
[论文][表情识别]Region Attention Networks for Pose and Occlusion Robust Facial Expression Recognition
论文基本情况
发表时间及刊物/会议: 2019 TIP
问题背景
遮挡和姿态变化是表情识别需要解决的两大难题,但是目前没有关于姿态变换和遮挡的表情识别数据集。
论文创新点
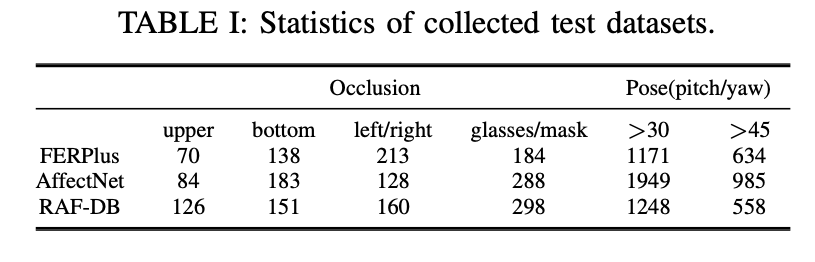
(1)在现有的表情识别数据集选取了涉及姿态变化和遮挡的图片,并标注了遮挡类型以及姿态变化角度。具体来说,论文选取了RAF-DB,FerPlus,AffectNet三个数据集的测试集,每个数据集分别抽取了部分含遮挡,姿态变化>30度,姿态变化>45度三种类型的图片,分别形成了三种测试集。
(2)搭建Region Attention Network (RAN)网络模型,来获取姿态变化或遮挡表情中的重要区域。
(3)提出region biased loss(RB loss)鼓励网络给重要区域更高的权重。
网络结构
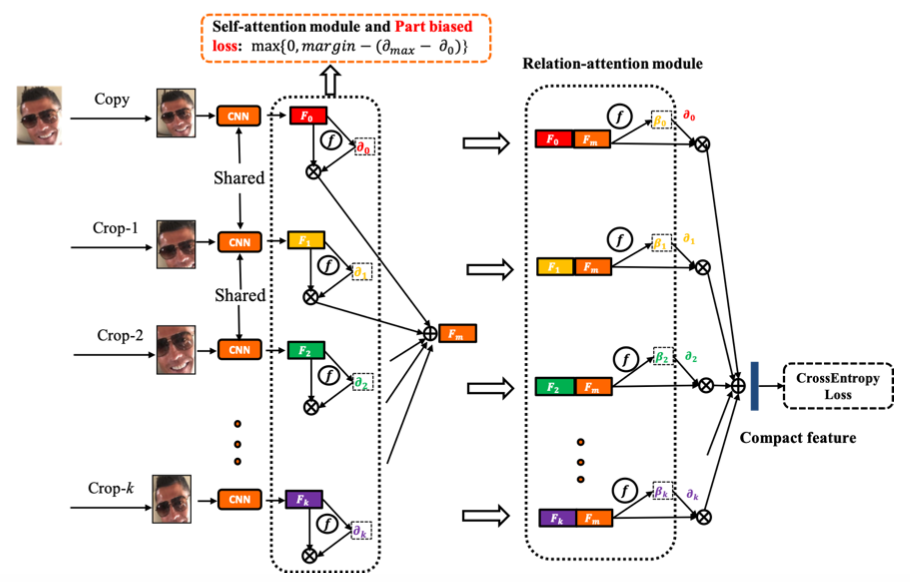
RAN主要包含三个部分:
(1)裁剪和特征提取模块
(2)自注意力模块
(3)relation-attention模块
裁剪和特征提取模块
通过固定位置裁剪、随机裁剪、基于人脸特征点等方法裁剪出张图片,和原图一起共张图片,一起送入同一个CNN网络进行特征提取。
- 对于固定裁剪,RAN共裁剪5张图片。分别以左上角,右上角为顶点,以中心偏下位置为中心,0.75为比例,裁剪出三张图片;以原图中心为中心,分别以0.9, 0.85为比例,裁剪出另外两张图片。
- 对于随机裁剪,RAN共裁剪个区域,每张图片的裁剪比例为0.7~0.95。
- 对于基于landmark的裁剪,RAN使用MTCNN检测每个人脸图像的五个特征点,以特征点中心为中心,以为半径,裁剪出张图片。
注:本文的默认实验设置为固定裁剪。
原图以及裁剪后的图片分别送入同一个CNN网络,得到对应的特征,原图的特征集合为公式中的
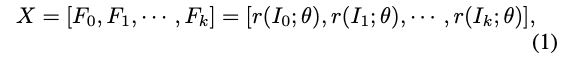
自注意力模块
RAN使用ResNet18作为backbone,并将ResNet18在最后全连接层之前提取到的特征送入 self-attention 模块。公式(2)中的表示第张图片在全连接层之前的特征,分别表示sigmoid激活函数和注意力机制中全连接层的参数 。表示得到的注意力权重。

通过子注意力模块,我们让更重要的裁剪区域对应的权重更高。而通过公式(3)我们让同一张图片对应的多个特征根据权重进行加权平均,计算出全局特征。
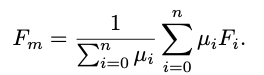
为了进一步增强特征区域的特征,本文应用了region biased loss(RB loss),RB loss希望各种不同的裁剪中,应该至少有一张裁剪图片能够比原图更加凸显表情特征,获取到更高的权重,因此,RB loss中设置阈值,希望注意力权重最高的裁剪图片对应的权重和原图相比超出一定阈值。
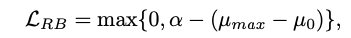
通过下图,可以看出RB loss的作用

Relation-attention module
关系注意力模块进一步增强特征,通过将backbone提出的初始特征和自注意力模块得到的加权平均特征进行矩阵拼接,之后再送入关系注意力模块的全连接层提取特征,最后经过sigmoid激活函数得到加强特征
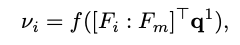
RAN网络最终的输出如下:
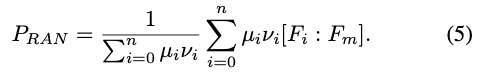
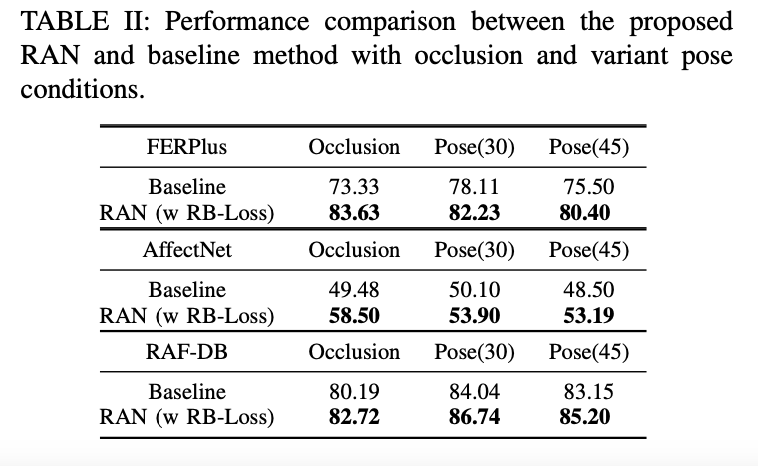
实验
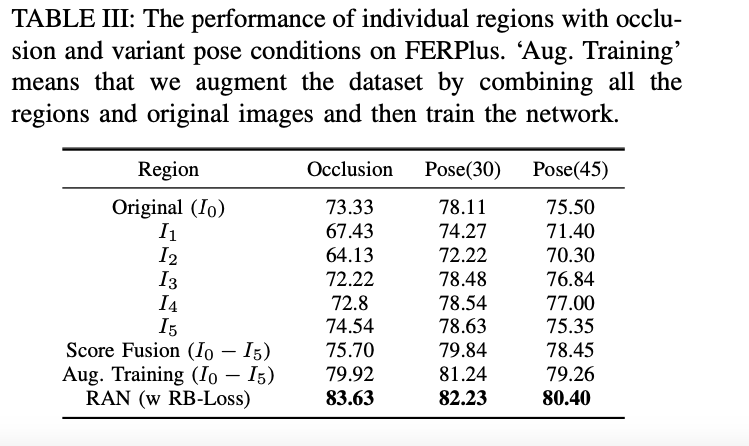
- RAN在含有遮挡,姿态变化的数据集上的测试结果。
- 不同裁剪区域、不同融合方式对实验结果的影响
3.网络结构中不同模块,以及人脸是否对齐对实验结果的影响



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!