
[深度学习理论]通俗理解BatchNormalization
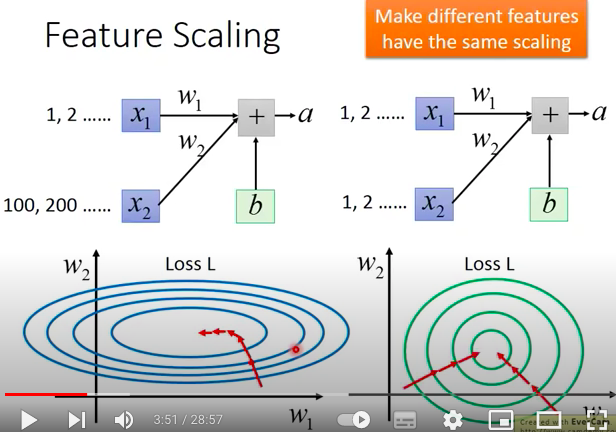
如图所示,对于一层神经网络来说,当神经元\(X_2\)的range远远大于\(X_1\)时,加权后得到的输出\(a\)会极大的收到神经元\(W_2*X_2\)的影响,即\(W_2\)的大小会极大的影响loss的大小,如下图左图所示。由此,为了使得loss变小,收敛,我们需要在不同方向(权重)上应用不同学习率大小,更新参数,这样难以做到。因此,我们选择Feature Scaling,让不同的feature有相同的scaling,即如下面右图所示
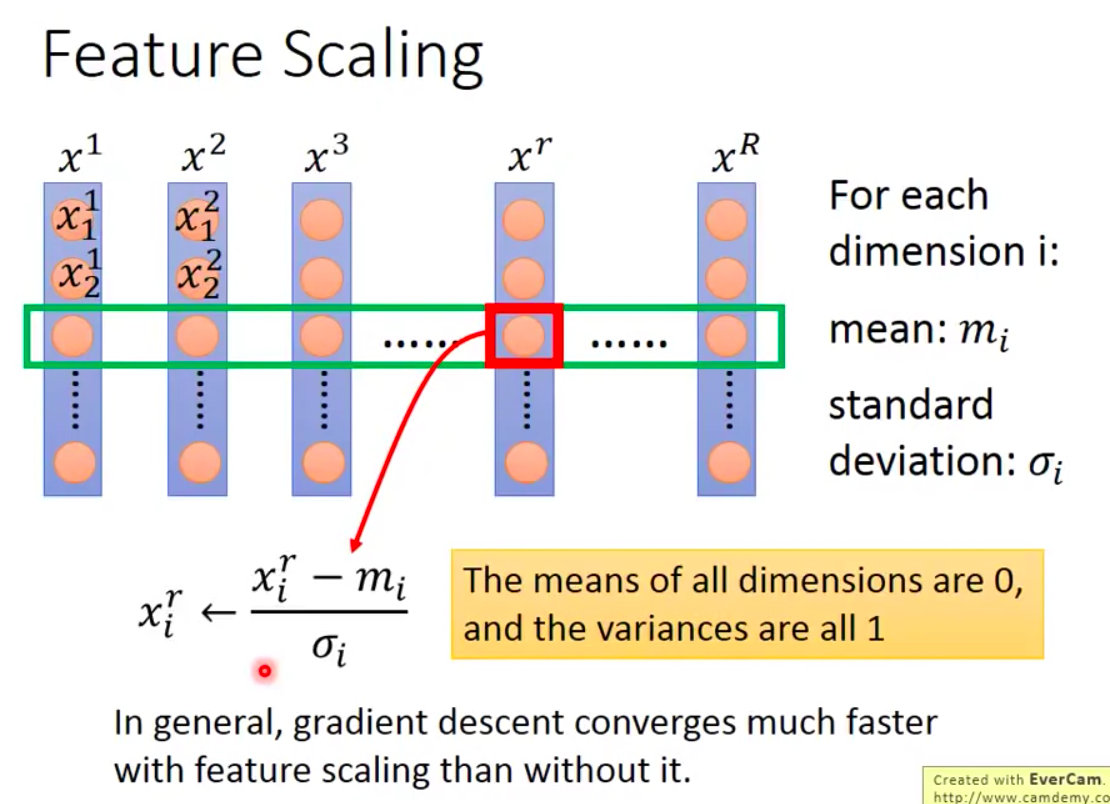
传统的feature scaling方法:对于输入的features,正则化处理
在深度学习中,一般每一层layer都需要正则化处理
Normalization的位置:激活函数之前或之后(加在激活函数之前会有利于激活函数的输出值对应激活函数有梯度的位置 eg:sigmoid函数)
训练过程:
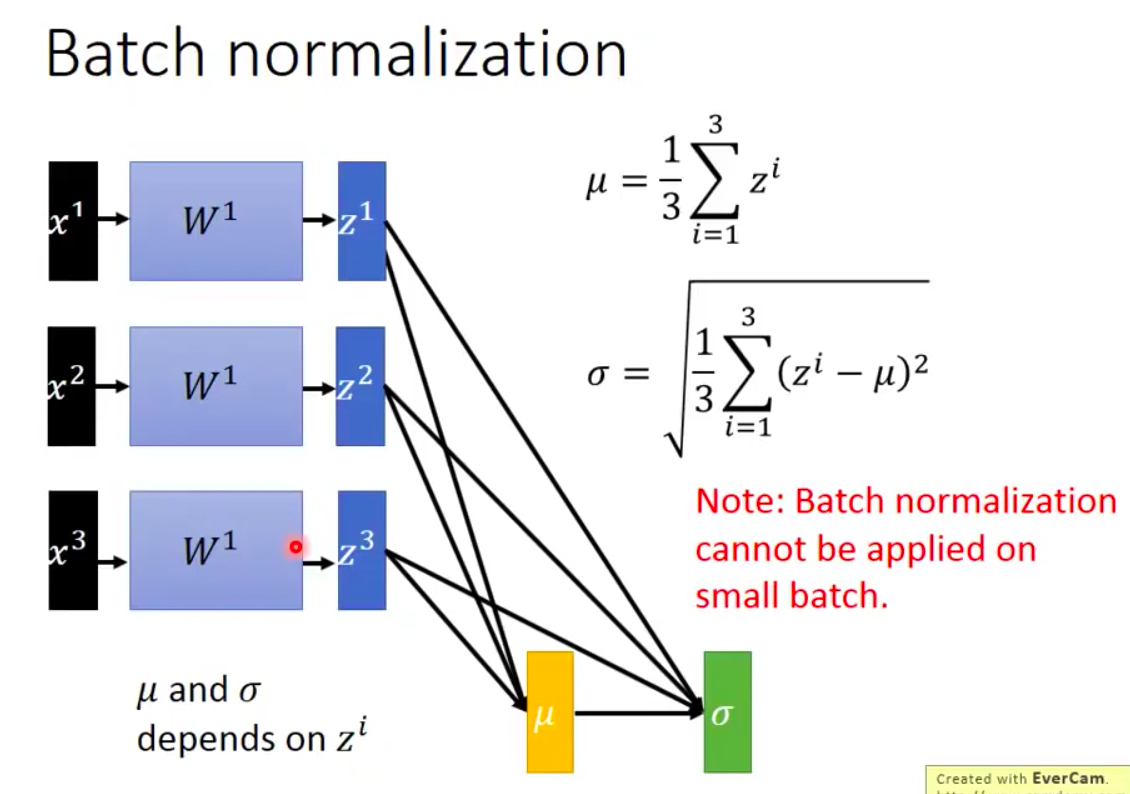
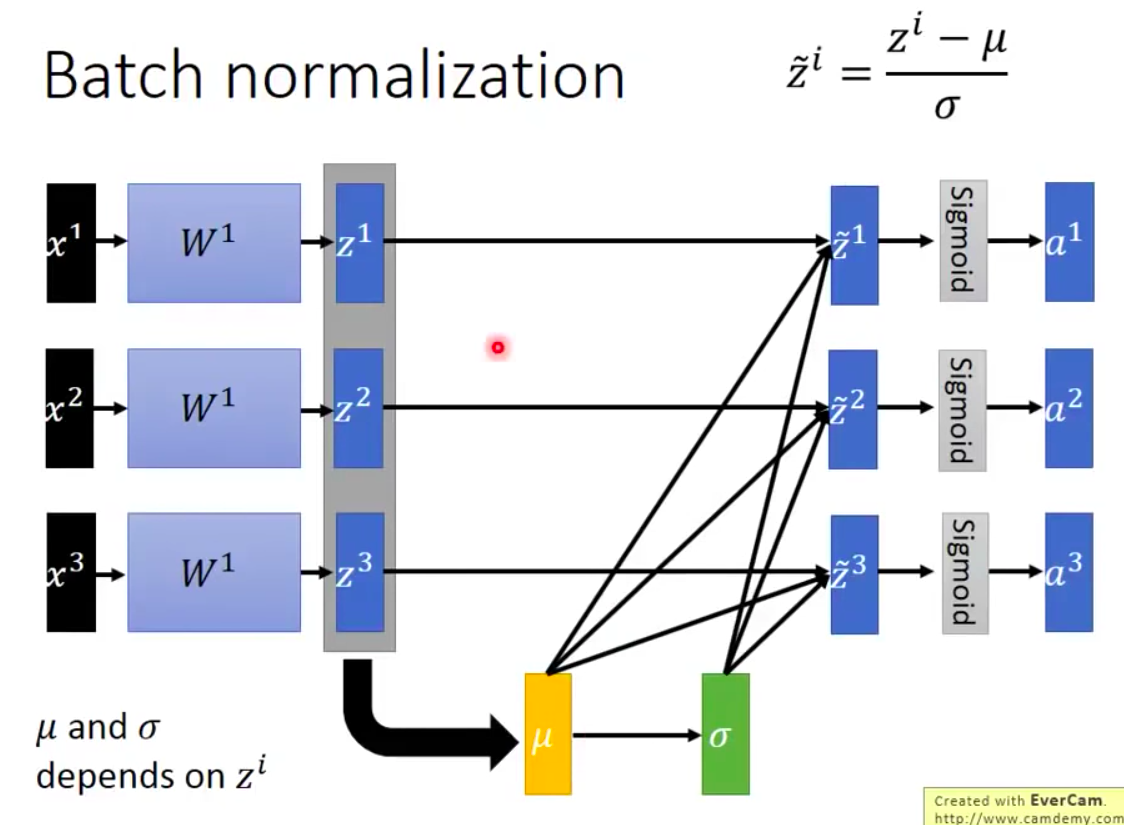
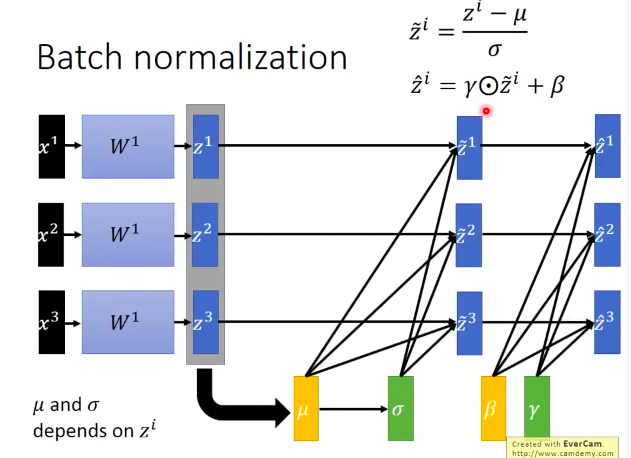
注意:
- 当Batch Size太小的时候BN的效果并不好,因为无法根据小Batch来推断整个数据的均值和方差
- 反向传播的时候均值和方差会同时update,不能简单的把这两个值看成常数
- 有时在BN时不一定选择均值为0,方差为1的分布,而是可以设定两个新的参数分别代表均值和方差,形成新的分布,具体值让神经网络自行学习
- 使用BN时,每个神经元的偏置无用了
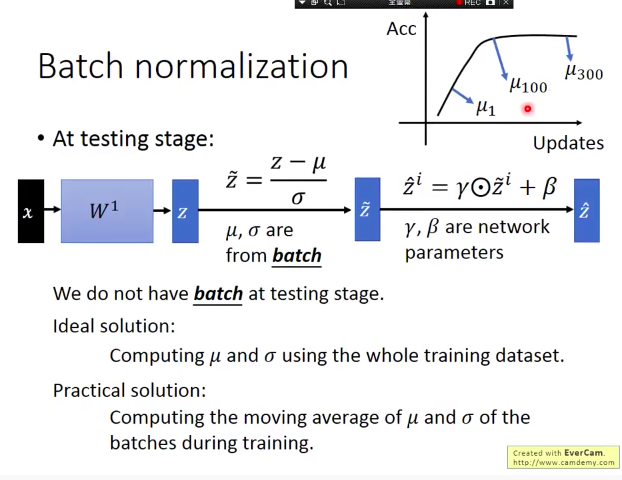
测试过程
一般在测试中设置BatchSize为1,此时我们通过保留训练过程中的多个均值和方差的值进行加权平均来估计整个datasets的均值和方差,训练接近结束时对应的权重较大。
BatchNormalization好处

当模型训练不理想时可以用BN,同时对于test不好也有帮助

