

BERT
Bert
Bert的架构就是Transformer Encoder的架构。
Bert可以预测盖住的tokens:
Bert的输入:
随机盖住输入的一些tokens。
方法一:把要盖住的tokens换成特殊的tokens,如mask;
方法二:把要盖住的tokens换成随机的一些tokens。
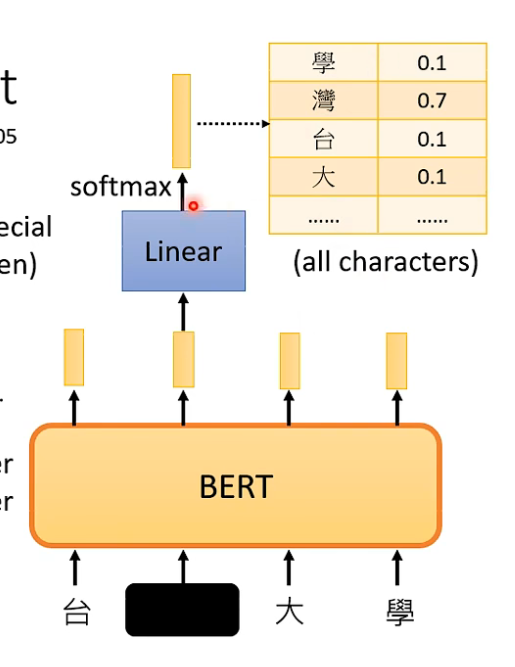
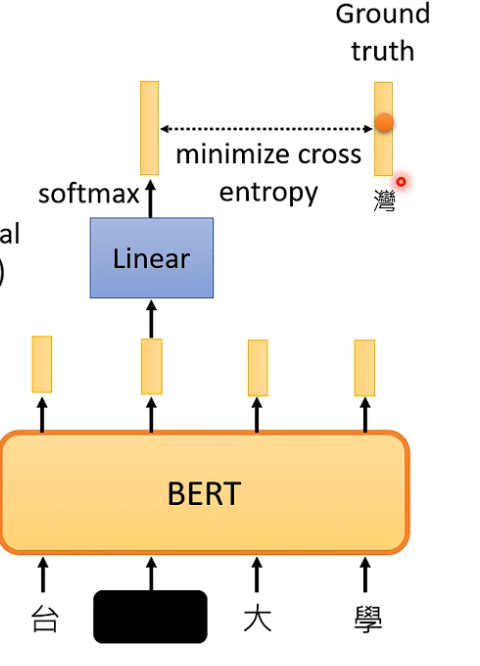
作用:
可以利用这个结果来完成其他的任务。
应用:
- 输入为一个序列,输出为一个类别。
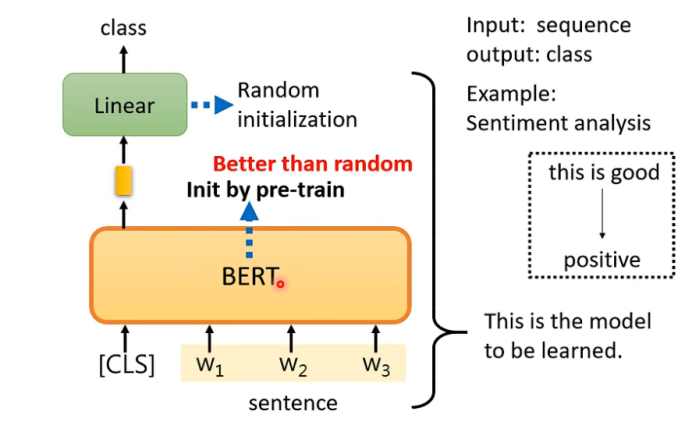
这个BERT模型是预先训练好的,其参数是训练完成后的参数。但是下游任务--句子分析是随机的参数,它需要用到带标签的数据。(下面的例子也是类似的)
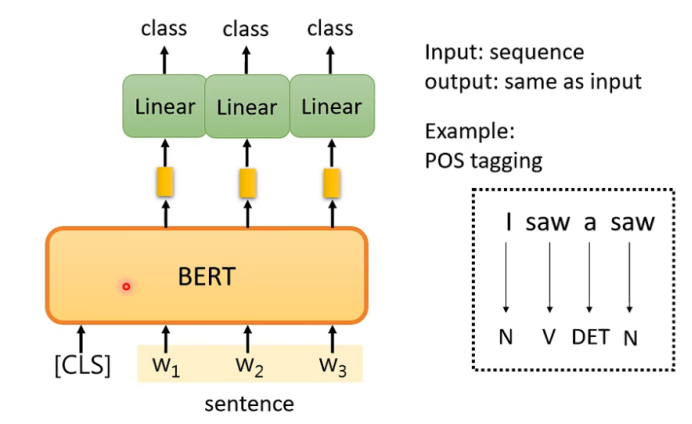
2.输入一个序列,输出也是一个序列,并且长度一样。(例子:词性标注)
3.输入两个句子,输出一个类别(判断这两个句子之间的关系)。(例子:NLI-自然语言推断)
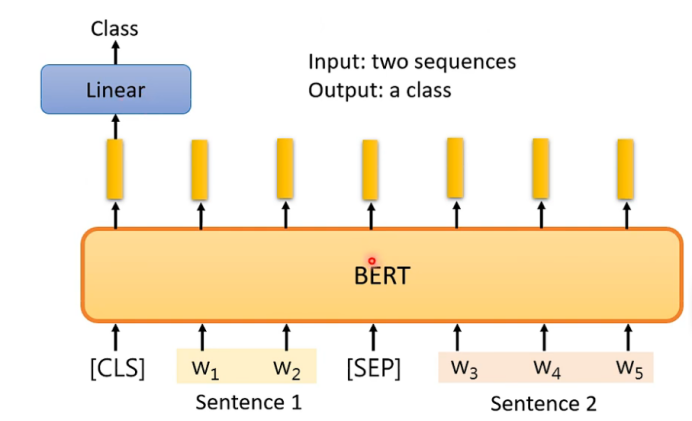
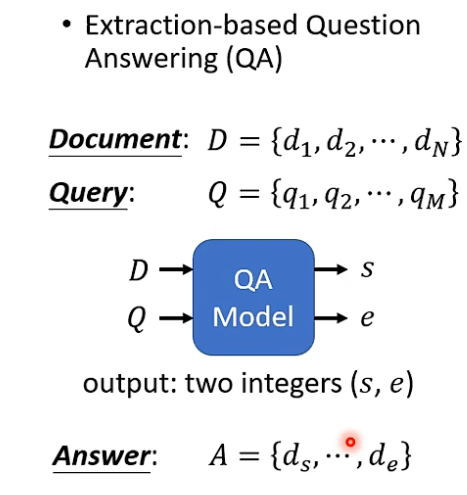
4.QA(前提:答案一定出现在文章里)
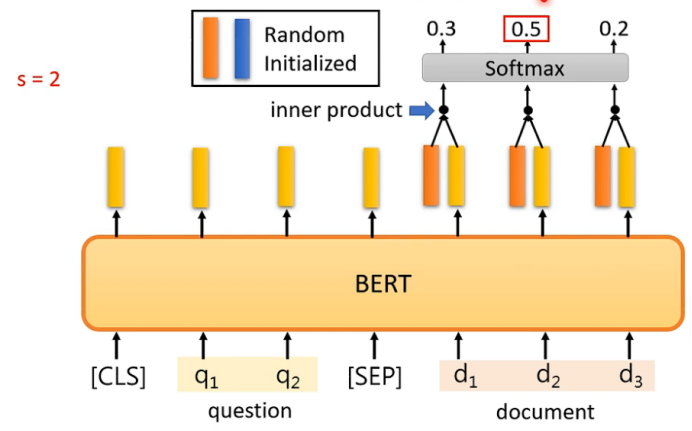
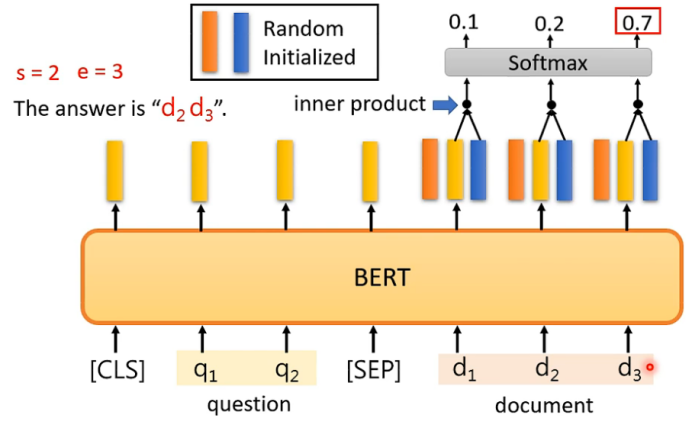
注意:Random Initialized的向量的长度跟bert输出的向量长度一致。
Bert还可以做Next Sentence Prediction:
CLS经过BERT和Linear两个模块之后输出的结果Yes/No表示判断后面的两个句子是否是相接的。(具体实现意义不大,因为相对来说较易。)
用Bert预训练seq2seq模型
Encoder输入的tokens存在错误,但是decoder的输出还原错误前正确的序列。
弄坏的方式,如:把一些tokens盖住、删掉一些tokens、弄乱词汇的顺序、把词汇的顺序做旋转等等。
注意:
Bert的embedding可以考虑上下文的关系,所以即使是同一个字,在不同的情景下,其embedding也会不一样。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗