

python 面试题一:Python语言特性
1 Python的函数参数传递
两个例子
a = 1 def fun(a): a = 2 fun(a) print a # 1
a = [] def fun(a): a.append(1) fun(a) print a # [1]
所有的变量都可以理解是内存中一个对象的“引用”,或者,也可以看似c中void*的感觉。
通过id来看引用a的内存地址可以比较理解:
a = 1 def fun(a): print "func_in",id(a) # func_in 41322472 a = 2 print "re-point",id(a), id(2) # re-point 41322448 41322448 print "func_out",id(a), id(1) # func_out 41322472 41322472 fun(a) print a # 1
注:具体的值在不同电脑上运行时可能不同。
可以看到,在执行完a = 2之后,a引用中保存的值,即内存地址发生变化,由原来1对象的所在的地址变成了2这个实体对象的内存地址。
而第2个例子a引用保存的内存值就不会发生变化:
a = [] def fun(a): print "func_in",id(a) # func_in 53629256 a.append(1) print "func_out",id(a) # func_out 53629256 fun(a) print a # [1]
这里记住的是类型是属于对象的,而不是变量。而对象有两种,“可更改”(mutable)与“不可更改”(immutable)对象。在python中,strings, tuples, 和numbers是不可更改的对象,而 list, dict, set 等则是可以修改的对象。(这就是这个问题的重点)
当一个引用传递给函数的时候,函数自动复制一份引用,这个函数里的引用和外边的引用没有半毛关系了.所以第一个例子里函数把引用指向了一个不可变对象,当函数返回的时候,外面的引用没半毛感觉.而第二个例子就不一样了,函数内的引用指向的是可变对象,对它的操作就和定位了指针地址一样,在内存里进行修改.
2 Python中的元类(metaclass)
a.作用:
metaclass 就是创建类的那家伙。(事实上,type就是一个metaclass)
那么,metaclass就是用来创造“类对象”的类.它是“类对象”的“类”。 如下图所示:
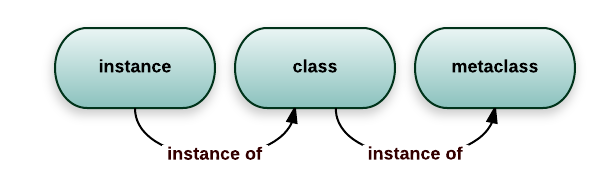
b.如何创建:
例 MyClass = MetaClass() #生成类对象 MyObject = MyClass() #生成实例对象
也可以用我们上面学到的type来表示:
MyClass = type('MyClass', (), {})
说白了,函数type就是一个特殊的metaclass.
python在背后使用type创造了所有的类。type是所有类的metaclass.
metaclass就是创造类对象的工具.如果你喜欢,你也可以称之为"类的工厂".
type是python內置的metaclass。不过,你也可以编写自己的metaclass.
__metaclass__ 属性 以及 创建过程
我们可以在一个类中加入 __metaclass__ 属性.
class Foo(object): __metaclass__ = something... ...... # 省略
当你这么做了,python就会使用metaclass来创造类:Foo
注意啦,这里有些技巧的。
当你写下class Foo(object)的时候,类对象Foo还没有在内存中生成。
python会在类定义中寻找__metaclass__ 。如果找到了,python就会使用这个__metaclass__ 来创造类对象: Foo。如果没找到,python就使用type来创造Foo。
请把下面的几段话重复几遍:
当你写如下代码的时候:
class Foo(Bar): pass
python做了以下事情:
Foo中有__metaclass__这个属性吗?
如果有,python会在内存中通过__metaclass__创建一个名字为Foo的类对象。
如果python没有在Foo中找到__metaclass__,它会继续在Bar(父类)中寻找__metaclass__,并尝试做和前面同样的操作。
如果python由下往上遍历父类也都没有找不到__metaclass__,它就会在模块(module)中去寻找__metaclass__,并尝试做同样的操作。
如果还是没有找不到__metaclass__, python才会用内置的type(这也是一个metaclass)来创建这个类对象。
现在问题来了,我们要怎么用代码来实现__metaclass__呢? 写一些可以用来产生类(class)的东西就行。
那什么可以产生类?无疑就是type,或者type的任何子类,或者任何使用到type的东西都行.
自定义metaclass
使用metaclass的主要目的,是为了能够在创建类的时候,自动地修改类。
例:一个很傻的需求,我们决定要将该模块中的所有类的属性,改为大写。
# type也是一个类,我们可以继承它. class UpperAttrMetaclass(type): # __new__ 是在__init__之前被调用的特殊方法 # __new__是用来创建对象并返回这个对象 # 而__init__只是将传入的参数初始化给对象 # 实际中,你很少会用到__new__,除非你希望能够控制对象的创建 # 在这里,类是我们要创建的对象,我们希望能够自定义它,所以我们改写了__new__ # 如果你希望的话,你也可以在__init__中做些事情 # 还有一些高级的用法会涉及到改写__call__,但这里我们就先不这样. def __new__(upperattr_metaclass, future_class_name, future_class_parents, future_class_attr): uppercase_attr = {} for name, val in future_class_attr.items(): if not name.startswith('__'): uppercase_attr[name.upper()] = val else: uppercase_attr[name] = val return type(future_class_name, future_class_parents, uppercase_attr)
这里的方式其实不是OOP(面向对象编程).因为我们直接调用了type,而不是改写父类的__type__方法.
class UpperAttrMetaclass(type): def __new__(upperattr_metaclass, future_class_name, future_class_parents, future_class_attr): uppercase_attr = {} for name, val in future_class_attr.items(): if not name.startswith('__'): uppercase_attr[name.upper()] = val else: uppercase_attr[name] = val return type.__new__(upperattr_metaclass, future_class_name, future_class_parents, uppercase_attr)
这样子看,我们只是复用了 type.__new__方法,这就是我们熟悉的基本的OOP编程,没什么魔法可言.
又或者:
class UpperAttrMetaclass(type): def __new__(cls, clsname, bases, attrs): uppercase_attr = {} for name, val in attrs.items(): if not name.startswith('__'): uppercase_attr[name.upper()] = val else: uppercase_attr[name] = val return super(UpperAttrMetaclass, cls).__new__(cls, clsname, bases, attrs)
使用了 metaclass 的代码是比较复杂,但我们使用它的原因并不是为了复杂, 而是因为我们通常会使用 metaclass 去做一些晦涩的事情,比如, 依赖于自省,控制继承等等。
确实,用 metaclass 来搞些“黑魔法”是特别有用的,因而会复杂化代码。
但就metaclass本身而言,它们其实是很简单的:中断类的默认创建、修改类、最后返回修改后的类.
c.运用场景:
实际用到metaclass的人,很清楚他们到底需要做什么,根本不用解释为什么要用.
metaclass 的一个主要用途就是构建API。
3 @staticmethod和@classmethod
Python其实有3个方法,即静态方法(staticmethod),类方法(classmethod)和实例方法,如下:
def foo(x): print "executing foo(%s)"%(x) class A(object): def foo(self,x): print "executing foo(%s,%s)"%(self,x) @classmethod def class_foo(cls,x): print "executing class_foo(%s,%s)"%(cls,x) @staticmethod def static_foo(x): print "executing static_foo(%s)"%x a=A()
这里先理解下函数参数里面的self和cls.这个self和cls是对类或者实例的绑定,对于一般的函数来说我们可以这么调用foo(x),这个函数就是最常用的,它的工作跟任何东西(类,实例)无关.对于实例方法,我们知道在类里每次定义方法的时候都需要绑定这个实例,就是foo(self, x),为什么要这么做呢?因为实例方法的调用离不开实例,我们需要把实例自己传给函数,调用的时候是这样的a.foo(x)(其实是foo(a, x)).类方法一样,只不过它传递的是类而不是实例,A.class_foo(x).注意这里的self和cls可以替换别的参数,但是python的约定是这俩,还是不要改的好.
对于静态方法其实和普通的方法一样,不需要对谁进行绑定,唯一的区别是调用的时候需要使用a.static_foo(x)或者A.static_foo(x)来调用.

4 类变量和实例变量
类变量:
是可在类的所有实例之间共享的值(也就是说,它们不是单独分配给每个实例的)。例如下例中,num_of_instance 就是类变量,用于跟踪存在着多少个Test 的实例。
实例变量:
实例化之后,每个实例单独拥有的变量。
class Test(object): num_of_instance = 0 def __init__(self, name): self.name = name Test.num_of_instance += 1 if __name__ == '__main__': print Test.num_of_instance # 0 t1 = Test('jack') print Test.num_of_instance # 1 t2 = Test('lucy') print t1.name , t1.num_of_instance # jack 2 print t2.name , t2.num_of_instance # lucy 2
补充的例子
class Person: name="aaa" p1=Person() p2=Person() p1.name="bbb" print p1.name # bbb print p2.name # aaa print Person.name # aaa
这里p1.name="bbb"是实例调用了类变量,这其实和上面第一个问题一样,就是函数传参的问题,p1.name一开始是指向的类变量name="aaa",但是在实例的作用域里把类变量的引用改变了,就变成了一个实例变量,self.name不再引用Person的类变量name了.
可以看看下面的例子:
class Person: name=[] p1=Person() p2=Person() p1.name.append(1) print p1.name # [1] print p2.name # [1] print Person.name # [1]
5 Python自省
自省就是面向对象的语言所写的程序在运行时,所能知道对象的类型.简单一句就是运行时能够获得对象的类型.比如type(),dir(),getattr(),hasattr(),isinstance().
hasattr(object, name)
判断一个对象里面是否有name属性或者name方法,返回BOOL值,有name特性返回True, 否则返回False。
需要注意的是name要用括号括起来

1 >>> class test(): 2 ... name="xiaohua" 3 ... def run(self): 4 ... return "HelloWord" 5 ... 6 >>> t=test() 7 >>> hasattr(t, "name") #判断对象有name属性 8 True 9 >>> hasattr(t, "run") #判断对象有run方法 10 True 11 >>>
getattr(object, name[,default])
获取对象object的属性或者方法,如果存在打印出来,如果不存在,打印出默认值,默认值可选。
需要注意的是,如果是返回的对象的方法,返回的是方法的内存地址,如果需要运行这个方法,
可以在后面添加一对括号。
1 >>> class test(): 2 ... name="xiaohua" 3 ... def run(self): 4 ... return "HelloWord" 5 ... 6 >>> t=test() 7 >>> getattr(t, "name") #获取name属性,存在就打印出来。 8 'xiaohua' 9 >>> getattr(t, "run") #获取run方法,存在就打印出方法的内存地址。 10 <bound method test.run of <__main__.test instance at 0x0269C878>> 11 >>> getattr(t, "run")() #获取run方法,后面加括号可以将这个方法运行。 12 'HelloWord' 13 >>> getattr(t, "age") #获取一个不存在的属性。 14 Traceback (most recent call last): 15 File "<stdin>", line 1, in <module> 16 AttributeError: test instance has no attribute 'age' 17 >>> getattr(t, "age","18") #若属性不存在,返回一个默认值。 18 '18' 19 >>>
setattr(object, name, values)
给对象的属性赋值,若属性不存在,先创建再赋值。
1 >>> class test(): 2 ... name="xiaohua" 3 ... def run(self): 4 ... return "HelloWord" 5 ... 6 >>> t=test() 7 >>> hasattr(t, "age") #判断属性是否存在 8 False 9 >>> setattr(t, "age", "18") #为属相赋值,并没有返回值 10 >>> hasattr(t, "age") #属性存在了 11 True 12 >>>
一种综合的用法是:判断一个对象的属性是否存在,若不存在就添加该属性。
1 >>> class test(): 2 ... name="xiaohua" 3 ... def run(self): 4 ... return "HelloWord" 5 ... 6 >>> t=test() 7 >>> getattr(t, "age") #age属性不存在 8 Traceback (most recent call last): 9 File "<stdin>", line 1, in <module> 10 AttributeError: test instance has no attribute 'age' 11 >>> getattr(t, "age", setattr(t, "age", "18")) #age属性不存在时,设置该属性 12 '18' 13 >>> getattr(t, "age") #可检测设置成功 14 '18' 15 >>>
6 字典推导式
d = {key: value for (key, value) in iterable}
7 Python中单下划线和双下划线
>>> class MyClass(): ... def __init__(self): ... self.__superprivate = "Hello" ... self._semiprivate = ", world!" ... >>> mc = MyClass() >>> print mc.__superprivate Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: myClass instance has no attribute '__superprivate' >>> print mc._semiprivate , world! >>> print mc.__dict__ {'_MyClass__superprivate': 'Hello', '_semiprivate': ', world!'}
__foo__:一种约定,Python内部的名字,用来区别其他用户自定义的命名,以防冲突,就是例如__init__(),__del__(),__call__()这些特殊方法
_foo:一种约定,用来指定变量私有.程序员用来指定私有变量的一种方式.不能用from module import * 导入,其他方面和公有一样访问;
__foo:这个有真正的意义:解析器用_classname__foo来代替这个名字,以区别和其他类相同的命名,它无法直接像公有成员一样随便访问,通过对象名._类名__xxx这样的方式可以访问.
8 字符串格式化:%和.format
实例:
"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
"{0} {1}".format("hello", "world") # 设置指定位置
"{1} {0} {1}".format("hello", "world") # 设置指定位置
print("{:.2f}".format(3.1415926));
# 通过字典设置参数 site = {"name": "菜鸟教程", "url": "www.runoob.com"} print("网站名:{name}, 地址 {url}".format(**site))
# 通过列表索引设置参数 my_list = ['菜鸟教程', 'www.runoob.com'] print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的
9 迭代器和生成器
10 *args and **kwargs
用*args和**kwargs只是为了方便并没有强制使用它们.
当你不确定你的函数里将要传递多少参数时你可以用*args.例如,它可以传递任意数量的参数:
>>> def print_everything(*args): for count, thing in enumerate(args): ... print '{0}. {1}'.format(count, thing) ... >>> print_everything('apple', 'banana', 'cabbage') 0. apple 1. banana 2. cabbage
相似的,**kwargs允许你使用没有事先定义的参数名:
>>> def table_things(**kwargs): ... for name, value in kwargs.items(): ... print '{0} = {1}'.format(name, value) ... >>> table_things(apple = 'fruit', cabbage = 'vegetable') cabbage = vegetable apple = fruit
你也可以混着用.命名参数首先获得参数值然后所有的其他参数都传递给*args和**kwargs.命名参数在列表的最前端.例如:
def table_things(titlestring, **kwargs)*args和**kwargs可以同时在函数的定义中,但是*args必须在**kwargs前面.
当调用函数时你也可以用*和**语法.例如:
>>> def print_three_things(a, b, c): ... print 'a = {0}, b = {1}, c = {2}'.format(a,b,c) ... >>> mylist = ['aardvark', 'baboon', 'cat'] >>> print_three_things(*mylist)
a = aardvark, b = baboon, c = cat
就像你看到的一样,它可以传递列表(或者元组)的每一项并把它们解包.注意必须与它们在函数里的参数相吻合.当然,你也可以在函数定义或者函数调用时用*.
11 面向切面编程AOP和装饰器
a.装饰器的作用
装饰器的作用就是为已经存在的对象添加额外的功能。
b.装饰器原理与闭包
c.装饰器分类
1.类装饰器
2.函数装饰器
d.装饰器传参
12 鸭子类型
13 Python中重载
函数重载主要是为了解决两个问题。
- 可变参数类型。 python 函数可以接受任意类型的参数
- 可变参数个数。 python 对那些缺少的参数设定为缺省参数即可解决问题。因为你假设函数功能相同,那么那些缺少的参数终归是需要用的。
- 因此python不需要函数重载
14 新式类和旧式类
一个旧式类的深度优先的例子
按照经典类的查找顺序从左到右深度优先的规则,在访问d.foo1()的时候,D这个类是没有的..那么往上查找,先找到B,里面没有,深度优先,访问A,找到了foo1(),所以这时候调用的是A的foo1(),从而导致C重写的foo1()被绕过
15 __new__和__init__的区别
这个__new__确实很少见到,先做了解吧.
__new__是一个静态方法,而__init__是一个实例方法.__new__方法会返回一个创建的实例,而__init__什么都不返回.- 只有在
__new__返回一个cls的实例时后面的__init__才能被调用. - 当创建一个新实例时调用
__new__,初始化一个实例时用__init__.
16 单例模式
a.单例的作用:
单例模式是一种常用的软件设计模式。在它的核心结构中只包含一个被称为单例类的特殊类。通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统资源。如果希望在系统中某个类的对象只能存在一个,单例模式是最好的解决方案。
b.实现
1.使用__new__()
class Singleton(object): def __new__(cls, *args, **kw): if not hasattr(cls, '_instance'): orig = super(Singleton, cls) cls._instance = orig.__new__(cls, *args, **kw) return cls._instance class MyClass(Singleton): a = 1
2.共享属性
创建实例时把所有实例的__dict__指向同一个字典,这样它们具有相同的属性和方法.
class Borg(object): _state = {} def __new__(cls, *args, **kw): ob = super(Borg, cls).__new__(cls, *args, **kw) ob.__dict__ = cls._state return ob class MyClass2(Borg): a = 1
3.装饰器
def singleton(cls): instances = {} def getinstance(*args, **kw): if cls not in instances: instances[cls] = cls(*args, **kw) return instances[cls] return getinstance @singleton class MyClass: ...
4 import方法
作为python的模块是天然的单例模式
# mysingleton.py class My_Singleton(object): def foo(self): pass my_singleton = My_Singleton() # to use from mysingleton import my_singleton my_singleton.foo()
17 Python中的作用域
Python 中,一个变量的作用域总是由在代码中被赋值的地方所决定的。
当 Python 遇到一个变量的话他会按照这样的顺序进行搜索:
本地作用域(Local)→当前作用域被嵌入的本地作用域(Enclosing locals)→全局/模块作用域(Global)→内置作用域(Built-in)
18 GIL线程全局锁
a.定义:线程全局锁(Global Interpreter Lock),即Python为了保证线程安全而采取的独立线程运行的限制,说白了就是一个核只能在同一时间运行一个线程.
b.缺陷:对于io密集型任务,python的多线程起到作用,但对于cpu密集型任务,python的多线程几乎占不到任何优势,还有可能因为争夺资源而变慢。
c.实现:
import threading #创建锁对象 lock = threading.Lock() #获取锁 lock.acquire() # 要锁定的语句 #释放锁 lock.release()
d 替代方案:多进程和协程(协程也只是单CPU,但是能减小切换代价提升性能).
19 协程
a.定义:
是python中另外一种实现多任务的方式,比线程更小占用执行单元
在一个线程中的某个函数,可以在任何地方保存当前函数的一些临时变量等信息,然后切换到另外一个函数中执行,注意不是通过调用函数的方式做到的,并且切换的次数以及什么时候再切换到原来的函数都由开发者自己确定
b.实现:
import time def work1(): while True: print("-----work1-----") yield time.sleep(0.5) def work2(): while True: print("-----work2-----") yield time.sleep(0.5) def main(): w1 = work1() w2 = work2() while True: next(w1) next(w2) if __name__ == '__main__': main()
20 闭包
a.定义:
当一个内嵌函数引用其外部作作用域的变量,我们就会得到一个闭包.
b.特点 :
- 必须有一个内嵌函数
- 内嵌函数必须引用外部函数中的变量
- 外部函数的返回值必须是内嵌函数
21 lambda函数
a.输入与输出:
lambda [arg1[, arg2, ... argN]]: expression
参数是可选的,如果使用的参数话,参数通常也是表达式的一部分
b.使用
lambda x, y: xy;函数输入是x和y,输出是它们的积xy
lambda:None;函数没有输入参数,输出是None
lambda *args: sum(args); 输入是任意个数的参数,输出是它们的和(隐性要求是输入参数必须能够进行加法运算)
lambda **kwargs: 1;输入是任意键值对参数,输出是1
lambda函数主要用来写一些小体量的一次性函数,避免污染环境,同时也能简化代码。
lambda起到了一种函数速写的作用,允许在使用的代码内嵌入一个函数的定义。他们完全是可选的(你总是能够使用def来替代它们),但是你仅需要嵌入小段可执行代码的情况下它们会带来一个更简洁的代码结构。
map( lambda x: x*x, [y for y in range(10)] )
lambda使用可以加参数也可以不加参数
lambda通常用来编写跳转表(jump table),也就是行为的列表或字典,能够按照需要执行相应的动作

22 Python函数式编程
a.filter 函数的功能相当于过滤器。调用一个布尔函数bool_func来迭代遍历每个seq中的元素;返回一个使bool_seq返回值为true的元素的序列。
>>>a = [1,2,3,4,5,6,7] >>>b = filter(lambda x: x > 5, a) >>>print b >>>[6,7]
b.map函数是对一个序列的每个项依次执行函数,下面是对一个序列每个项都乘以2
>>> a = map(lambda x:x*2,[1,2,3]) >>> list(a) [2, 4, 6]
c.reduce函数是对一个序列的每个项迭代调用函数,下面是求3的阶乘
>>> reduce(lambda x,y:x*y,range(1,4)) 6
23 Python里的拷贝
import copy a = [1, 2, 3, 4, ['a', 'b']] #原始对象 b = a #赋值,传对象的引用 c = copy.copy(a) #对象拷贝,浅拷贝 d = copy.deepcopy(a) #对象拷贝,深拷贝 a.append(5) #修改对象a a[4].append('c') #修改对象a中的['a', 'b']数组对象 print 'a = ', a print 'b = ', b print 'c = ', c print 'd = ', d 输出结果: a = [1, 2, 3, 4, ['a', 'b', 'c'], 5] b = [1, 2, 3, 4, ['a', 'b', 'c'], 5] c = [1, 2, 3, 4, ['a', 'b', 'c']] d = [1, 2, 3, 4, ['a', 'b']]
24 Python垃圾回收机制
https://www.cnblogs.com/wupeiqi/p/11507404.html
a 引用计数以及循环引用
就是当这个对象的引用计数值为 0 时,说明这个对象永不再用,自然它就变成了垃圾,需要被回收
引用计算增减
对象的引用计数增加的情况:
- 对象被创建:x = 3.14
- 另外的别名被创建:y = x
- 对象被作为参数传递给函数(新的本地引用):foobar(x)
- 对象成为容器对象的一个元素:myList = [123, x, 'xyz']
对象的引用计数减少的情况:
- 一个本地引用离开了其作用范围。如fooc()函数结束时,func函数中的局部变量(全局变量不会)
- 对象的别名被显式销毁:del y
- 对象的一个别名被赋值给其他对象:x = 123
- 对象被从一个窗口对象中移除:myList.remove(x)
- 窗口对象本身被销毁:del myList
Del语句会删除对象的一个引用,它的语法如下:del obj[, obj2[, ...objN]]
例如,在上例中执行del y会产生两个结果:
- 从现在的名称空间中删除y
- x的引用计数减1
循环应用
list1 = [] list2 = [] list1.append(list2) list2.append(list1)
list1与list2相互引用,如果不存在其他对象对它们的引用,list1与list2的引用计数也仍然为1,所占用的内存永远无法被回收,这将是致命的。
b 标记-清除机制
1.标记-清除机制,顾名思义,首先标记对象(垃圾检测),然后清除垃圾(垃圾回收)
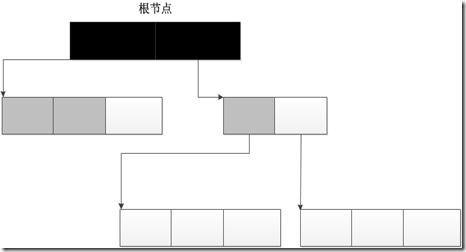
2首先初始所有对象标记为白色,并确定根节点对象(这些对象是不会被删除),标记它们为黑色(表示对象有效)。
3将有效对象引用的对象标记为灰色(表示对象可达,但它们所引用的对象还没检查),检查完灰色对象引用的对象后,将灰色标记为黑色。
4重复直到不存在灰色节点为止。最后白色结点都是需要清除的对象。
c 分代技术
对象存在时间越长,越可能不是垃圾,应该越少去收集。
为了更合理的进行【标记-删除】,就需要对对象进行分代处理,思路很简单:
1、新创建的对象做为0代
2、每执行一个【标记-删除】,存活的对象代数就+1
3、代数越高的对象(存活越持久的对象),进行【标记-删除】的时间间隔就越长。这个间隔,江湖人称阀值。
4、0代触发将清理所有三代,1代触发会清理1,2代,2代触发后只会清理自己。
25 Python的List
26 Python的is
is是对比地址,==是对比值
27 read,readline和readlines
- read 读取整个文件
- readline 读取下一行,使用生成器方法
- readlines 读取整个文件到一个迭代器以供我们遍历
28 Python2和3的区别
29 super init
30 range and xrange
range产生的是一个列表,而xrange产生的是一个类似迭代器的。
所以对于较大的集合时候,xrange比range性能好。
因为range一次把所以数据都返回,而xrange每次调用返回其中的一个值
31 请列举你熟悉的设计模式?
32 Python解释器种类以及特点
- CPython
- c语言开发的 使用最广的解释器
- IPython
- 基于cpython之上的一个交互式计时器 交互方式增强 功能和cpython一样
- PyPy
- 目标是执行效率 采用JIT技术 对python代码进行动态编译,提高执行效率
- JPython
- 运行在Java上的解释器 直接把python代码编译成Java字节码执行
- IronPython
- 运行在微软 .NET 平台上的解释器,把python编译成. NET 的字节码
本文来自博客园,作者:秋华,转载请注明原文链接:https://www.cnblogs.com/qiu-hua/p/12230218.html
