worker失败中恢复的。只要我们运行多个worker就好了。但如果job想从master失败中恢复的话,则需要进行高可用(HA)的配置了。
部署步骤
下载压缩包
链接:http://mirror.bit.edu.cn/apache/flink/flink-1.11.0/flink-1.11.0-bin-scala_2.11.tgz
解压缩
$ tar xvfz flink-1.11.0-bin-scala_2.11.tgz
启动集群
$ cd flink-1.11.0
$ ./bin/start-cluster.sh
检查集群状态可以访问:http://localhost:8081
部署分布式集群
- 所有运行TaskManager的机器的主机名(或者IP地址)都需要写入
./conf/slaves文件中。 start-cluster.sh脚本需要所有机器的无密码的SSH登录配置,方便启动TaskManager进程。- Flink的文件夹在所有的机器上都需要有相同的绝对路径。
- 运行master进程的机器的主机名或者IP地址需要写在
./conf/flink-conf.yaml文件的jobmanager.rpc.address配置项。
一旦部署好,我们就可以调用./bin/start-cluster.sh命令启动集群了,脚本会在本地机器启动一个作业管理器,然后在每个slave机器上启动一个TaskManager。停止运行,请使用./bin/stop-cluster.sh。
1.2 Apache Hadoop Yarn
YARN是Apache Hadoop的资源管理组件。用来计算集群环境所需要的CPU和内存资源,然后提供给应用程序请求的资源。
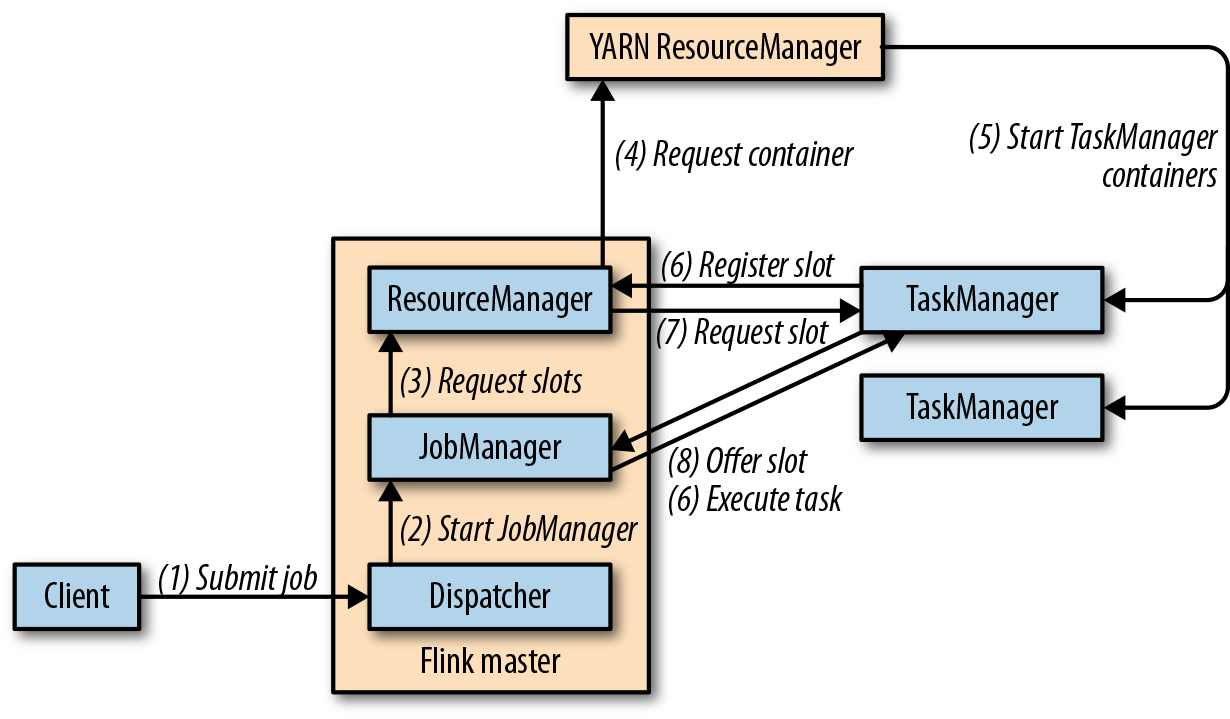
Flink在YARN上运行,有两种模式:job模式和session模式。在job模式中,Flink集群用来运行一个单独的job。一旦job结束,Flink集群停止,并释放所有资源。下图展示了Flink的job如何提交到YARN集群。
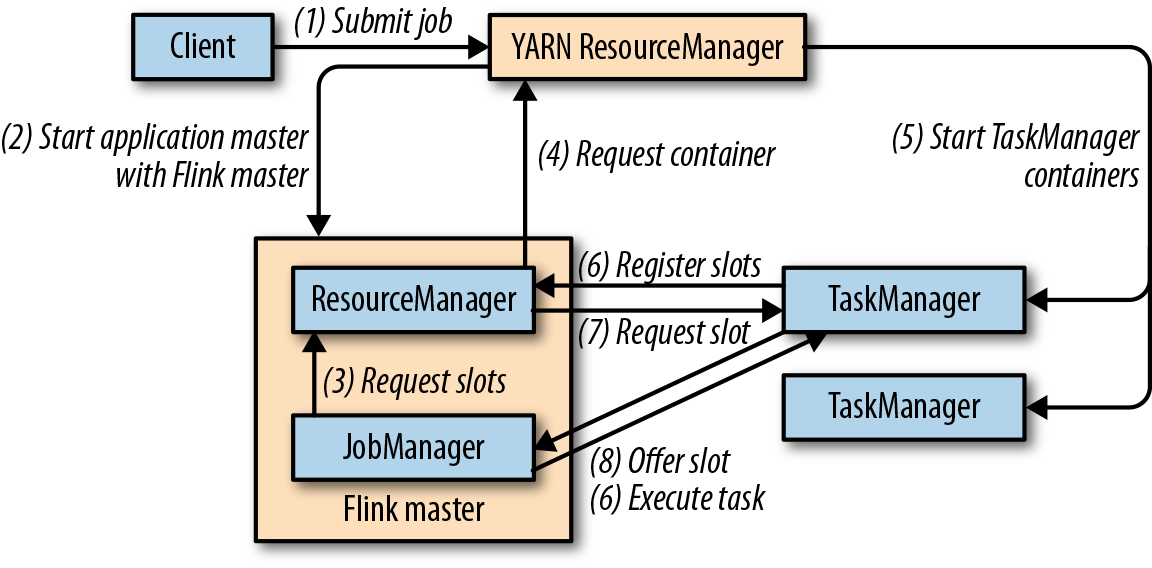
当客户端提交任务时,客户端将建立和YARN ResourceManager的连接,然后启动一个新的YARN应用的master进程,进程中包含一个作业管理器线程和一个ResourceManager。作业管理器向ResourceManager请求所需要的slots,用来运行Flink的job。接下来,Flink的ResourceManager将向Yarn的ResourceManager请求容器,然后启动TaskManager进程。一旦启动,TaskManager会将slots注册在Flink的ResourceManager中,Flink的ResourceManager将把slots提供给作业管理器。最终,作业管理器把job的任务提交给TaskManager执行。
sesison模式将启动一个长期运行的Flink集群,这个集群可以运行多个job,需要手动停止集群。如果以session模式启动,Flink将会连接到YARN的ResourceManager,然后启动一个master进程,包括一个Dispatcher线程和一个Flink的ResourceManager的线程。下图展示了一个Flink YARN session的启动。
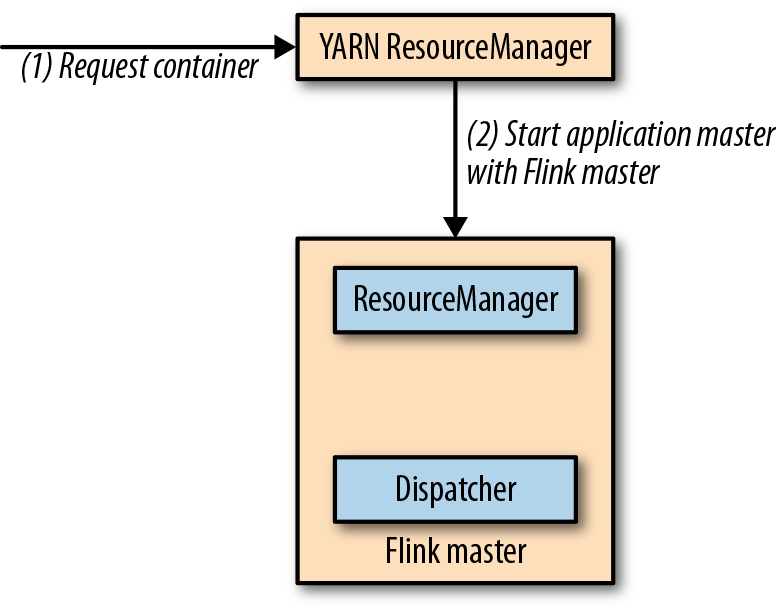
当一个作业被提交运行,分发器将启动一个作业管理器线程,这个线程将向Flink的资源管理器请求所需要的slots。如果没有足够的slots,Flink的资源管理器将向YARN的资源管理器请求额外的容器,来启动TaskManager进程,并在Flink的资源管理器中注册。一旦所需slots可用,Flink的资源管理器将把slots分配给作业管理器,然后开始执行job。下图展示了job如何在session模式下执行。
无论是作业模式还是会话模式,Flink的ResourceManager都会自动对故障的TaskManager进行重启。你可以通过./conf/flink-conf.yaml配置文件来控制Flink在YARN上的故障恢复行为。例如,可以配置有多少容器发生故障后终止应用。
无论使用job模式还是sesison模式,都需要能够访问Hadoop。
job模式可以用以下命令来提交任务:
$ ./bin/flink run -m yarn-cluster ./path/to/job.jar
参数-m用来定义提交作业的目标主机。如果加上关键字"yarn-cluster",客户端会将作业提交到由Hadoop配置所指定的YARN集群上。Flink的CLI客户端还支持很多参数,例如用于控制TaskManager容器内存大小的参数等。有关它们的详细信息,请参阅文档。Flink集群的Web UI由YARN集群某个节点上的主进程负责提供。你可以通过YARN的Web UI对其进行访问,具体链接位置在"Tracking URL: ApplicationMaster"下的Application Overview页面上。
session模式则是
$ ./bin/yarn-session.sh # 启动一个yarn会话
$ ./bin/flink run ./path/to/job.jar # 向会话提交作业
Flink的Web UI链接可以从YARN Web UI的Application Overview页面上找到。
2 高可用配置
Flink的高可用配置需要Apache ZooKeeper组件,以及一个分布式文件系统,例如HDFS等等。作业管理器将会把相关信息都存储在文件系统中,并将指向文件系统中相关信息的指针保存在ZooKeeper中。一旦失败,一个新的作业管理器将从ZooKeeper中指向相关信息的指针所指向的文件系统中读取元数据,并恢复运行。
配置文件编写
high-availability.zookeeper.quorum: address1:2181[,...],addressX:2181 high-availability.storageDir: hdfs:///flink/recovery high-availability.zookeeper.path.root: /flink
2.1 独立集群高可用配置
需要在配置文件中加一行集群标识符信息,因为可能多个集群共用一个zookeeper服务。
high-availability.cluster-id: /cluster-12.2 yarn集群高可用配置
首先在yarn集群的配置文件yarn-site.xml中加入以下代码
<property> <name>yarn.resourcemanager.am.max-attempts</name> <value>4</value> <description> The maximum number of application master execution attempts. Default value is 2, i.e., an application is restarted at most once. </description> </property>
然后在./conf/flink-conf.yaml加上
yarn.application-attempts: 4
3 与Hadoop集成
推荐两种方法
- 下载包含hadoop的Flink版本。
- 使用我们之前下载的Flink,然后配置Hadoop的环境变量。
export HADOOP_CLASSPATH={hadoop classpath}
我们还需要提供Hadoop配置文件的路径。只需设置名为HADOOP_CONF_DIR的环境变量就可以了。这样Flink就能够连上YARN的ResourceManager和HDFS了。
4 保存点操作
$ ./bin/flink savepoint <jobId> [savepointPath]
例如

$ ./bin/flink savepoint bc0b2ad61ecd4a615d92ce25390f61ad \ hdfs:///xxx:50070/savepoints Triggering savepoint for job bc0b2ad61ecd4a615d92ce25390f61ad. Waiting for response... Savepoint completed. Path: hdfs:///xxx:50070/savepoints/savepoint-bc0b2a-63cf5d5ccef8 You can resume your program from this savepoint with the run command.
删除保存点文件
$ ./bin/flink savepoint -d <savepointPath>
例子
$ ./bin/flink savepoint -d \ hdfs:///xxx:50070/savepoints/savepoint-bc0b2a-63cf5d5ccef8 Disposing savepoint 'hdfs:///xxx:50070/savepoints/savepoint-bc0b2a-63cf5d5ccef8'. Waiting for response... Savepoint 'hdfs:///xxx:50070/savepoints/savepoint-bc0b2a-63cf5d5ccef8' disposed.
5 取消一个应用
$ ./bin/flink cancel <jobId>
取消的同时做保存点操作
$ ./bin/flink cancel -s [savepointPath] <jobId>
例如
$ ./bin/flink cancel -s \ hdfs:///xxx:50070/savepoints d5fdaff43022954f5f02fcd8f25ef855 Cancelling job bc0b2ad61ecd4a615d92ce25390f61ad with savepoint to hdfs:///xxx:50070/savepoints. Cancelled job bc0b2ad61ecd4a615d92ce25390f61ad. Savepoint stored in hdfs:///xxx:50070/savepoints/savepoint-bc0b2a-d08de07fbb10.
6 从保存点启动应用程序
$ ./bin/flink run -s <savepointPath> [options] <jobJar> [arguments]
7 扩容,改变并行度操作
$ ./bin/flink modify <jobId> -p <newParallelism>
例子
$ ./bin/flink modify bc0b2ad61ecd4a615d92ce25390f61ad -p 16 Modify job bc0b2ad61ecd4a615d92ce25390f61ad. Rescaled job bc0b2ad61ecd4a615d92ce25390f61ad. Its new parallelism is 16.
本文来自博客园,作者:秋华,转载请注明原文链接:https://www.cnblogs.com/qiu-hua/p/13432510.html

