
[论文][半监督语义分割]Adversarial Learning for Semi-Supervised Semantic Segmentation
Adversarial Learning for Semi-Supervised Semantic Segmentation
摘要
创新点:我们提出了一种使用对抗网络进行半监督语义分割的方法。
在传统的GAN网络中,discriminator大多是用来进行输入图像的真伪分类(Datasets里面sample的图片打高分,generator产生的图片打低分),而本文设计了一种全卷积的discriminator,用于区分输入标签图中各个像素(pixel-wise)的分类结果是ground truth或是segmentation network给出的。本文证明了所提出的discriminator可以通过耦合模型的对抗损失和标准交叉熵损失来提高语义分割的准确性。此外,全卷积鉴别器通过发现未标记图像预测结果中的可信区域,实现半监督学习,从而提供额外的监督信号。
网络模型
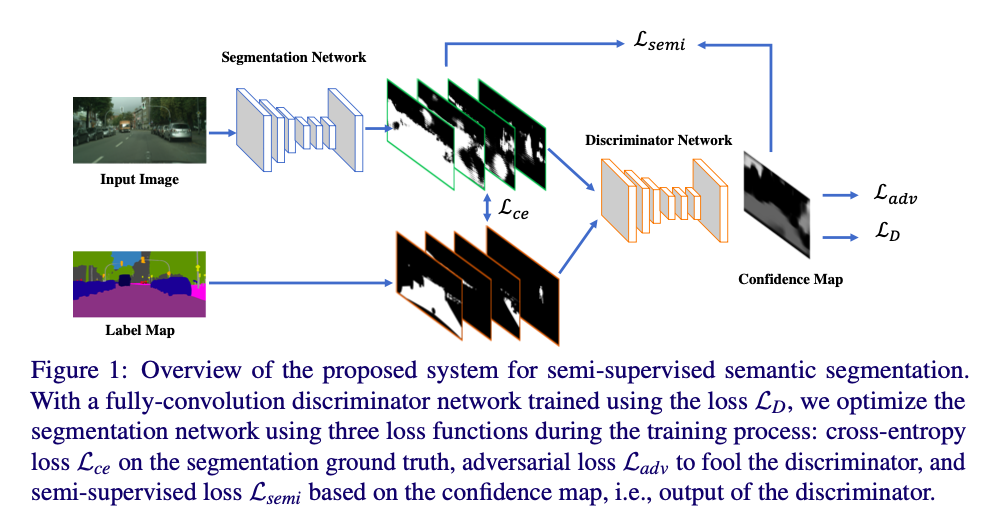
对于labeled images:
-
image xn输入segmentation network,得到分割结果 S(xn)
-
分割结果S(xn)和该图片对应真实标签Yn比较,计算交叉熵损失Lce
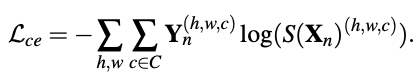
-
分割结果S(xn)送入discriminator中求 Ladv
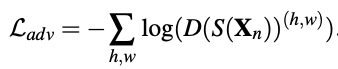
-
使用S(xn)和真实标签Yn训练discriminator:分别将S(xn)和真实标签y输入discriminator,让discriminator分辨输入标签的每个像素是来自是ground truth还是segmentation network(即输入的每个像素为来自于S(xn)还是真实标签Yn)
discriminator的输入为S(xn)或真实标签Yn,尺寸为HxWxC,其中C为语义分割的类别数;输出尺寸为HxWx1,像素值代表这个pixel来自于真实标签Yn的概率(如果discriminator认为该像素100%是来自真实标签Yn,则该位置像素值为1)
损失函数为: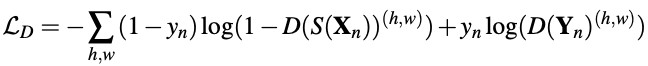
- 注:上式中,当输入为S(xn)时,yn=0,当输入为Yn时,yn=1
对于unlabeled image:
-
将image xn输入segmentation network,得到输出S(xn),尺寸为HxWxC,每个维度上的值代表该像素取这个类别的概率值。对输入进行 one-hot encode,得到 ^Yn
编码过程:
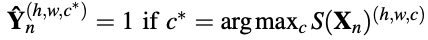
-
用^Yn和S(xn)进行交叉熵损失计算
-
将S(xn)通过训练后的discriminator,得到D(S(xn)),尺寸为HxWx1,并设置闸值,通过指示函数对输出进行二值化(对于输出中像素值大于闸值的像素,认为是可信的,以突出正确的区域)
无标签部分的损失函数为:
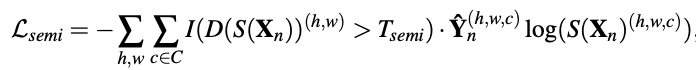
实际中Tsemi的取值为0.1~0.3
训练总损失:
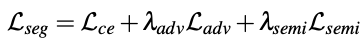
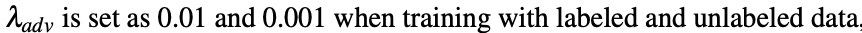

Tips:
- 在训练过程中首先用labeled image进行5000iteration的训练(segmentation network和discriminator交替update)
- 此后随机sample,每个batch里面都可能有labeled image和unlabeled image,各自按照自己的步骤训练
- discriminator只用每个batch里面的labeled image进行训练
具体网络结构
Segmentation network:
首先采用DeepLab-v2 中的ResNet-101作为backbone进行预训练,并去掉最后一个分类层,将最后两个卷积层的步幅从2修改为1,从而使输出特征图的分辨率有效地达到输入图像大小的1/8。为了扩大感受野,我们将扩展后的卷积分别应用于步幅为2和4的conv4和conv5层。此外,我们在最后一层使用了Atrous Spatial Pyramid Pooling (ASPP)。最后,我们应用一个上采样层和softmax输出来匹配输入图像的大小。
Discriminator:
实验
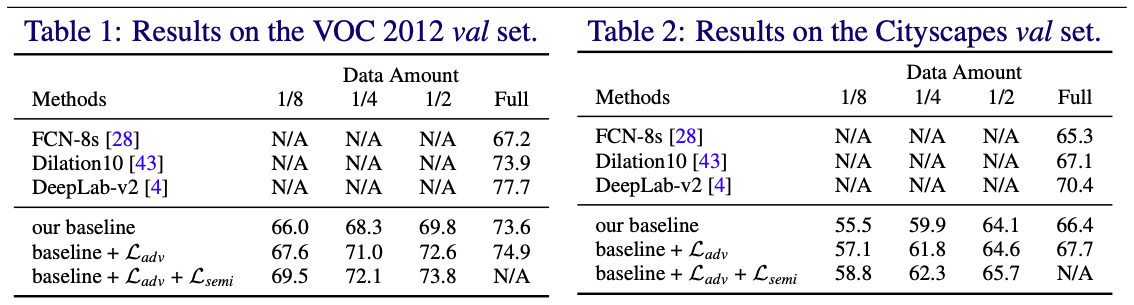
Table4: 训练数据集为pascal VOC标准的1464张图片,SBD中的图片作为无标签数据进行训练

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步