
[论文][半监督语义分割]Semi-supervised Semantic Segmentation with Directional Context-aware Consistency
Semi-supervised Semantic Segmentation with Directional Context-aware Consistency
收录于CVPR2021 原文
Motivation
一致性在半监督语义分割中发挥了重大作用,一般意义上的一致性是通过约束弱数据增强方式(高斯模糊,色彩变化,翻转,旋转)的分割结果相同实现的,但是这种低层面的一致性约束是考虑了像素级别的一致性,而忽略了语义级别(高层级)的一致性。如果网络只具有像素层面的低级特征,则网络的泛化性较差。(容易对少量有标签数据过拟合),因此保存同样特征在不同场景下的一致性十分关键。
网络结构
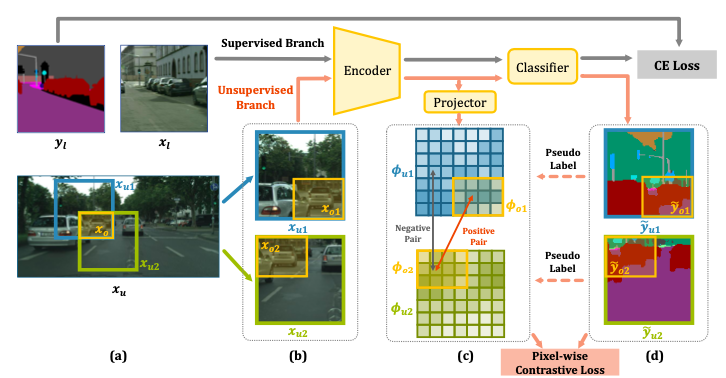
对于有标签数据,和传统方法完全相同,先进入encoder得到特征,再经过分类器得到分割结果,最后和标签计算交叉熵损失,更新网络参数。
对于无标签数据,有重叠的裁剪同一张图的不同部分,分别为Xu1和Xu2,重叠部分为Xo。Xu1中的Xo为Xo1,Xu2中的Xo为Xo2。
Xu1和Xu2分别进入Encoder和Projector,得到(c),(c)中positive sample表示两个同样位置的像素,但在不同的上下文中,因此分类结果相同;negative sample表示两个在原图中不同位置的像素。由此,我们设计了DC loss来计算损失,DCloss分别考虑了正样本和负样本进行计算,如下所示
DC loss
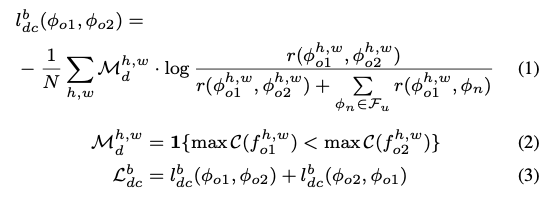


对于第b张无标签图片,DC loss由两个部分组成,即上下两个分支相互约束,分别计算损失。 (1)(2)列举了下分支对上分支的约束,C代表分类器,h,w表示2D图片像素点位置,对于一个特定像素点,只有当下分支的softmax后概率最大的类别的概率值大于上分支的对应值,才使用下分支结果作为约束。由此避免下分支的不准确预测结果对上分支产生影响(我们简单的认为softmax后概率最大的类别的概率值越大,此像素点的预测越准确)。
DCloss进一步改进:过滤正样本
为了进一步避免错误标签的影响,我们不仅要求使用下分支的softmax后概率最大的类别的概率值大于上分支的对应值,才使用下分支结果作为约束(如上所述),同时要求下分支的softmax后概率最大的类别的概率值需要大于某个闸值。
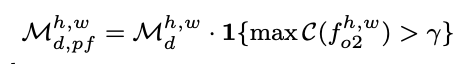
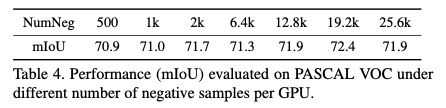
negative sample采样策略
negative sample 指不同类别的像素,我们不能简单的通过随机选取不同位置的像素作为负样本,因为语义分割中不同位置的像素完全可能属于同一个类别,特别是对于天空等尺寸较大的类别。
为避免上述情况,我们首先通过encoder和分类器得到无标签图片的预测结果,作为伪标签,使用伪标签中不同类别的像素对作为负样本。

总损失函数:
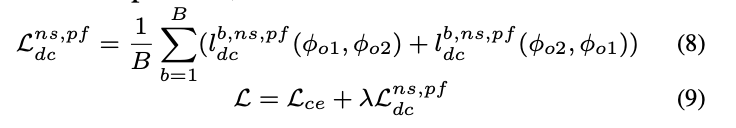
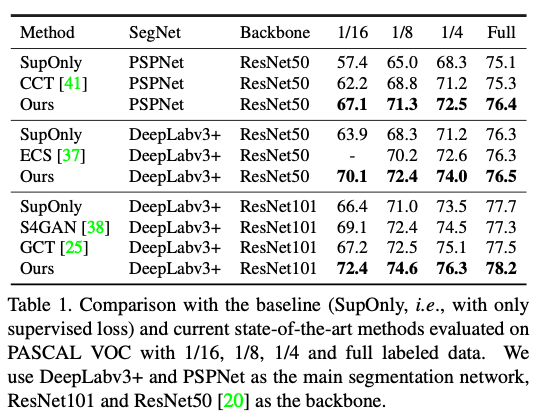
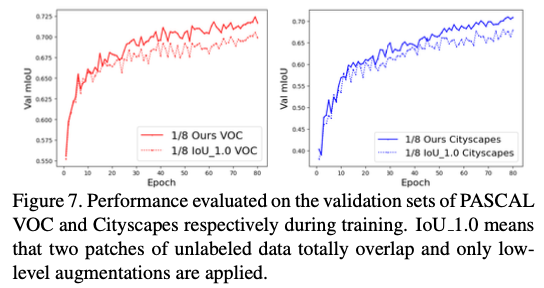
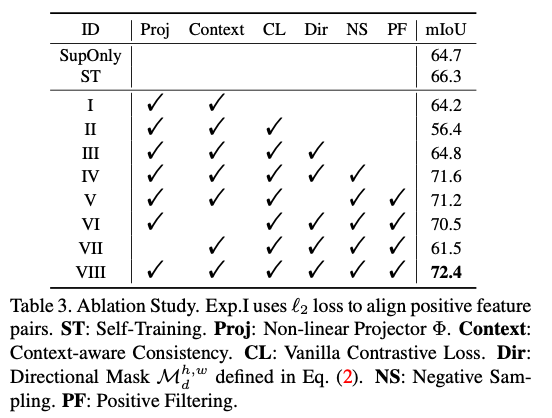
实验



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!