
[论文笔记][半监督语义分割]Universal Semi-Supervised Semantic Segmentation
论文原文原文地址
Motivations
- 传统的训练方式需要针对不同 domain 的数据分别设计模型,十分繁琐(deploy costs)
- 语义分割数据集标注十分昂贵,费时费力
Contributions
- 本文提出的统一模型可以实现跨领域统一训练
- 模型使用少量的标注数据和大量未标注数据(半监督模型)
网络架构/方法实现
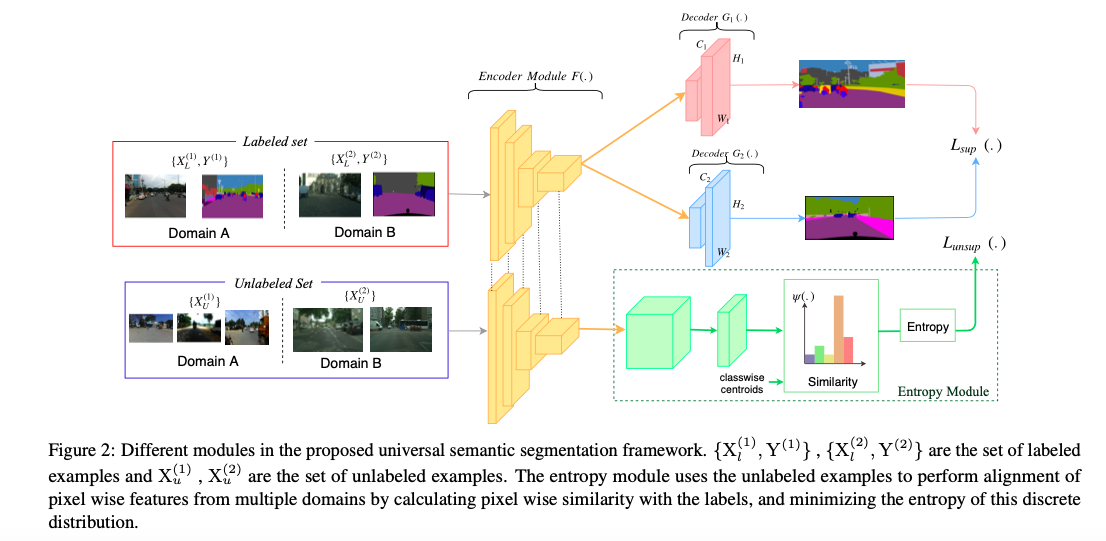
-
基本结构:一个encoder和n个decoder(decoder数量和domain的数量相同)
-
基本设定:假设共有两个数据集domainA和domainB,每个domain中都包含少量有标签的数据和大量无标签的数据
-
具体实现:将不同domain的数据集中有标签的数据汇集为labeled set,无标签的数据集合为unlabeled set。
对于labeled set,使用传统的监督学习的方法,将所有image送入共享的encoder,再根据image所属的域将encoder的输出送入对应的decoder中,与标签对比,用交叉熵函数计算监督损失 。
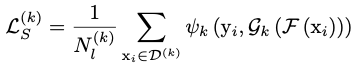
对于unlabeled set,先将image送入encoder(F),再将encoder的输出送入Entropy Module。Entropy Module先将特征图投影到d维(E),再分别计算与这个image相同或不同domain的label embedding相似度
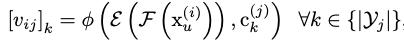
其中相似度的计算是通过点乘实现的非监督损失分为两个部分:cross dataset entropy loss和within dataset entropy loss
cross dataset entropy loss:
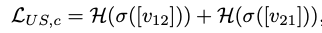
within dataset entropy loss: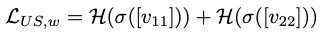
总损失: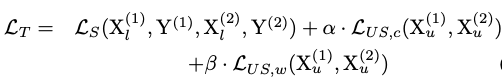
实验部分
**数据集 :Cityscapes (CS), CamVid (CVD) ,Indian Driving Dataset (IDD) **
Table2: 当N= 100,backbone为resnet18时,此方法在Cityscapes (CS), CamVid (CVD)两个数据集上的表现对比
注:Univ-basic:总损失函数后面两项系数为0,Univ-full:总损失函数最后两项系数均为1
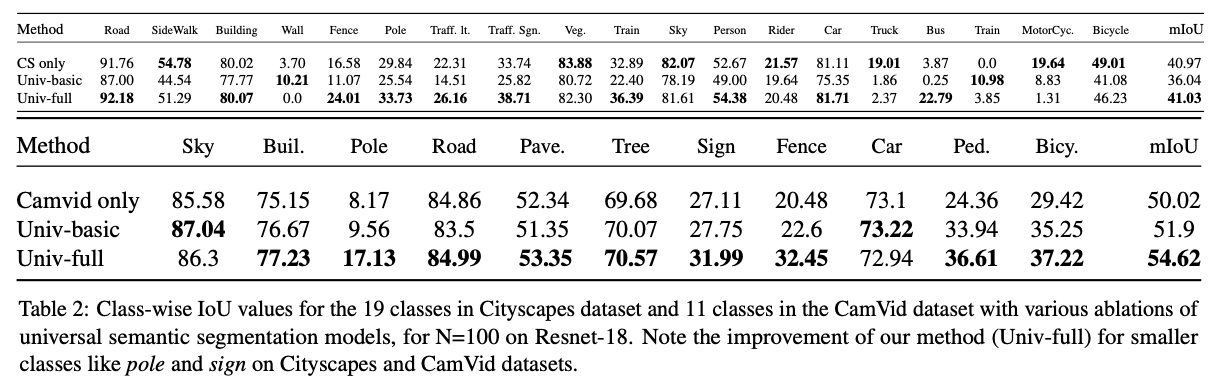
Table3: 当N= 100,N= 50时,backbone为resnet18时,此方法在Cityscapes (CS), CamVid (CVD)两个数据集上的表现对比
注:Univ-basic:总损失函数后面两项系数为0;Univ-cross:总损失函数最后一项系数为0,倒数第二项系数为1;Univ-full:总损失函数最后两项系数均为1
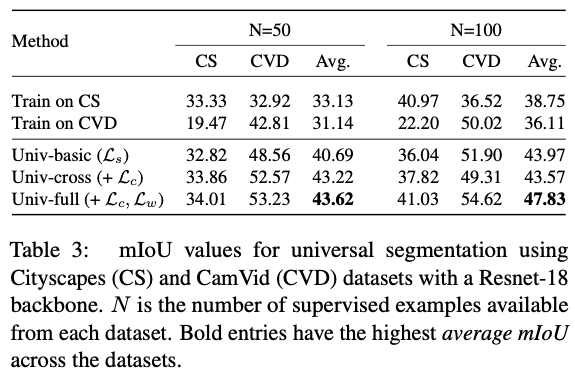
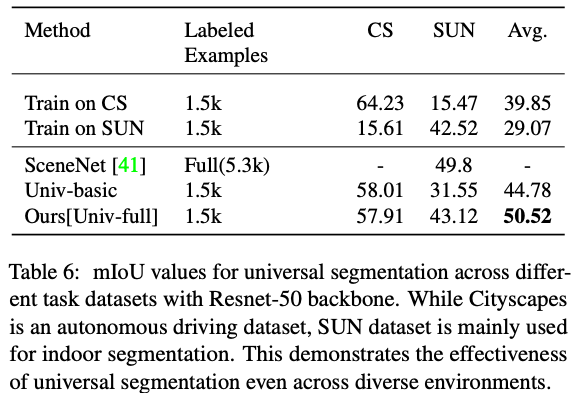
Table4: 当N= 375时,backbone为resnet101时,此方法在Cityscapes (CS)+CamVid (CVD)两个数据集上训练后分别测试的表现
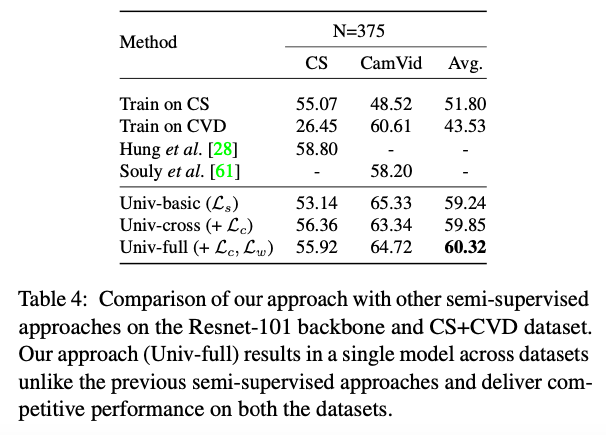
Table5: 当N= 100,N= 1500时,backbone为resnet18,resnet50时,此方法在Cityscapes (CS)+Indian Driving Dataset (IDD) 两个数据集上训练后分别测试的表现
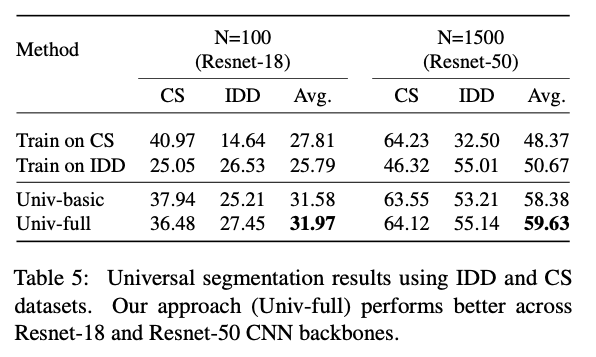
Table6:使用Resnet50作为backbone时,在不同domain上的分割效果展示(CS为自动驾驶数据集,SUN常用于室内景象分割)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!