
[论文][人脸算法]Semi-supervised Emotion Recognition using Inconsistently Annotated Data
研究背景
表情识别遇到的问题:
a)缺少充足的数据
b)表情过于细微,难以辨别
c)主观的,不一致的标签
d)自然条件下的数据包含姿态,强度,遮挡方面的变化
解决方法:基于self-training 的半监督的CNN网络结构
网络结构
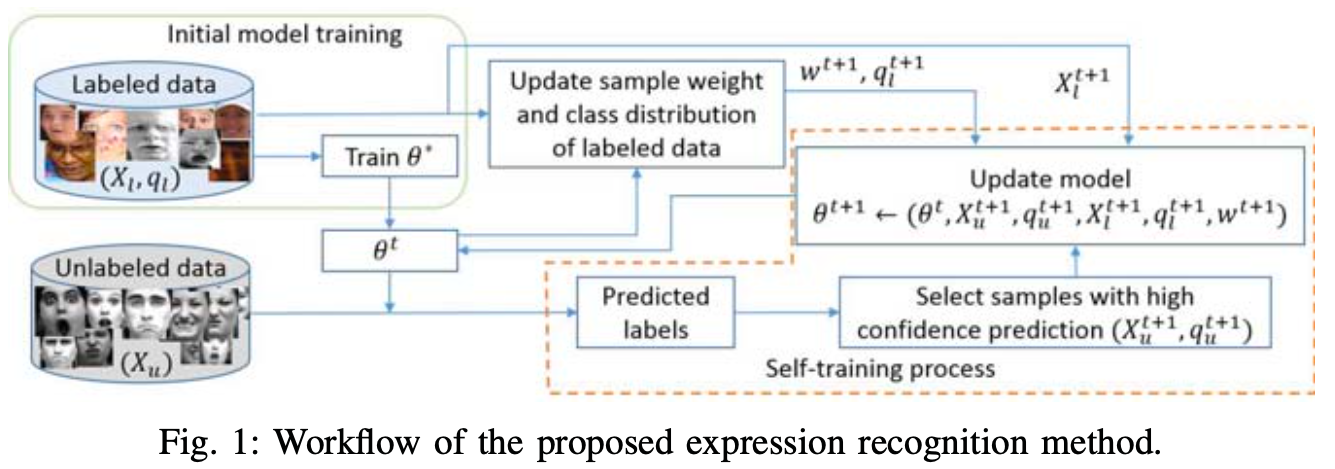
具体分为四个部分:模型初始训练、使用无标签的数据更新网络参数、标签更新、样本重要性分配
模型初始训练 Initial Model Training
对于有标签的数据,使用分类交叉熵损失来更新模型的参数,直到模型的表现达到一定水平(有标签的数据有限,在此有限数据集的条件下的最好模型性能)
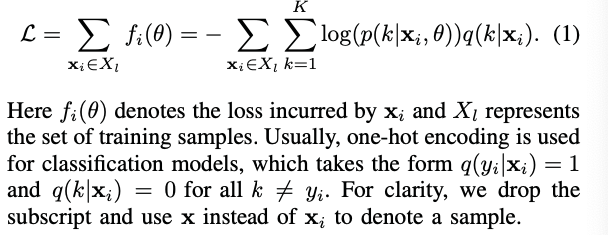
按照one-hot标签训练模型容易造成过拟合,由此改变策略,使用label smoothing,即使用 smooth 分布代替one-hot标签,具体方法如下:

使用无标签的数据更新网络参数 Exploiting Unlabeled Data for Model Update
在使用有标签数据对模型初始化之后,我们将无标签数据放入网络,产生对应的伪标签,注意,我们使用softmax后得到的概率分布作为gt,而不是使用one-hot标签作为gt。在得到的伪标签中,我们选取高置信度的标签(作为真值)和对应样本加入训练集。此时,我们使用有标签数据 和少量(为避免过拟合???)高置信度的伪标签数据进行训练。
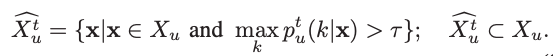
其中,闸值在0.7-0.95之间
在self training过程中,保持有标签数据和无标签数据的数量平衡十分关键,一般可以选取90%有标签和10%无标签数据
标签更新 label update
我们需要对有标签数据的gt分布进行谨慎的修改以适应不同强度的表情。
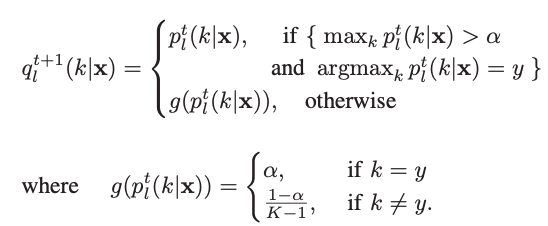
当有标签数据预测正确且最高置信度大于闸值时,使用原标签;否则,使用新的、平滑后的标签。
样本重要性分配 Assigning Sample Importance
部分有标签的数据所用标签是错误的,不利于模型的训练,由此,我们给每个有标签样本分配一个重要性的权重,同时,我们假所有高置信度的伪标签都是正确的,因此不给予惩罚。
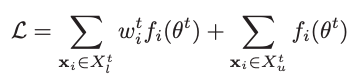

当单个样本的loss大于平均loss时,w变小,反之,w变大。最后,为了减少计算量,我们取weight范围为[0,1]
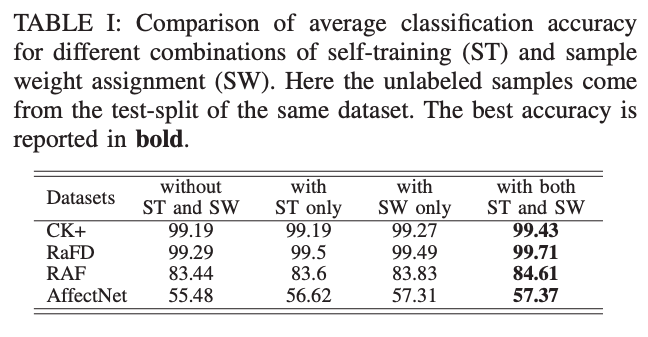
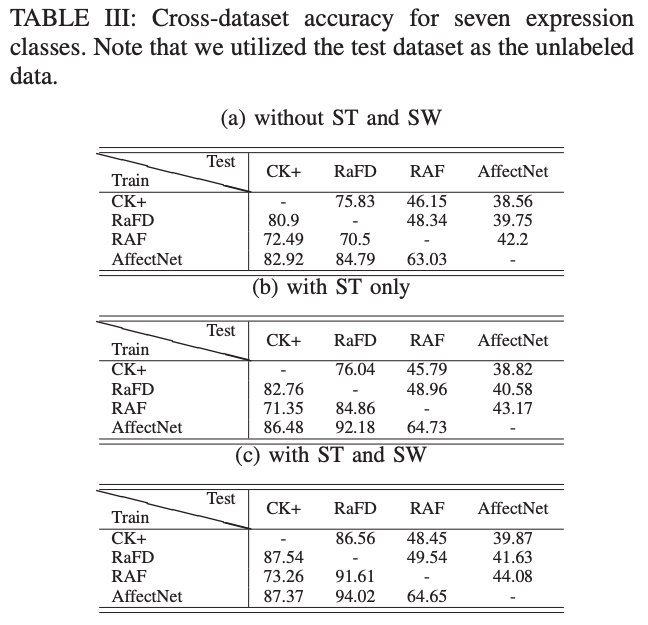
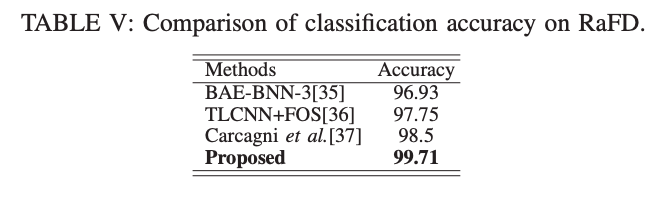
实验


 浙公网安备 33010602011771号
浙公网安备 33010602011771号