

python面试题二:Python 基础题
1.位和字节的关系?
Byte 字节
bit 位
1Byte = 8bit
2.b、B、KB、MB、GB 的关系?
1Byte = 8bit
KB 1KB=1024B
MB 1MB=1024KB
GB 1GB=1024MB
TB 1TB=1024GB
3.请至少列举5个 PEP8 规范(越多越好)。
一、代码编排
1 缩进。4个空格的缩进(编辑器都可以完成此功能),不使用Tap,更不能混合使用Tap和空格
2 每行最大长度79,换行可以使用反斜杠,最好使用圆括号。换行点要在操作符的后边敲回车。
3 类和top-level函数定义之间空两行;类中的方法定义之间空一行;函数内逻辑无关段落之间空一行;其他地方尽量不要再空行。
二、文档编排
1 模块内容的顺序:模块说明和docstring—import—globals&constants—其他定义。其中import部分,又按标准、三方和自己编写顺序依次排放,之间空一行。
2 不要在一句import中多个库,比如import os, sys不推荐。
3 如果采用from XX import XX引用库,可以省略‘module.’,都是可能出现命名冲突,这时就要采用import XX。
三、空格的使用
1 各种右括号前不要加空格。
2 逗号、冒号、分号前不要加空格。
3 函数的左括号前不要加空格。如Func(1)。
4 序列的左括号前不要加空格。如list[2]。
5 操作符左右各加一个空格,不要为了对齐增加空格。
6 函数默认参数使用的赋值符左右省略空格。
7 不要将多句语句写在同一行,尽管使用‘;’允许。
8 if/for/while语句中,即使执行语句只有一句,也必须另起一行。
四 注释
1.函数注释
"""
功能说明
参数 名称 类型
return
"""
2.变量注释
#注释
3.类型注解
https://www.cnblogs.com/yinzhengjie/p/10971296.html
4.通过代码实现如下转换:
二进制转换成十进制:v = “0b1111011”
int(a,2)
十进制转换成二进制:v = 18
bin(v)
八进制转换成十进制:v = “011”
a = bin(v)
b = int(a,2)
十进制转换成八进制:v = 30
oct(v)
十六进制转换成十进制:v = “0x12”
a = bin(v)
b = int(a,2)
十进制转换成十六进制:v = 87
hex(v)
5.请编写一个函数实现将IP地址转换成一个整数。
如 10.3.9.12 转换规则为:
10 00001010
3 00000011
9 00001001
12 00001100
再将以上二进制拼接起来计算十进制结果:00001010 00000011 00001001 00001100 = ?
6.python递归的最大层数?
import sys sys.setrecursionlimit(100000) def foo(n): print(n) n += 1 foo(n) if __name__ == '__main__': foo(1)
7.求结果:
v1 = 1 or 3 # 1 v2 = 1 and 3 # 3 v3 = 0 and 2 and 1 # 0 v4 = 0 and 2 or 1 # 1 v5 = 0 and 2 or 1 or 4 # 1 v6 = 0 or False and 1 # False
8.ascii、unicode、utf-8、gbk 区别?
美国制定了一套字符编码,对英文字符与二进制之间做了联系,这被称为ASCII码,一直沿用至今。
ASCII码一共规定了128个字符,比如SPACE是32,A是65,这128个符号只咱用了一个字节的后面七位,最前面的一位统一规定为0。
GBK编码是对GB2312的扩展,完全兼容GB2312。采用双字节编码方案,剔出xx7F码位,共23940个码位,共收录汉字和图形符号21886个,GBK编码方案于1995年12月15日发布。它几乎完美支持汉字,因此经常会遇见GBK与Unicode的转换。
将世界上所有的符号都纳入其中,每一种符号都给予独一无二的编码,那么乱码问题就不会存在了。因此,产生了Unicode编码,这是一种所有符号的编码。
UTF8就是在互联网中使用最多的对Unicode的实现方式。
UTF8编码规则只有两条:
1)对于单字节的符号,字节的第一位设为0,后面的7位为这个符号的Unicode码。因此,对于英文字母,UTF8编码和ASCII编码是相同的。
2)对于非单字节(假设字节长度为N)的符号,第一个字节的前N位都设为1,第N+1设为0,后面字节的前两位一律设为10,剩下的没有提及的二进制,全部为这个符号的Unicode码。
10.用一行代码实现数值交换:
a = 1 b = 2 a,b = b,a
11.列举布尔值为False的常见值?
为0的,空集合,空字符串,空值None
12.字符串、列表、元组、字典每个常用的5个方法?
13.pass的作用?
占位符
14.is和==的区别
Python中对象包含的三个基本要素,分别是:id(身份标识)、type(数据类型)和value(值)。
==是python标准操作符中的比较操作符,用来比较判断两个对象的value(值)是否相等
is也被叫做同一性运算符,这个运算符比较判断的是对象间的唯一身份标识,也就是id是否相同
15.Python的可变类型和不可变类型?
可变类型:列表、字典、数组、集合
不可变:数字,字符串,元组
16.求结果
v = dict.fromkeys(['k1','k2'],[])
v[‘k1’].append(666)
print(v)
v = dict.fromkeys(['k1','k2'],[]) v[‘k1’].append(666) print(v) # {‘k1’:[666],'k2':[666]} v[‘k1’] = 777 print(v)# {‘k1’:777,'k2':[666]}
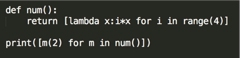
17 求结果:
18 列举常见的内置函数?
id(),dir(),dict(),zip(),set(),list(),int(),str(),print(),enumerate(),all(),any(),eval(),format(),getattr(),hasattr(),len(),map(),next(),range(),setatrr(),tuple()
20 一行代码实现9*9乘法表
for i in range(1,10): for j in range(1,i+1): print('%s * %s = %s ' %(i,j,i*j),end="") print() print('\n'.join(['\t'.join(["%2s*%2s=%2s"%(j,i,i*j) for j in range(1,i+1)]) for i in range(1,10)]))
21 至少列举8个常用模块都有那些?
os,time,re,datetime,requests,thread,multiprocessing,gevent,
22 re的match和search区别?
match 从字符串头部开始匹配
search 从字符串任意位置开始匹配
23 什么是正则的贪婪匹配?
贪婪模式也就是我们使用 .* 匹配任意字符时会尽可能长地向后匹配,如果我们想阻止这种贪婪模式,需要加个问号,尽可能少地匹配,如下例子:
In [1]: import re In [2]: html = '<h1> hello world </h1>' In [3]: re.findall(r'<.*>', html) # 贪婪模式默认匹配到所有内容 Out[3]: ['<h1> hello world </h1>'] In [4]: re.findall(r'<.*?>', html) # 我们只想匹配两个标签的内容,可以加上问号来阻止贪婪模式 Out[4]: ['<h1>', '</h1>']
24 求结果:
a. [ i % 2 for i in range(10) ]
b. ( i % 2 for i in range(10) )
a. [ i % 2 for i in range(10) ] # [0,1,0,1,0,1,0,1,0,1] b. ( i % 2 for i in range(10) ) # 生成器
25 求结果:
a. 1 or 2 # 1 b. 1 and 2 # 2 c. 1 < (2==2) # False d. 1 < 2 == 2 # True
Python能够正确处理这个链式对比的逻辑。回到最开始的问题上, = =等于符号和 <小于符号,本质没有什么区别。所以实际上 2==2>1也是一个链式对比的式子,它相当于 2==2and2>1。此时,这个式子就等价于 TrueandTrue。所以返回的结果为True。
注:True相当于1,False相当于0
26 def func(a,b=[]) 这种写法有什么坑?
def func(a,b=[]):
b.append(a)
print(b)
func(1)
func(1)
func(1)
func(1)

看下结果
[1]
[1, 1]
[1, 1, 1]
[1, 1, 1, 1]
函数的第二个默认参数是一个list,当第一次执行的时候实例化了一个list,第二次执行还是用第一次执行的时候实例化的地址存储,所以三次执行的结果就是 [1, 1, 1] ,想每次执行只输出[1] ,默认参数应该设置为None。
27 如何实现 “1,2,3” 变成 [‘1’,’2’,’3’] ?
[i for i in a.split(',')]
28 如何实现[‘1’,’2’,’3’]变成[1,2,3] ?
[int(i) for i in ['1','2','3']]
29 比较: a = [1,2,3] 和 b = [(1),(2),(3) ] 以及 b = [(1,),(2,),(3,) ] 的区别?
30 如何用一行代码生成[1,4,9,16,25,36,49,64,81,100] ?
[i**2 for i in range(1,11)]
31 一行代码实现删除列表中重复的值 ?
set(alist)
32 如何在函数中设置一个全局变量 ?
global a
33 logging模块的作用?以及应用场景?
logging模块定义的函数和类为应用程序和库的开发实现了一个灵活的事件日志系统。
开发应用程序或部署开发环境时,可以使用DEBUG或INFO级别的日志获取尽可能详细的日志信息来进行开发或部署调试;
应用上线或部署生产环境时,应该使用WARNING或ERROR或CRITICAL级别的日志来降低机器的I/O压力和提高获取错误日志信息的效率。
日志级别的指定通常都是在应用程序的配置文件中进行指定的。
34 请用代码简答实现stack 。
class Stack(object): def __init__(self): self.stack = [] def push(self, value): # 进栈 self.stack.append(value) def pop(self): # 出栈 if self.stack : self.stack.pop() else: raise LookupError("stack is empty") def is_empty(self): # 如果栈为空 return bool(self.stack) def top(self): # 取出目前stack中最新的元素 return self.stack[-1]
35 常用字符串格式化哪几种?
% 格式符
.format()
36 简述 生成器、迭代器、可迭代对象 以及应用场景?
可迭代对象:可以通过for ... in ...这类语句迭代读取一条数据的对象(具备__iter__方法的对象)
迭代器:一个实现了__iter__方法和__next__方法的对象,就是迭代器
生成器:一类特殊的迭代器
创建生成器的方法:a.将[]变为() b.在def 中有yield关键字的称为生成器(使用send唤醒)
37 用Python实现一个二分查找的函数。
def binary_chop(alist, data): """ 非递归解决二分查找 :param alist: :return: """ n = len(alist) first = 0 last = n - 1 while first <= last: mid = (last + first) // 2 if alist[mid] > data: last = mid - 1 elif alist[mid] < data: first = mid + 1 else: return True return False if __name__ == '__main__': lis = [2,4, 5, 12, 14, 23] if binary_chop(lis, 14): print('ok')
38 os和sys模块的作用?
39 如何生成一个随机数?
import random random.randint(1,100) random.random()
random.choice(['剪刀', '石头', '布'])
40 如何使用python删除一个文件?
os.remove() 方法用于删除指定路径的文件。如果指定的路径是一个目录,将抛出OSError。
os.removedirs() 方法用于递归删除目录。像rmdir(), 如果子文件夹成功删除, removedirs()才尝试它们的父文件夹,直到抛出一个error(它基本上被忽略,因为它一般意味着你文件夹不为空)。
os.rmdir() 方法用于删除指定路径的目录。仅当这文件夹是空的才可以, 否则, 抛出OSError。
os.unlink() 方法用于删除文件,如果文件是一个目录则返回一个错误。
41 谈谈你对面向对象的理解?
42 面向对象深度优先和广度优先是什么?
43 面向对象中super的作用?
44 是否使用过functools中的函数?其作用是什么?
45 列举面向对象中带爽下划线的特殊方法,如:__new__、__init__
46 如何判断是函数还是方法?
47 列举面向对象中的特殊成员以及应用场景
48 1、2、3、4、5 能组成多少个互不相同且无重复的三位数
60个
49 什么是反射?以及应用场景?
50 什么是面向对象的mro
51 异常处理写法?以及如何主动抛出异常?(应用场景)自定义异常代码
异常处理写法
(1)第一种写法
需要注意的是 在抛出异常的时候,HTTPError必须写在URLError之前,因为只有这样前者才能抛出异常,不然的话就会被后者拦截,提前抛出异常。
from urllib.request import Request,urlopen from urllib.error import URLError,HTTPError #请求某一个地址 req = Request(someurl) try: response = urlopen(req) except HTTPError as e: print("The server conldn\'t fulfill the request.") except URLError as e: print('We failed to reach a server.') print('reason:',e.reason) else: #everything is fine
(2)第二种写法
from urllib.request import Request,urlopen from urllib.error import URLError #请求某一个地址 req = Request("http://xx.baidu.com") try: response = urlopen(req) except URLError as e: if hasattr(e,'reason'): print("We failed to reach a server") elif hasattr(e,'code'): print("The server couldn\'t ful fill the request.") else: print("everything is fine") #hasattr判断是否拥有这个属性,如果有的话就打印,如果没有判断下一个,建议使用第二个抛异常方法。
主动抛出异常
格式:
主动抛出异常终止程序
raise 异常名称('异常描述')
raise RuntimeError('testError')
自定义异常代码
python的异常分为两种.
1、内建异常,就是python自己定义的异常。
2、不够用,用户自定义异常,
首先看看python的异常继承树

我们可以看到python的异常有个大基类。然后继承的是Exception。所以我们自定义类也必须继承Exception。
#最简单的自定义异常 class FError(Exception): pass
抛出异常、用try-except抛出
try: raise FError("自定义异常") except FError as e: print(e)
52 isinstance作用以及应用场景?
判断变量类型
53 json序列化时,可以处理的数据类型有哪些?如何定制支持datetime类型?
字典以及列表
自定义时间序列化转换器 import json from json import JSONEncoder from datetime import datetime class ComplexEncoder(JSONEncoder): def default(self, obj): if isinstance(obj, datetime): return obj.strftime('%Y-%m-%d %H:%M:%S') else: return super(ComplexEncoder,self).default(obj) d = { 'name':'alex','data':datetime.now()} print(json.dumps(d,cls=ComplexEncoder)) # {"name": "alex", "data": "2018-05-18 19:52:05"}
54 json序列化时,默认遇到中文会转换成unicode,如果想要保留中文怎么办?
import json a=json.dumps({"ddf":"你好"},ensure_ascii=False) print(a) #{"ddf": "你好"}
55 什么是断言?应用场景?
Python的assert是用来检查一个条件,如果它为真,就不做任何事。如果它为假,则会抛出AssertError并且包含错误信息。例如:
x = 23 assert x > 0, "x is not zero or negative" assert x%2 == 0, "x is not an even number"
断言应该用于:
防御型的编程
运行时检查程序逻辑
检查约定
程序常量
检查文档
56 有用过with statement吗?它的好处是什么?
with语句的作用是通过某种方式简化异常处理,它是所谓的上下文管理器的一种
with open('output.txt', 'w') as f: f.write('Hi there!')
当你要成对执行两个相关的操作的时候,这样就很方便,以上便是经典例子,with语句会在嵌套的代码执行之后,自动关闭文件。这种做法的还有另一个优势就是,无论嵌套的代码是以何种方式结束的,它都关闭文件。如果在嵌套的代码中发生异常,它能够在外部exception handler catch异常前关闭文件。如果嵌套代码有return/continue/break语句,它同样能够关闭文件。
57 使用代码实现查看列举目录下的所有文件。
import re import os import time def print_files(path): lsdir = os.listdir(path) dirs = [i for i in lsdir if os.path.isdir(os.path.join(path, i))] if dirs: for i in dirs: print_files(os.path.join(path, i)) files = [i for i in lsdir if os.path.isfile(os.path.join(path,i))] #for f in files: #列出所有文件(包括子目录下的文件) for f in dirs: #列出所有目录(包括子目录下的目录) sss = (os.path.join(path, f)) if os.path.isdir(sss): #判断路径是否为目录 print (sss) return print_files('/test/test1/') #列出'/test/test1/'目录下的所有文件或目录(包括子目录)
58 简述 yield和yield from关键字。
简单地说,yield from generator 。实际上就是返回另外一个生成器
def generator1(): item = range(10) for i in item: yield i def generator2(): yield 'a' yield 'b' yield 'c' yield from generator1() #yield from iterable本质上等于 for item in iterable: yield item的缩写版 yield from [11,22,33,44] yield from (12,23,34) yield from range(3) for i in generator2() : print(i)
从上面的代码可以看书,yield from 后面可以跟的式子有“ 生成器 元组 列表等可迭代对象以及range()函数产生的序列”
59 python 获取当前日期
1.先导入库:import datetime 2.获取当前日期和时间:now_time = datetime.datetime.now() 3.格式化成我们想要的日期:strftime() 比如:“2016-09-21”:datetime.datetime.now().strftime('%Y-%m-%d') 4.在当前时间增加1小时:add_hour=datetime.datetime.now()+datetime.timedelta(hours=1) #需要导入timedelta库 格式“小时”:now_hour=add_hour.strftime('%H') 5.时间的三种存在方式:时间对象,时间字符串,时间戳。 (1)字符串转datetime: >>> string = '2014-01-08 11:59:58' >>> time1 = datetime.datetime.strptime(string,'%Y-%m-%d %H:%M:%S') >>> print time1 2014-01-08 11:59:58 (2)datetime转字符串: >>> time1_str = datetime.datetime.strftime(time1,'%Y-%m-%d %H:%M:%S') >>> time1_str '2014-01-08 11:59:58' (3)时间戳转时间对象: >>>time1 = time.localtime() >>>time1_str = datetime.datetime.fromtimestamp(time1) 6.格式参数: %a 星期几的简写 %A 星期几的全称 %b 月分的简写 %B 月份的全称 %c 标准的日期的时间串 %C 年份的后两位数字 %d 十进制表示的每月的第几天 %D 月/天/年 %e 在两字符域中,十进制表示的每月的第几天 %F 年-月-日 %g 年份的后两位数字,使用基于周的年 %G 年分,使用基于周的年 %h 简写的月份名 %H 24小时制的小时 %I 12小时制的小时 %j 十进制表示的每年的第几天 %m 十进制表示的月份 %M 十时制表示的分钟数 %n 新行符 %p 本地的AM或PM的等价显示 %r 12小时的时间 %R 显示小时和分钟:hh:mm %S 十进制的秒数 %t 水平制表符 %T 显示时分秒:hh:mm:ss %u 每周的第几天,星期一为第一天 (值从0到6,星期一为0) %U 第年的第几周,把星期日做为第一天(值从0到53) %V 每年的第几周,使用基于周的年 %w 十进制表示的星期几(值从0到6,星期天为0) %W 每年的第几周,把星期一做为第一天(值从0到53) %x 标准的日期串 %X 标准的时间串 %y 不带世纪的十进制年份(值从0到99) %Y 带世纪部分的十制年份 %z,%Z 时区名称,如果不能得到时区名称则返回空字符。 %% 百分号
60 将“hello world” 转换为首字母大写“Hello World”
captilize()
61 检测字符串是否只含有数字
str.isdigit()
62 打乱一个列表的元素
# shuffle()使用样例 import random x = [i for i in range(10)] print(x) random.shuffle(x) print(x)
#encoding:utf-8 from datetime import date, datetime, timedelta day = date.today() now = datetime.now() delta = timedelta(days=5) n_days_after = now + delta n_days_forward = now - delta print(("当前日期:{}").format(day)) print("向后推迟5天的日期:{}".format(n_days_after.strftime('%Y-%m-%d'))) print("向前推5天的日期:{}".format(n_days_forward.strftime('%Y-%m-%d')))
#any(x)判断x对象是否为空对象,如果都为空、0、false,则返回false,如果不都为空、0、false,则返回true
#all(x)如果all(x)参数x对象的所有元素不为0、''、False或者x为空对象,则返回True,否则返回False
本文来自博客园,作者:秋华,转载请注明原文链接:https://www.cnblogs.com/qiu-hua/p/12232858.html

