


Mysq sql语句教程
2019-10-09 21:01 覃振鸿 阅读(390) 评论(0) 编辑 收藏 举报mysql管理命令
show databases; 显示服务器上当前所有的数据库
use 数据库名称; 进入指定的数据库
show tables; 显示当前数据库中所有的数据表
desc 表名称; 描述表中都有哪些列(表头)
quit; 退出服务器的连接
常用的SQL命令
(1)丢弃指定的数据库,如果存在的话
DROP DATABASE IF EXISTS jd;
(2)创建新的数据库
CREATE DATABASE jd;
(3)进入创建的数据库
USE jd;
(4)创建保存数据的表
CREATE TABLE student(
sid INT,
name VARCHAR(8),
sex VARCHAR(1),
score INT
);
(5)插入数据
INSERT INTO student VALUES('1','scott','m','87');
(6)查询数据
SELECT * FROM student;
(7)删除数据
DELETE FROM student WHERE sid='3';
(8)修改数据
UPDATE student SET name='guo',score='89' WHERE sid='4';
标准SQL语句分类
DDL: Data Define Language 定义数据结构
CREATE/DROP/ALTER
DML: Data Manipulate Language 操作数据
INSERT/DELETE/UPDATE
DQL: Data Query Language 查询数据
SELECT
DCL: Data Control Language 控制用户权限
GRANT(授权)/REVOKE(收权)
解决mysql存储中文乱码
脚本文件另存为的编码
客户端连接服务器端的编码(set names utf8)
服务器端在创建数据库时的编码(chaset=utf8)
mysql中的列类型
创建数据表的时候,指定的列可以存储的数据类型
CREATE TABLE t1( nid 列类型 );
(1)数值型 —— 引号可加可不加
TINYINT 微整型,占1个字节,范围-128~127
SMALLINT 小整型,占2个字节,范围-32768~32767
INT 整型,占4个字节,范围-2147483648~2147483647
BIGINT 大整型,占8个字节
FLOAT 单精度浮点型,占4个字节,最多3.4e38,可能产生计算误差
DOUBLE 双精度浮点型,占8个字节,范围比BIGINT大的多
DECIMAL(M,D) 定点小数,不会产生计算误差,M代表总的有效位数,D小数点后的有效位数
BOOL 布尔型,只有两个值TRUE/1、FALSE/0,TRUE和FALSE不能加引号;在存储的时候使用TINYINT类型,具体的值是1和0
(2)日期时间型 —— 必须加引号
DATE 日期型 '2019-10-31'
TIME 时间型 '14:26:30'
DATETIME 日期时间型 '2019-10-31 14:26:30'
(3)字符串型 —— 必须加引号
VARCHAR(M) 变长字符串,不会产生空间浪费,操作速度相对慢,M最大是65535
CHAR(M) 定长字符串,可能产生空间浪费,操作速度相对的快,M最大值是255,常用于存储手机号,身份证号等一些固定长度的字符串
TEXT(M) 大型变长字符串,M最大是2G
列约束
mysql可以对要插入的数据进行特定的验证,只有满足条件才允许插入到数据表中,否则被认为非法的插入
例如:一个人的性别只能是男或者女,一个人成绩0~100
CREATE TABLE t1( id 列类型 列约束 );
(1)主键约束——PRIMARY KEY
声明了主键约束的列上的值不能出现重复,一个表中只能有一个主键,通常加在编号列;表中查询的记录会按照主键从小到大的顺序排列——加快查找速度。
声明了主键约束后就不能在插入NULL值
(2)非空约束 —— NOT NULL
声明了非空约束的列上不允许插入NULL值
(3)唯一约束——UNIQUE
声明了唯一约束的列上不允许插入重复的值,允许插入NULL,甚至多个NULL ps:NULL和任何值比较都不等,包括两个NULL比较
(4)检查约束——CHECK
检查约束可以对插入的数据进行自定义验证
CREATE TABLE student(
score TINYINT CHECK(score>=0 AND score<=100)
);
mysql不支持检查约束,会降低数据的插入速度
(5)默认值约束——DEFAULT
可以使用DEFAULT关键字声明默认值,有两种方式可以应用默认值
INSERT INTO laptop_family VALUES(70,'神州',DEFAULT);
INSERT INTO laptop_family(fid,fname) VALUES(80,'华为');
(6)外键约束——FOREIGN KEY
声明了外键约束的列,取值必须在另一个表的主键列上出现过,两者的列类型要保持一致,允许插入NULL
FOREIGN KEY(外键列) REFERENCES 另表(主键列)
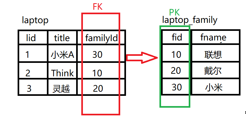
mysql中的自增列
AUTO_INCREMENT: 自动增长,假如声明了自增列,无需手动赋值,直接赋值为NULL,会获取当前的最大值,然后加1
注意:
只适用于整数型的主键列上
自增允许手动赋值
3.简单查询
#演示表 #设置客户端连接服务器端编码 SET NAMES UTF8; #丢弃数据库,如果存在 DROP DATABASE IF EXISTS tedu; #创建数据库,设置编码 CREATE DATABASE tedu CHARSET=UTF8; #进入创建的数据库 USE tedu; #创建数据表dept CREATE TABLE dept( did INT PRIMARY KEY AUTO_INCREMENT, dname VARCHAR(8) UNIQUE ); #插入数据 INSERT INTO dept VALUES(10,'研发部'); INSERT INTO dept VALUES(20,'市场部'); INSERT INTO dept VALUES(30,'运营部'); INSERT INTO dept VALUES(40,'测试部'); #创建数据表emp CREATE TABLE emp( eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(8), sex BOOL DEFAULT 0, birthday DATE, salary DECIMAL(7,2), deptId INT, FOREIGN KEY(deptId) REFERENCES dept(did) ); #插入数据 INSERT INTO emp VALUES(NULL,'Tom',1,'1990-5-5',6000,20); INSERT INTO emp VALUES(NULL,'Jerry',0,'1991-8-20',7000,10); INSERT INTO emp VALUES(NULL,'David',1,'1995-10-20',3000,30); INSERT INTO emp VALUES(NULL,'Maria',0,'1992-3-20',5000,10); INSERT INTO emp VALUES(NULL,'Leo',1,'1993-12-3',8000,20); INSERT INTO emp VALUES(NULL,'Black',1,'1991-1-3',4000,10); INSERT INTO emp VALUES(NULL,'Peter',1,'1990-12-3',10000,10); INSERT INTO emp VALUES(NULL,'Franc',1,'1994-12-3',6000,30); INSERT INTO emp VALUES(NULL,'Tacy',1,'1991-12-3',9000,10); INSERT INTO emp VALUES(NULL,'Lucy',0,'1995-12-3',10000,20); INSERT INTO emp VALUES(NULL,'Jone',1,'1993-12-3',8000,30); INSERT INTO emp VALUES(NULL,'Lily',0,'1992-12-3',12000,10); INSERT INTO emp VALUES(NULL,'Lisa',0,'1989-12-3',8000,10); INSERT INTO emp VALUES(NULL,'King',1,'1988-12-3',10000,10); INSERT INTO emp VALUES(NULL,'Brown',1,'1993-12-3',22000,NULL);
(1)查询特定的列
示例: 查询所有员工的姓名、工资
SELECT ename,salary FROM emp;
(2)查询所有的列
SELECT * FROM emp;
SELECT eid,ename,sex,birthday,salary,deptId FROM emp;
(3)给列起别名
示例: 查询所有员工的姓名和工资,使用汉字别名
SELECT ename AS 姓名,salary AS 工资 FROM emp;
练习: 查询所有员工的编号、姓名、性别、生日,使用汉字别名
SELECT eid AS 编号,ename AS 姓名,sex 性别,birthday 生日 FROM emp;
练习: 查询所有员工的姓名和工资,使用一个字母作为别名
SELECT ename e,salary s FROM emp;
(4)显示不同的记录/合并相同的记录
示例: 查询出员工都分布在哪些部门
SELECT DISTINCT deptId FROM emp;
练习: 查询出都有哪些性别的员工
SELECT DISTINCT sex FROM emp;
(5)查询时执行计算
示例: 计算2+3-5*6.4+3.6*8.7
SELECT 2+3-5*6.4+3.6*8.7;
练习: 查询出所有员工的姓名及其年薪
SELECT ename,salary*12 FROM emp;
练习: 假设每个员工的工资增加500,年终奖5000,查询出所有员工的姓名及其年薪,给列起汉字别名
SELECT ename 姓名,(salary+500)*12+5000 年薪 FROM emp;
(6)查询结果集排序
示例: 查询所有的部门,结果集按照部门编号升序排列
SELECT * FROM dept ORDER BY did ASC;#ascendant
示例: 查询所有的部门,结果集按照部门编号降序排列
SELECT * FROM dept ORDER BY did DESC;
describe 描述
descendant 降序
练习:查询所有的员工,结果集按照工资降序排列
SELECT * FROM emp ORDER BY salary DESC;
练习: 查询所有的员工,结果集按照年龄从小到大排列
SELECT * FROM emp ORDER BY birthday DESC;
练习: 查询所有的员工,结果集按照姓名升序排列
SELECT * FROM emp ORDER BY ename;
练习: 查询所有的员工,结果集按照工资降序排列,如果工资相同按照姓名升序排列
SELECT * FROM emp ORDER BY salary DESC,ename;
练习: 查询所有的员工,结果集中女员工显示在前边,如果性别相同,按照年龄从大到小排列
SELECT * FROM emp ORDER BY sex,birthday;
(7)条件查询
示例: 查询出编号为7的员工
SELECT * FROM emp WHERE eid=7;
练习: 查询出姓名叫king的员工的编号,姓名,工资
SELECT eid,ename,salary FROM emp WHERE ename='king';
练习: 查询出所有的女员工
SELECT * FROM emp WHERE sex=0;
练习: 查询出20号部门下的员工有哪些
SELECT * FROM emp WHERE deptId=20;
练习: 查询出工资为5000以上的员工有哪些
SELECT * FROM emp WHERE salary>5000;
|
比较运算符: > < = >= <= !=(不等于) |
练习: 查询出1991-1-1后出生的员工有哪些
SELECT * FROM emp WHERE birthday>'1991-1-1';
练习: 查询出不在10号部门的员工有哪些
SELECT * FROM emp WHERE deptId!=10;
练习: 查询出没有明确部门的员工有哪些
SELECT * FROM emp WHERE deptId IS NULL;
练习: 查询出有明确部门的员工有哪些
SELECT * FROM emp WHERE deptId IS NOT NULL;
练习: 查询出工资在6000以上的男员工有哪些
SELECT * FROM emp WHERE salary>6000 AND sex=1;
练习: 查询出工资在5000~8000之间所有员工
SELECT * FROM emp WHERE salary>=5000 AND salary<=8000;
SELECT * FROM emp WHERE salary BETWEEN 5000 AND 8000;
练习:查询出工资在5000以下和8000以上的所有员工
SELECT * FROM emp WHERE salary<5000 OR salary>8000;
SELECT * FROM emp WHERE salary NOT BETWEEN 5000 AND 8000;
练习: 查询出1990年之前和1993年之后出手的员工有哪些
SELECT * FROM emp WHERE birthday<'1990-1-1' OR birthday>'1993-12-31';
练习: 查询出1993年出生的员工有哪些
SELECT * FROM emp WHERE birthday>='1993-1-1' AND birthday<='1993-12-31';
SELECT * FROM emp WHERE birthday BETWEEN '1993-1-1' AND '1993-12-31';
练习: 查询出20号部门和30号部门的员工有哪些
SELECT * FROM emp WHERE deptId=20 OR deptId=30;
SELECT * FROM emp WHERE deptId IN(20,30);
练习: 查询出不在20号部门或者30号部门的员工有哪些
SELECT * FROM emp WHERE deptId NOT IN(20,30);
|
AND/OR BETWEEN.. AND../NOT BETWEEN..AND.. IS NULL/IS NOT NULL IN() / NOT IN() |
(8)模糊条件查询
示例: 查询出姓名中含有字母e的员工
SELECT * FROM emp WHERE ename LIKE '%e%';
练习: 查询出姓名中以e以为的员工
SELECT * FROM emp WHERE ename LIKE '%e';
练习: 查询出姓名中倒数第二个字符为e的员工
SELECT * FROM emp WHERE ename LIKE '%e_';
|
% 可以匹配任意个字符 >=0 _ 可以匹配任意1个字符 =1 以上两个匹配符必须结合LIKE关键字使用 |
(9)分页查询
假如查询的结果集有太多的数据,一次显示不完,可以使用分页显示
需要有两个条件: 当前的页码值、每页的数据量
SELECT * FROM emp LIMIT start,count;
start: 开始查询的值,从哪一条开始查询
count: 每页的数据量
|
start = (当前的页码值-1)*每页的数据量 |
注意事项: start和count必须是数值型,不能加引号。
假设每页显示5条数据
第1页: SELECT * FROM emp LIMIT 0,5;
第2页: SELECT * FROM emp LIMIT 5,5;
第3页: SELECT * FROM emp LIMIT 10,5;
假设每页显示6条数据,查询前3页
第1页: SELECT * FROM emp LIMIT 0,6;
第2页: SELECT * FROM emp LIMIT 6,6;
第3页: SELECT * FROM emp LIMIT 12,6;
#

