文本向量化笔记(三)
NNLM 模型的目标是构建一个语言概率模型,而C&W 则是以生成词向量为目标的模型。在NNLM 模型的求解中,最费时的部分当属隐藏层到输出层的权重计算。由于C&W 模型没有采用语言模型的方式去求解词语上下文的条件概率,而是直接对n 元短语打分,这是一种更为快速获取词向量的方式。
C&W 模型的核心机理是: 如果n 元短语在语料库中出现过,那么模型会给该短语打高分;如果是未出现在语料库中的短语则会得到较低的评分。
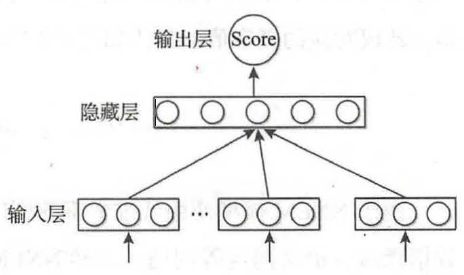
C&W 模型的结构如图所示。
相对于整个语料库而言, C&W 模型需要优化的目标函数见式):
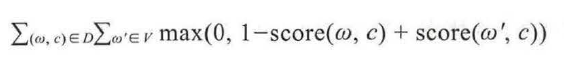
其中, ( ω, c) 为从语料中抽取的n 元短语,为保证上下文词数的一致性, n 应为奇数;ω 是目标词; c 表示目标词的上下文语境;ω' 是从词典中随机抽取的一个词语。
C&W 模型采用成对词语的方式对目标函数进行优化,对式分析可知,目标函数期望正样本的得分比负样本至少高1 分。这里(ω,c) 表示正样本,该样本来自语料库;
(ω' ,c) 表示负样本,负样本是将正样本序列中的中间词替换成其他词得到的。
一般而言,用一个随机的词语替换正确文本序列的中间词,得到新的文本序列基本上都是不符合语法习惯的错误序列,因此这种构造负样本的方法是合理的。同时由于负样本仅仅是修改了正样本一个词得来的,故其基本的语境没有改变,因此不会对分类效果造成太大影响。
与NNLM 模型的目标词在输出层不同, C&W 模型的输入层就包含了目标词,其输出层也变为一个节点,该节点输出值的大小代表n 元短语的打分高低。相应的, C&W 模
型的最后一层运算次数为|h|,远低于NNLM 模型的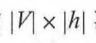 次。
次。
综上所述,较NNLM 模型而言, C&W 模型可大大降低运算量。
为了更高效地获取词向量,有研究者在NNLM 和C&W 模型的基础上保留其核心部分,得到了CBOW ( Continuous Bag of-Words) 模型和Skip-gram 模型。
CBOW 模型如图所示,由图易知,该模型使用一段文本的中间词作为目标词; 同时, CBOW 模型去掉了隐藏层,这会大幅提升运算速率。
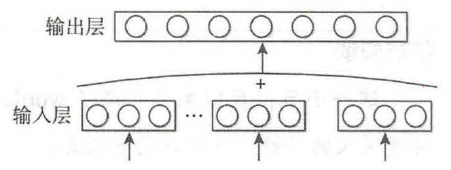
此外, CBOW 模型使用上下文各词的词向量的平均值替代NNLM 模型各个拼接的词向量。由于CBOW 模型去除了隐藏层,所以其输入层就是语义上下文的表示。
CBOW 对目标词的条件概率计算如式所示:

CBOW 的目标函数与NNLM 模型类似, 具体为最大化式:
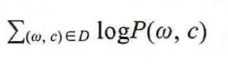

 浙公网安备 33010602011771号
浙公网安备 33010602011771号