
[论文][人脸算法]Boosting Facial Expression Recognition by A Semi-Supervised Progressive Teacher
Motivation
在表情识别中,标注质量高的数据集数据量小,容易造成过拟合;数据量大的数据集标注质量不佳,含噪声,不利于模型的学习。如下图,为表情识别中最大的数据集之一AffectNet中错误标签。我们提出Progressive Teacher 用于同时解决缺少高质量标注数据和大数据集标注含噪声两个问题。

网络架构
Progressive Teacher是一个典型的老师-学生网络,即学生网络在老师网络的指导下逐步提升。一般而言,在训练过程中,老师网络的权重是学生网络的参数变化的平均,并且有着更好的表现,我们希望学生网络的分类误差尽可能小(对于有标签的数据,通过和标签对比计算损失)并且老师模型的输出的结果一致(无标签和有标签的数据都可以通过这个方式来约束)。
Progressive Teacher模型相比传统的老师-学生模型,不仅可以提供更好的结果并引导学生网络产生相同的结果(是一种半监督的典型方法,可以解决标注数据少的问题),还可以为学生模型选择潜在的干净样本学习(可以解决标注数据含噪声的问题)。
具体方法:
我们使用了两组学生老师模型。两组模型的结构相同,但参数的初始化不同。在两组模型中,学生和老师网络使用不同的数据增强方法,同时,学生网络通过SGD优化器进行优化,老师网络的权重是学生权重的指数平均移动。
由于不同的初始化,在训练的早期阶段,它们会给对方不同的samples(所学内容有区别?),老师网络则将这些区别积累放大。同时,老师网络会选择分类交叉熵损失更小的样本作为干净样本(具体的选择比例由R(t)表示,且该比例随着训练的过程变化),给学生网络学习。
两组模型采用交叉训练机制,例如:第一组老师网络会把筛选出的干净样本传递给第二组学生网络,第二组学生网络则会计算出监督的分类损失(交叉熵损失)和非监督的一致性损失(MSE损失)。
监督损失:
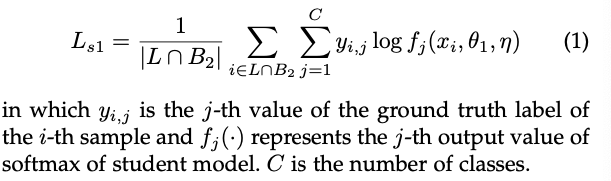
非监督损失:
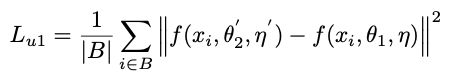
总损失:
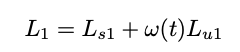
其中 w(t)是一个ramp-up函数,确保在训练的初始阶段,由于老师模型的引导能力有限,所以给非监督损失的权重较小。
在权重更新的过程中,老师网络的参数随着学生网络的参数按照如下方式变化:
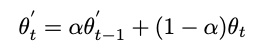

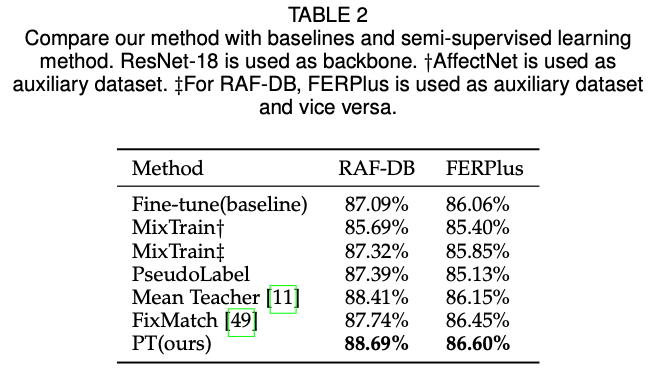
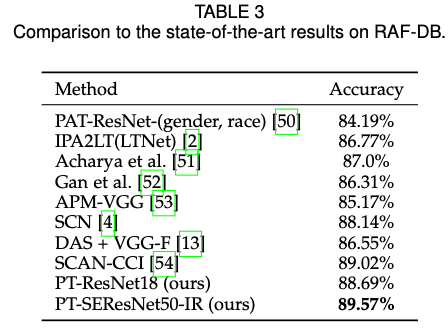
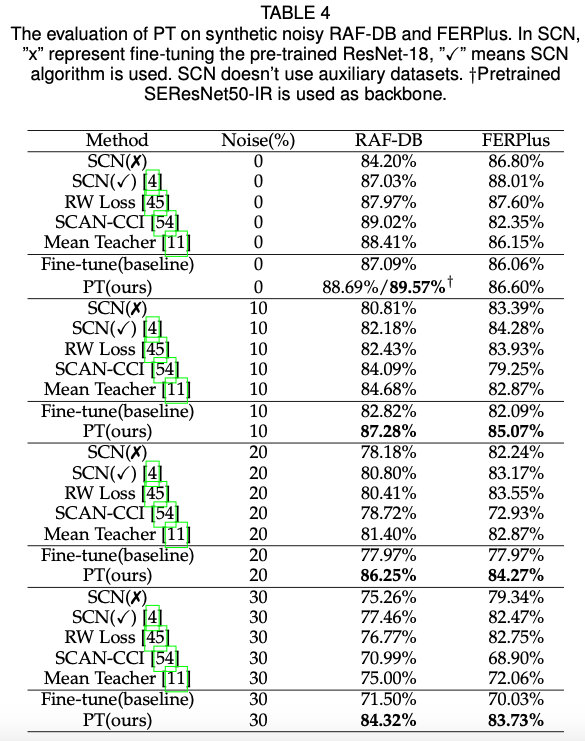
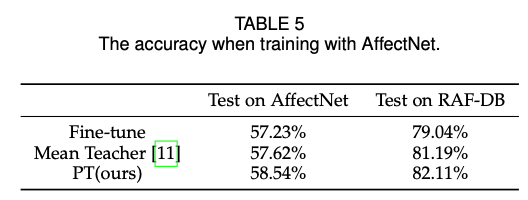
实验
使用RAF-DB数据集作为高质量标准的数据集,使用AffectNet作为补充的无标签数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号