
[论文][半监督语义分割]Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
CVPR2021 原文
半监督语义分割方法的总结:
主要思想: Consistency regularization :希望不同扰动之下网络的输出结果一致,扰动的加入的位置:(1)在输入图片上加扰动(2)在某一层的输出特征上添加扰动
创新点:
- 鼓励两个初始化不同(不同扰动)的网络的一致性
- 利用半监督的方式相当于扩充了数据集
网络结构
两个网络的结构相同,但使用不同的初始化(作为不同的扰动),具体而言,2个网络backbone部分使用同样的ImageNet预训练权重,Segmentation Head部分使用不同的随机初始化权重。
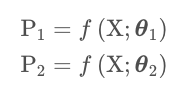

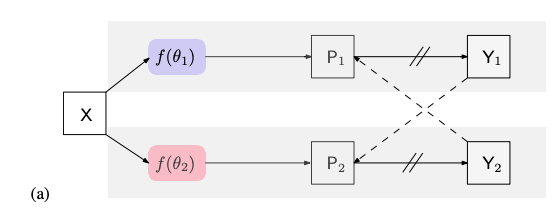
上图中的Y1和Y2分别表示2个网络输出的one hot标签,⟶ 表示前向计算,− − → 表示监督信息的传播,//表示不进行梯度计算。
对于无标签数据:
将上分支网络one-hot结果作为label监督下分支,下分支网络one-hot结果作为label监督上分支,计算一致性损失:
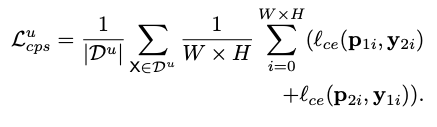
对于有标签数据:
将带标签的数据输入2个网络,使用ground truth分别监督这2个网络进行训练。用交叉熵函数计算损失
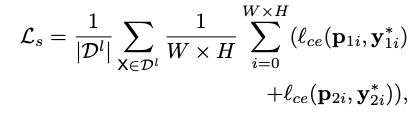
同时,也计算一致性损失(方式和无标签数据相同)
总网络的一致性损失分为有标签和无标签两种:
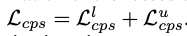
总网络损失:
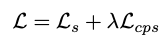
多种网络结构对比
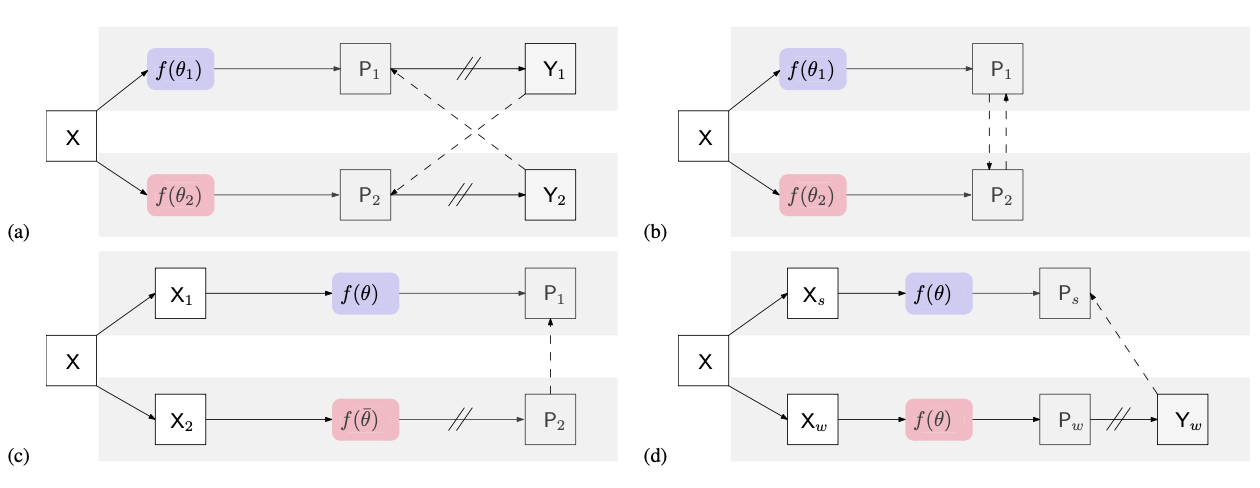
a) 本论文网络结构图CPS,叙述如上
b) GCT网络结构图,和本方法相同,唯一的区别在于GCT使用confidence map作为监督信号,而CPS使用one-hot label
c)MeanTeacher 使用学生网络和老师网络,两个网络结构相同,参数初始化不同,学生网络用老师网络得到的confidence map作为监督信号,老师网络随着学生网络的权重变化按照指数平均不断变化
d)一张原图X分别经过弱数据增强和强数据增强放入同一个网络中,弱数据增强所得one hot结果作为强数据增强结果的真值,用于监督弱数据增强的结果
实验
a,b图分别使用ResNet50,ResNet101作为backbone
蓝:baseline(不加入cutmix数据增强):只使用有标签的数据
红:使用两个网络,半监督学习,不加入cutmix数据增强
绿:使用两个网络,半监督学习,加入cutmix数据增强
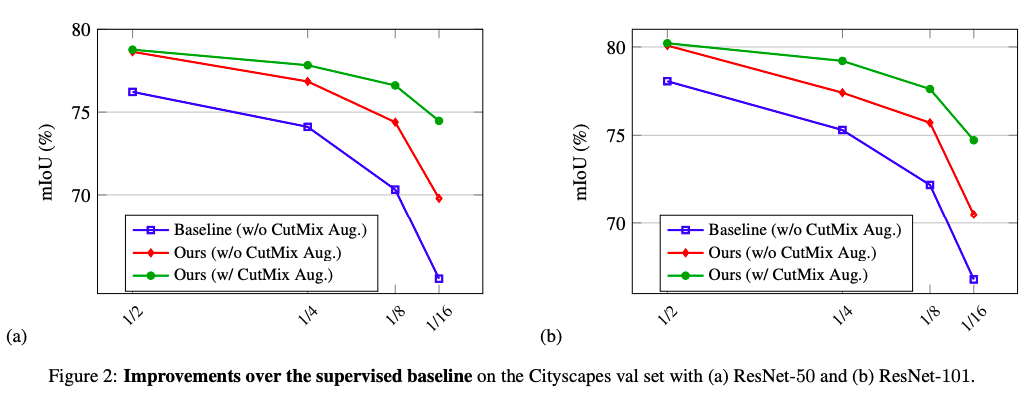
Table1:在Pascal VOC上使用不同backbone和不同有标签数据比例得到结果和其他SOTA方法对比
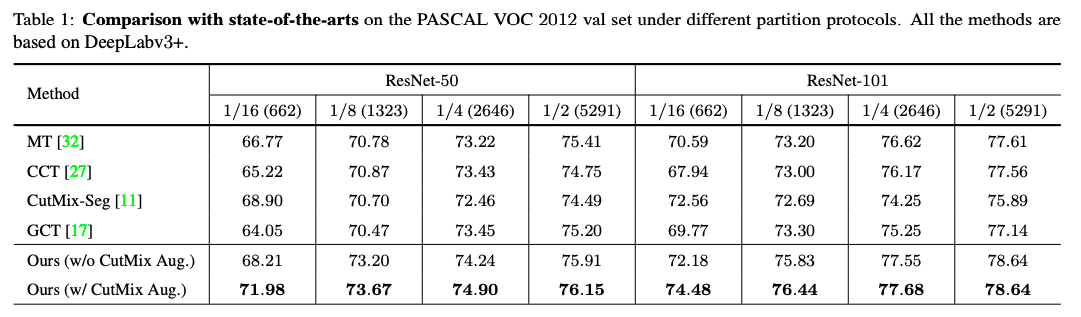
Table1:在Cityscapes上使用不同backbone和不同有标签数据比例得到结果和其他SOTA方法对比
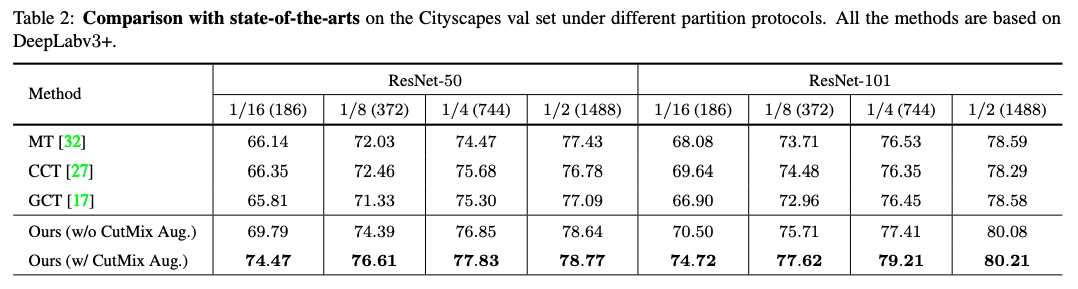
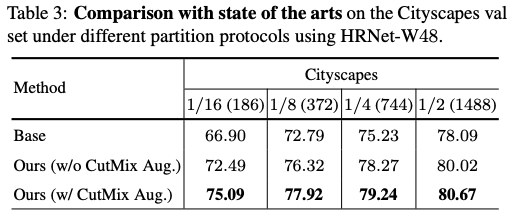
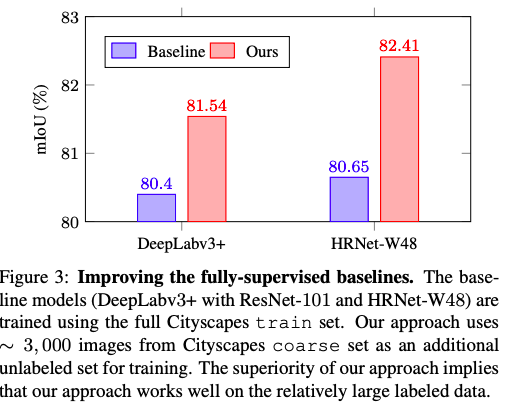
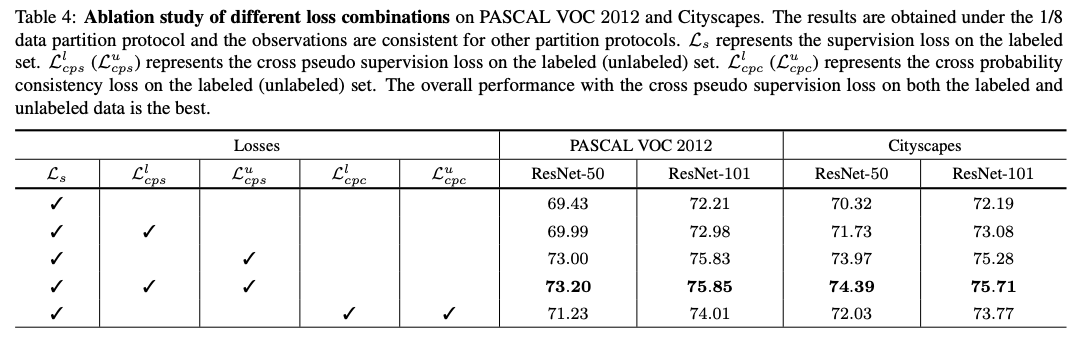
在两个数据集上分别进行的消融实验,损失函数的各部分对于结果的影响
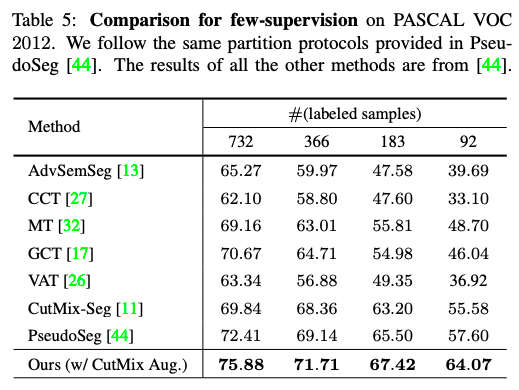
使用极少的有标签数据实验结果


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!