
[论文][表情识别]LANDMARK GUIDANCE INDEPENDENT SPATIO-CHANNEL ATTENTION AND COMPLEMENTARY CONTEXT INFORMATION BASED FACIAL EXPRESSION RECOGNITION
论文基本情况
发表时间及刊物/会议:2021 Pattern Recognition Letters (PRL)
发表单位:萨西萨伊高等学院 (Sri Sathya Sai Institute of Higher Learning)
问题背景
(1)遮挡和姿态变化是表情识别需要解决的两大难题
(2)landmark的获取依赖外部检测,landmark的检测错误会会进一步影响网络模型的性能。
(3)输入特征的相关性体现不明显???
论文创新点
本文提出了一种用于FER的端到端架构,该架构通过一种新的空间通道注意网(SCAN)获得每个空间位置的每个通道的局部和全局注意,而无需从地标检测器中寻找任何信息。SCAN由补充上下文信息(CCI)分支进行补充。此外,使用有效通道注意(ECA),还关注了特征输入对CCI的相关性。所提出的结构学习到的表示对遮挡和姿势变化具有鲁棒性。
网络结构
Motivate
通常,我们使用以下三种注意力机制来解决遮挡和姿态变化的问题,但这些注意力机制通常要么在不同通道和空间上都取恒定的权重,要么在不同通道上取恒定的权重,要么在不同空间位置上取恒定的权重。
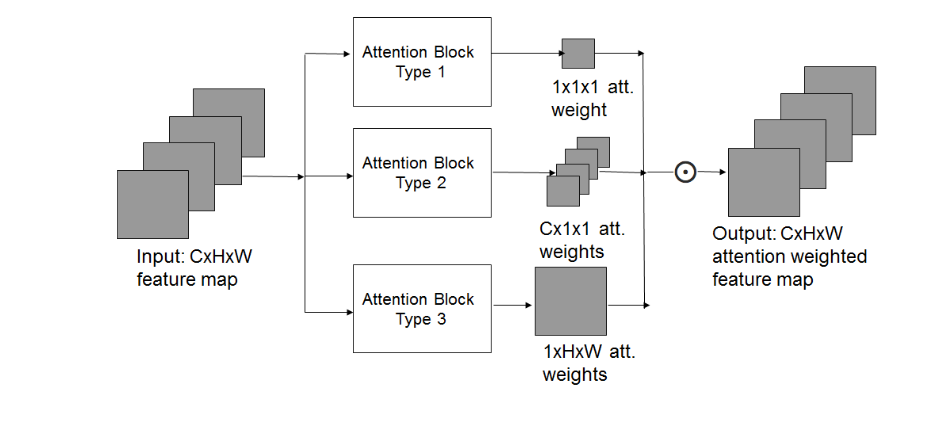
但是我们发现,如果对一张普通图片加上遮挡,不同通道,空间位置的权重因为此遮挡产生的变化不一致,比如如下图片,展示了遮挡前后不同通道,空间位置权重的变化情况,由此看出,有的通道,位置因为遮挡而发生了较大变化,但有的通道,位置则几乎未发生变化。

SCAN
因此,我们提出了在不同通道,不同空间位置权重都不一样的注意力机制SCAN,其中\(P,WP\)分别为输入,输出,均为维度是\(C \times H \times W\)的特征向量,
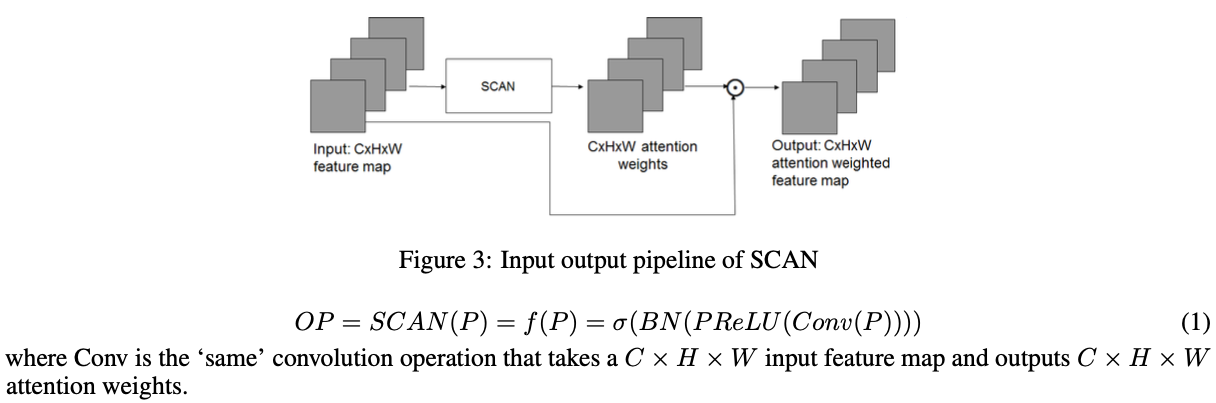
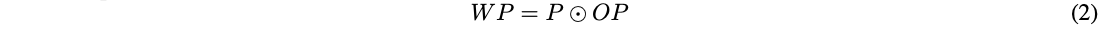
其中\(\bigodot\)为元素点乘。
Complementary Context Information (CCI) Branch
考虑到当前表情识别的权重是迁移自人脸识别,则中间层主要提取不同人脸特征,比如鼻子,眼睛,嘴巴等,最后一层主要的提取身份信息。对于表情识别任务而言,身份信息对于判断表情类型意义不大,而部分中间层特征,如鼻子的特征同样不适用表情识别任务,因此,表情识别任务一般而言舍弃最后一层的预训练权重,而对于中间层特征,我们希望通过注意力机制,给予重要的特征,如嘴巴,眉毛等更大的权重,而给予不重要的特征,如鼻子等,更小的权重。此处,我们采用ECA注意力机制使得不同通道之间的权重相互交互。【作者认为此处是为了给SCAN分支提供补充信息,因此不使用SCAN类型的注意力机制(个人感觉这个理由略牵强)】
CCI分支的公式如下:

其中\(F\)为输入的中间层特征图。
最后,CCI分支会得到K个特征向量,这K个特征向量分别连接不同的全连接层并进行分类,分别计算交叉熵损失,并求和,得到CCI分支的最终损失:
网络的整体框架如下所示:
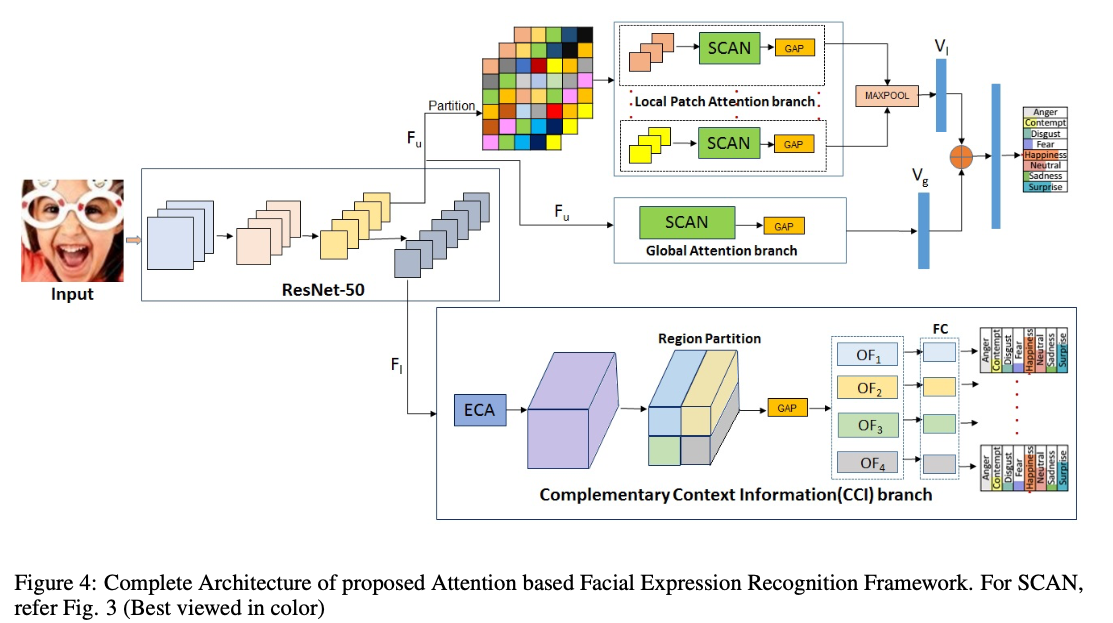
特别的,对于主分支SCAN,我们将原始特征图\(F\)划分为m个不重叠的patch(本文中m取25,具体划分为16个6×6的,4个6×4的,4个4×6的,1和4×4的patch),这些patch分别通过SCAN注意力模块,得到m个输出特征。这m个输出特征首先分别经过跨空间位置的全局平均池化,再统一进行跨通道的最大池化,得到图中\(V_I\)。
另外,我们将\(F\)直接送入\(SCAN\)并进行全局平均池化,得到\(V_g\),最后,我们将\(V_g\)和\(V_I\)进行通道拼接,得到最终的特征向量,进行分类,计算交叉熵损失,此损失记为\(L_u\)。
整个网络的总损失为两个分支的加权平均:
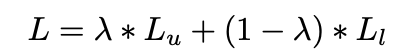
其中,由后文消融实验可知,\(\lambda=0.2\)最佳。
实验
表1 我们的模型和baseline的比较
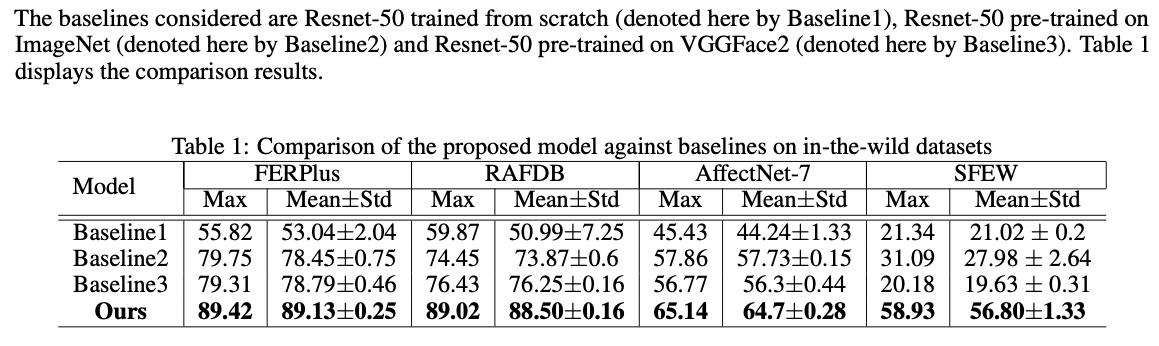
表2 我们的模型和其他优秀模型比较
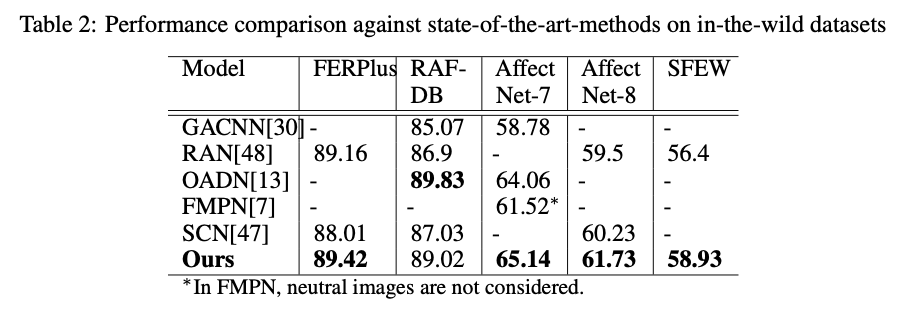
表3 我们的模型在处理含遮挡以及姿态变化的数据集子集上得到结果(此子集由RAN划分)

表4 我们的模型在真实姿态遮挡数据集FED-RO上和其他优秀模型的比较
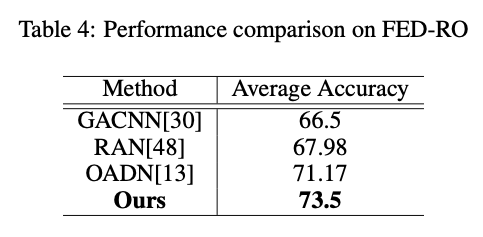
图5 混淆矩阵
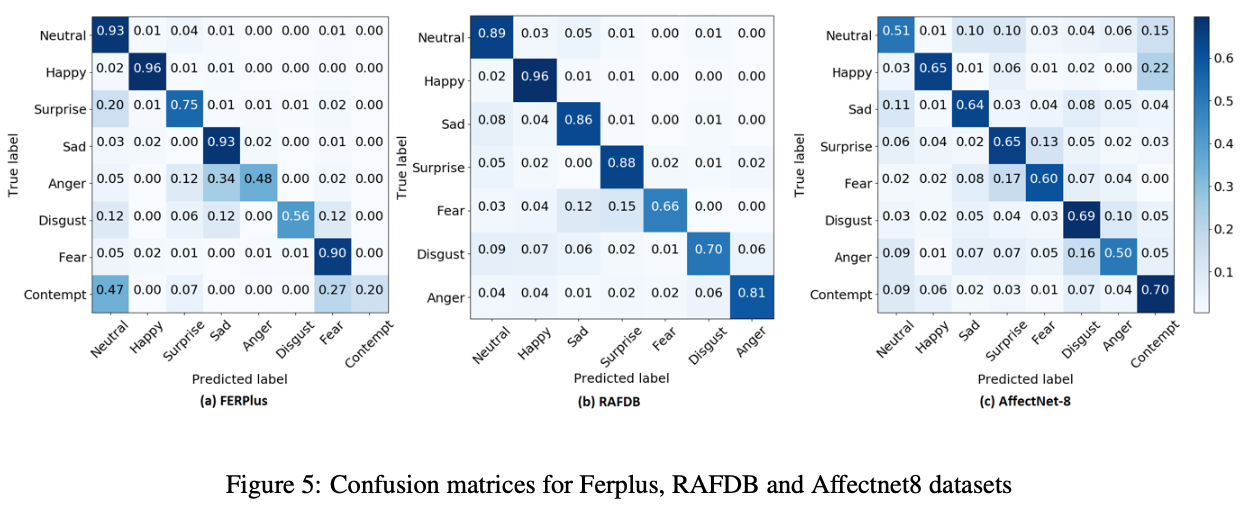
表5 模型在in-lab数据集上的表现
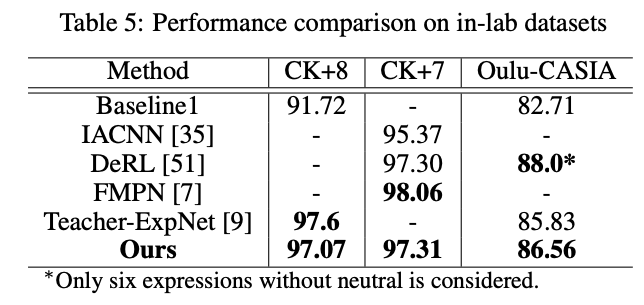
表6 交叉测评实验(在AffectNet 7类表情上进行训练,并在以下数据集上测试)
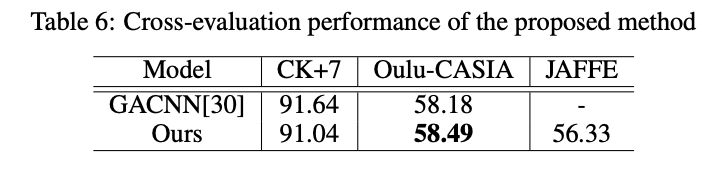
表7 SCAN作用和其他注意力机制的比较
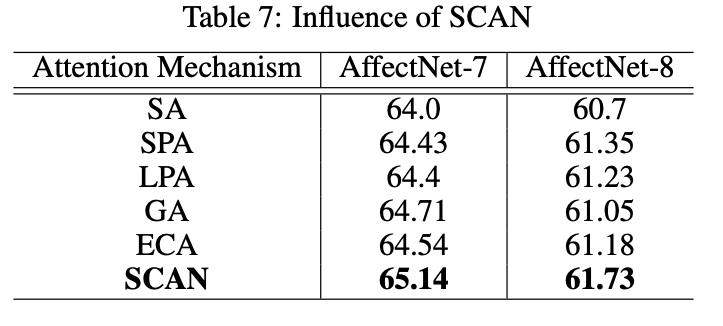
表8 CCI分支的消融实验
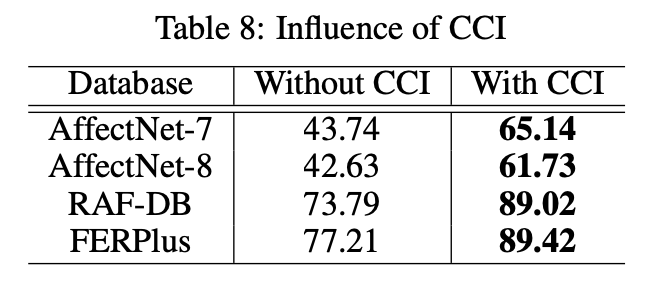
表9 CCI分支中ECP通道注意力机制的消融实验

表10 考虑到新冠病毒的影响,我们使用了公开的源代码,从RAF-DB和FerPlus数据集构造出戴口罩的对应数据集,得到了以下结果

表11 SCAN分支中,当所有的local patch 共享SCAN注意力机制中的参数,使得模型更为轻量。由结果可知,除了RAF-DB数据集精度略微提高外,其他数据集精度略微下降。

图7 关于SCAN分支划分多少个patch的消融实验
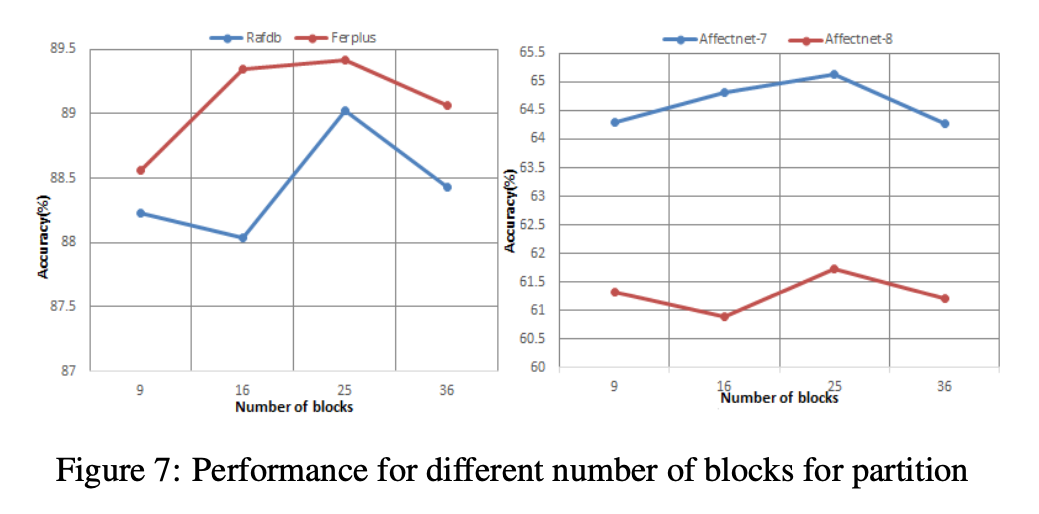
图8 关于损失函数中\(\lambda\)权重的消融实验
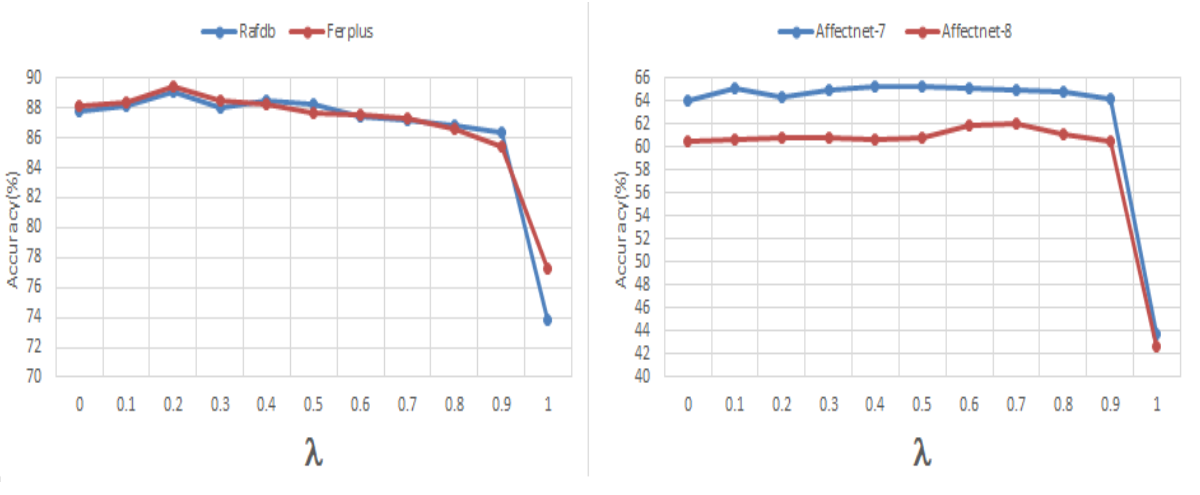
图9 可视化结果 使用Grad-CAM对特征图结果进行可视化
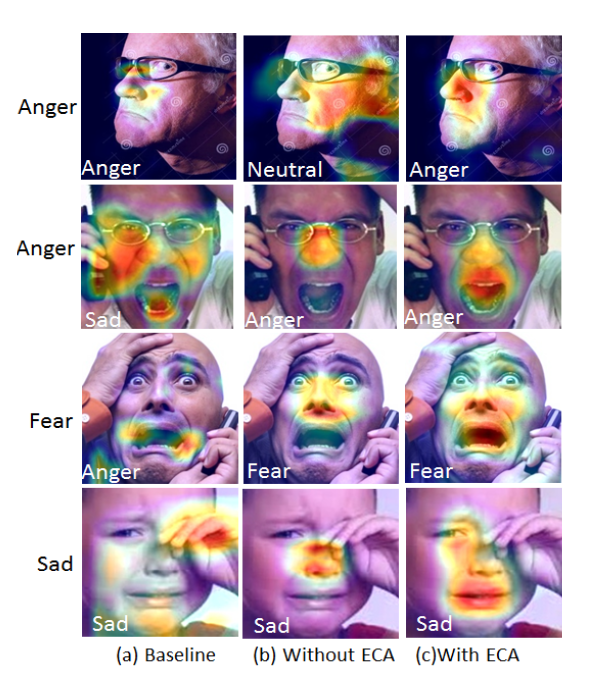
图10 可视化结果 预测错误的图片,使用Grad-CAM对特征图结果进行可视化


 浙公网安备 33010602011771号
浙公网安备 33010602011771号