
HADOOP MAPREDUCE(11):Join应用
1 Reduce Join
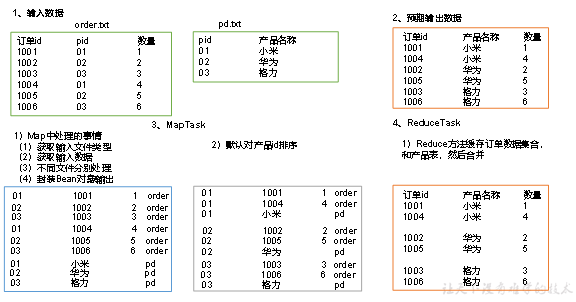
Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
Reduce端的主要工作:在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在Map阶段已经打标志)分开,最后进行合并就ok了。
2 Reduce Join案例实操
1)需求
表4-4 订单数据表t_order
|
id |
pid |
amount |
|
1001 |
01 |
1 |
|
1002 |
02 |
2 |
|
1003 |
03 |
3 |
|
1004 |
01 |
4 |
|
1005 |
02 |
5 |
|
1006 |
03 |
6 |
表4-5 商品信息表t_product
|
pid |
pname |
|
01 |
小米 |
|
02 |
华为 |
|
03 |
格力 |
将商品信息表中数据根据商品pid合并到订单数据表中。
表4-6 最终数据形式
|
id |
pname |
amount |
|
1001 |
小米 |
1 |
|
1004 |
小米 |
4 |
|
1002 |
华为 |
2 |
|
1005 |
华为 |
5 |
|
1003 |
格力 |
3 |
|
1006 |
格力 |
6 |
2)需求分析
通过将关联条件作为Map输出的key,将两表满足Join条件的数据并携带数据所来源的文件信息,发往同一个ReduceTask,在Reduce中进行数据的串联。
3)代码实现
4)测试
5)总结
缺点:这种方式中,合并的操作是在Reduce阶段完成,Reduce端的处理压力太大,Map节点的运算负载则很低,资源利用率不高,且在Reduce阶段极易产生数据倾斜。
解决方案:Map端实现数据合并。
3 Map Join
1)使用场景
Map Join适用于一张表十分小、一张表很大的场景。
2)优点
思考:在Reduce端处理过多的表,非常容易产生数据倾斜。怎么办?
在Map端缓存多张表,提前处理业务逻辑,这样增加Map端业务,减少Reduce端数据的压力,尽可能的减少数据倾斜。
3)具体办法:采用DistributedCache
(1)在Mapper的setup阶段,将文件读取到缓存集合中。
(2)在Driver驱动类中加载缓存。
4 Map Join案例实操
1)需求
表 订单数据表t_order
|
id |
pid |
amount |
|
1001 |
01 |
1 |
|
1002 |
02 |
2 |
|
1003 |
03 |
3 |
|
1004 |
01 |
4 |
|
1005 |
02 |
5 |
|
1006 |
03 |
6 |
表 商品信息表t_product
|
pid |
pname |
|
01 |
小米 |
|
02 |
华为 |
|
03 |
格力 |
将商品信息表中数据根据商品pid合并到订单数据表中。
表 最终数据形式
|
id |
pname |
amount |
|
1001 |
小米 |
1 |
|
1004 |
小米 |
4 |
|
1002 |
华为 |
2 |
|
1005 |
华为 |
5 |
|
1003 |
格力 |
3 |
|
1006 |
格力 |
6 |
2)需求分析
MapJoin适用于关联表中有小表的情形。

3)实现代码
本文来自博客园,作者:秋华,转载请注明原文链接:https://www.cnblogs.com/qiu-hua/p/13341103.html

