redis cluster 集群畅谈(三) 之 水平扩容、slave自动化迁移
上一篇 http://www.cnblogs.com/qinyujie/p/9029522.html, 主要讲解 实验多master写入、读写分离、实验自动故障切换(高可用性),那么本篇我们就来聊了聊redis cluster 水平扩容以及自动化 slave 迁移。
redis repliction 主从架构,一主多从更多的是为了提高 读QPS 。而 redis cluster 集群中不建议或者没有说做物理的读写分离了,redis cluster 集群更强调的是通过master的水平扩容,来横向扩展 读写QPS,还有支撑更多的 海量数据。
下面聊聊 redis cluster 集群如何水平扩容?
注意:水平扩容基于 redis cluster集群部署 基础上来操作,新加的redis 实例博主就直接在192.168.43.18 机器上做了,真正生产环境应该在独立机器上部署,具体根据自身公司需求而定,后面就不赘述了。
创建一个新master redis 实例
mkdir -p /var/redis/7007 //redis 的持久化文件地址
修改 redis 实例配置文件 7007.conf
cd /usr/local/redis-3.2.8 && cp redis.conf /etc/redis/7007.conf
port 7007
cluster-enabled yes
cluster-config-file /etc/redis-cluster/node-7007.conf
cluster-node-timeout 15000
daemonize yes
pidfile /var/run/redis_7007.pid
dir /var/redis/7007
logfile /var/log/redis/7007.log
bind 192.168.43.18
appendonly yes
修改redis 实例启动脚本,REDISPORT=7007
cd redis-3.2.8 && cp utils/redis_init_script /etc/init.d/redis_7007 && chmod 777 /etc/init.d/redis_7007 && vim /etc/init.d/redis_7007
启动7007 redis 实例
./etc/init.d/redis_7007 start
将 7007 redis 实例加入原有 redis cluster 集群中
redis-trib.rb add-node ip1:port ip2:port
ip1:port1: 需要加入redis cluster 中的 redis 实例 ip2:port2 : redis-trib.rb去拿集群状态数据
redis-trib.rb add-node 192.168.43.18:7007 192.168.43.16:7001
redis-trib.rb check 192.168.43.16:7001 查看集群状态信息

通过上图可以看出,7007 redis 实例已经加入到集群中,作为master,但是我们也可以看到,7007 是没有slot 的,这就意味着无法存储数据,因此我们需要将其他master 中的部分 slot 迁移到7007 redis 上。怎么做呢 ?
reshard slot 到 7007 redis
那需要迁移多少的slot 到 7007 redis 呢?
slot ( 4096 ) = 16384 / master 个数(4)
迁移slot
redis-trib.rb reshard 192.168.43.16:7001


然后 yes 即可,下图表示迁移成功:

上面讲了新增一个master redis 实例,那么slave redis 实例又如何加入到集群中呢?
创建一个新slave redis (7008)实例
方法和上面创建一个新master redis 实例一样,实例配置启动后,就要加入到集群中了。
7008 slave redis 实例加入 redis cluster 集群
redis-trib.rb add-node --slave --master-id ID ip1:port1 ip2:port2
ID : master redis 实例ID ip1:port1: 需要加入redis cluster 中的 redis 实例 ip2:port2 : redis-trib.rb去拿集群状态数据
下面将7008 redis 作为 7001 master redis 的 slave 中(特意放到 7001 master 为下面 slave自动化迁移做准备),如下图:
redis-trib.rb add-node --slave --master-id a65e04974f47d110158a33c54c75ad8239fa6b10 192.168.43.18:7008 192.168.43.16:7001

删除 redis 实例
将某个 redis 实例从集群中移除,当先用resharding将数据都移除到其他节点,确保node为空之后,才能执行remove操作,当你清空了一个master的 hash slot 时,redis cluster就会自动将其slave挂载到其他master上去,这个时候只需要删除掉master就可以了
当要删除的redis node 为master 时,先讲hash slot 迁移到其他三个master 中,
master1 slot(1365) + master2 slot(1365) + master3 slot(1366) = master4 slot(4096)
根据上面,需要分三次迁移,两次迁移1365,一次1366 到其他master 节点中
redis-trib.rb reshard 192.168.43.16:7001




将 redis 从 redis cluster 集群中移除
redis-trib.rb del-node 192.168.43.16:7001 cc9ef42e215c5cc1c8cf37acde4946997620f003


自动化 slave 迁移
如果说redis cluster 集群本身就具备高可用性,那么当 6个节点,3 master 3 slave,当出现某个slave 宕机了,那么就只有master了,这时候的高可用性就无法很好的保证了,万一master 也宕机了,咋办呢? 针对这种情况,如果说其他有多余的slave ,集群自动把多余的slave 迁移到 没有slave 的master 中,那就好了,就可以说具备很好的高可用性了,没错,redis cluster 就是这么NB,redis cluster 就支持自动化slave 迁移。下面我们演示下吧。
看下现在的集群状态,如下图:

上图可以看到,7001 master 上有 2 slave 。
这时候我们将192.168.43.17:7003 master 的 slave kill 掉:
info Replication //查看redis 实例的主从信息

kill 进程 和 rm -rf /var/ run/redis_7006.pid,如下图:

再次看现在的集群状态,如下图:

从上图结合前面的集群状态信息,可以看出redis cluster 自动的将 7001 中多余的slave 迁移到了 7003 上。
当再度将7006 redis 实例启动后,7003 master 就会有2个slave 了。

总结:在redis cluster 集群中,如果某个master 下没有了slave ,其他master 中有多余的slave 的话,集群会自动slave 迁移,由此可以见,可以利用该特性,在生产环境中,适当的添加冗余的slave 实例,可以很大程度上提高集群的高可用性
PS:有的小伙伴可能在做迁移的时候solt不是很好的均匀迁移出去。就像下面这样 集群状态会有一个警告,。当你再去做其它迁移solt的时候会不让你继续进行下去。
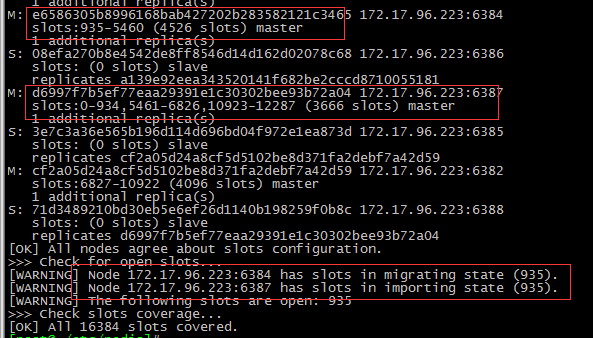
通过查资料发现可能是由于redis版本号的问题导致。
redis-server:3.2.8
ruby:2.4.1p111
redis.rb(使用:gem install redis安装):4.0.0 < - 这是问题的原因
所以有时间再去试试4.0以上版本。
问题尚未解决!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号