正则表达式(下)
正则表达式
作用二:在一段文本中查找满足要求的内容
本地爬虫和网络爬虫
这一段我仅仅使用案列进行演示
在此之前我们需要用到两个类:
pattern,他是属于java.util.regex.Pattern包下的类
用于定义正则表达式的典型的调用顺序是
Pattern p = Pattern.compile("a*b"); Matcher m = p.matcher("aaaaab"); boolean b = m.matches();
Matcher,文本匹配器,也是属于java.util.regex.Matcher包下的类,按照正则表达式的规则去读取字符串,从头开始读取。
话不多说开撸
-
本地爬虫
import java.util.regex.Matcher; import java.util.regex.Pattern; public class Demo2 { public static void main(String[] args) { //Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个是长期支持版本,下个长期 //支持的版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台 //要求:找到文本中JavaXX String str="Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个是长期支持版本," + "下个长期支持的版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台"; //获取正则表达式的对象 Pattern p=Pattern.compile("Java\\d{0,2}"); //获取文本匹配器的对象 //m:文本匹配的对象 //str:大串 //p:规则 //m要在str中找复合p规则的小串 Matcher m=p.matcher(str); //拿着文本匹配器从头开始读取,寻找是否右满足规则的子串 //如果没有,方法返回false //如果有,返回true,再记录子串的起始索引和结束索引+1 //为什么是+1呢,可以思考String截取字符串的方法subSring //boolean flag=m.find(); while (m.find()){ String s=m.group(); System.out.println(s); } } } -
网络爬虫
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Demo3 {
public static void main(String[] args) throws IOException {
/*需求:把下面网址中属于身份证的内容爬取出来
http://liaocheng.dzwww.com/lcxw/202009/t20200902_6516416.htm*/
URL url=new URL("http://liaocheng.dzwww.com/lcxw/202009/t20200902_6516416.htm");
URLConnection conn=url.openConnection();
BufferedReader br=new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line;
String regex="[1-9]\\d{17}";
Pattern pattern=Pattern.compile(regex);
while ((line=br.readLine())!=null){
System.out.println(line);
Matcher matcher= pattern.matcher(line);
while (matcher.find()){
System.out.println(matcher.group());
}
}
br.close();
}
}
这段代码不建议练习,因为网页编码问题
题目练习
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test1 {
public static void main(String[] args) {
/*需求:把下面文本中的电话,邮箱,手机号,热线都爬取出来。
* 来学习Java,
* 电话:15196768904 18881104189,
* 或者联系邮箱:zongjie@itcast.cn,
* 座机号码:01036517895,010-98951256
* 邮箱:bozai@itcast.cn,
* 热线电话:400-618-9090.400-618-4000,4006184000,4006189090
* */
//手机的正则:1[3-9]\\d{9}
//邮箱的正则: \\w+@[\\w&&[^_]]{2,6}(\.[a-zA-Z]{2,3}){1,2}
//座机的正则:0\\d{2,3}-?[1-9]\\d{4,9}
//热线的正则:400-?[1-9]\\d{2}-?[1-9]\\d{3}
String s="来学习Java,\n" +
"电话:15196768904 18881104189,\n" +
"或者联系邮箱:zongjie@itcast.cn,\n" +
"座机号码:01036517895,010-98951256\n" +
"邮箱:bozai@itcast.cn,\n" +
"热线电话:400-618-9090.400-618-4000,4006184000,4006189090";
String regex="(1[3-9]\\d{9})|(\\w+@[\\w&&[^_]]{2,6}(\\.[a-zA-Z]{2,3}){1,2})|(0\\d{2,3}-?[1-9]\\d{4,9})|(400-?[1-9]\\d{2}-?[1-9]\\d{3})";
//获取正则表达式的对象
Pattern p=Pattern.compile(regex);
//获取文本匹配器的对象
//用m取读取s,会按照p的规则找里面的小串
Matcher m=p.matcher(s);
//利用循环获取每一个数据
while (m.find()){
System.out.println(m.group());
}
}
}
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Demo4 {
public static void main(String[] args) {
//Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个是长期支持版本,下个长期
//支持的版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台
//需求1:爬取版本号为8,11,17的Java文本,但是只要Java,不显示版本号
//需求2:爬取版本号为8,11,17的Java文本,但是只要Java,显示版本号
//需求2:爬取除了版本号为8,11,17的Java文本
String s="Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个是长期支持版本,下个长期\n" +
"支持的版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
//1.书写正则表达式
//?理解为前面的数据Java
//=表示在Java后面要跟随的数据
//但是在获取的时候,只获取前半部分
//需求1
String regex1="((?i)Java)(?=8|7|11|17)";
//需求2
String regex2="((?i)Java)(8|7|11|17)";
//需求3
String regex3="((?i)Java)(?!8|7|11|17)";
Pattern p=Pattern.compile(regex3);
Matcher m=p.matcher(s);
while (m.find()){
System.out.println(m.group());
}
}
}
条件爬取
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Demo4 {
public static void main(String[] args) {
//Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个是长期支持版本,下个长期
//支持的版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台
//需求1:爬取版本号为8,11,17的Java文本,但是只要Java,不显示版本号
//需求2:爬取版本号为8,11,17的Java文本,但是只要Java,显示版本号
//需求2:爬取除了版本号为8,11,17的Java文本
String s="Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个是长期支持版本,下个长期\n" +
"支持的版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
//1.书写正则表达式
//?理解为前面的数据Java
//=表示在Java后面要跟随的数据
//但是在获取的时候,只获取前半部分
//需求1
String regex1="((?i)Java)(?=8|7|11|17)";
//需求2
String regex2="((?i)Java)(8|7|11|17)";
//需求3
String regex3="((?i)Java)(?!8|7|11|17)";
Pattern p=Pattern.compile(regex3);
Matcher m=p.matcher(s);
while (m.find()){
System.out.println(m.group());
}
}
}
贪婪爬取和非贪婪爬取
abbbbbbbbbbbbbbbbbb
贪婪爬取:ab+
非贪婪爬取:ab
Java中,默认的是贪婪爬取,如果我们在数量词+*后面加上问号,就是非贪婪爬取
识别正则的方法两个方法
方法名 说明
public String[] matches(String regex) 判断字符串是否满足正则表达式的规则
public String replaceAll(String regex,String newStr) 按照正则表达式的规则替换
public String[] split(String regex) 按照正则表达hi的规则切割字符串
演示
public class Demo5 {
public static void main(String[] args) {
//有一段字符串:小明dasdasdqwd小刚dfakfdhgui小智
//要求1:把字符串中三个姓名之间的字母替换为vs
//要求2:把字符串中的姓名切割出来
String s="小明dasdasdqwd小刚dfakfdhgui小智";
/*String result=s.replaceAll("[\\w&&[^_]]+","vs");
System.out.println(result);*/
String [] arr=s.split("[\\w&&[^_]]+");
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}
捕获和非捕获
分组
分组就是一个小括号,每组是有组号的,也就是序号
-
规则1:从1开始,连续不间断
-
规则2:以左括号为基准,最左边是第一组,其次是第二组,依次类推
(\\d+)(\\d+)(\\d)
(\\d+(\\d+))(\\d)
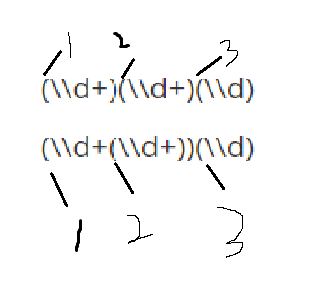
public class Demo6 {
public static void main(String[] args) {
//捕获分组的练习
//捕获分组就是把这一组的数据捕获出来,再用一次
//需求1:判断一个字符串的开始字符和结束字符是否一致,只考虑一个字符
//举例:a123a b4556b 12314
//拆分成三部分,第一部分是任意字符(.),第二部分也是任意的多个.+,第三部分就复用第一组的//1
String regex1="(.).+\\1";
System.out.println("a123a".matches(regex1));
System.out.println("b4556b".matches(regex1));
System.out.println("12314".matches(regex1));
//需求2:判断一个字符串的开始字符和结束字符是否一致,可以有多个字符
//举例:abc123abc bc4556bc 12314
String regex2="(.+).+\\1";
System.out.println("abc123abc".matches(regex2));
System.out.println("bc4556bc".matches(regex2));
System.out.println("12314".matches(regex2));
//需求3:判断一个字符串的开始字符和结束字符是否一致,开始部分内部每个字符也需要一致
//举例:abc1212abc bc4556bc 123123
String regex3="(.+)\\1";
System.out.println("abc1212abc".matches(regex3));
System.out.println("bc4556bc".matches(regex3));
System.out.println("123123".matches(regex3));
}
}
public class Demo7 {
public static void main(String[] args) {
//题目:解决口吃
//将字符串:我要学学学编编编编编编编程程程程程程
//改为:我要学编程
String str="我要学学学编编编编编编编程程程程程程";
//分析replaceAll()方法作用就是替换掉正则表达式的内容
//(.)\1+ +代表至少一次
//$1 表示把正则表达式中的第一组的内容,再拿出来用
String new_str= str.replaceAll("(.)\\1+","$1");
System.out.println(new_str);
}
}
小结
-
组号的特点:即上文规则
-
捕获分组:
如果后续还要使用本组的数据
正则内部使用:\\组号
正则外部是同:$组号
-
非捕获分组
分组之后不需要再使用本组数据,仅仅是把数据括起来
符号 含义 举例
(?:正则) 获取所有 Java(?:8|11|17)
(?=正则) 获取前面部分 Java(?=8|11|17)
(?!正则) 获取不是指定内容的前面部分 Java(?!8|11|17)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号