

Python-线程(2)
GIL全局解释器锁
在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。>有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL
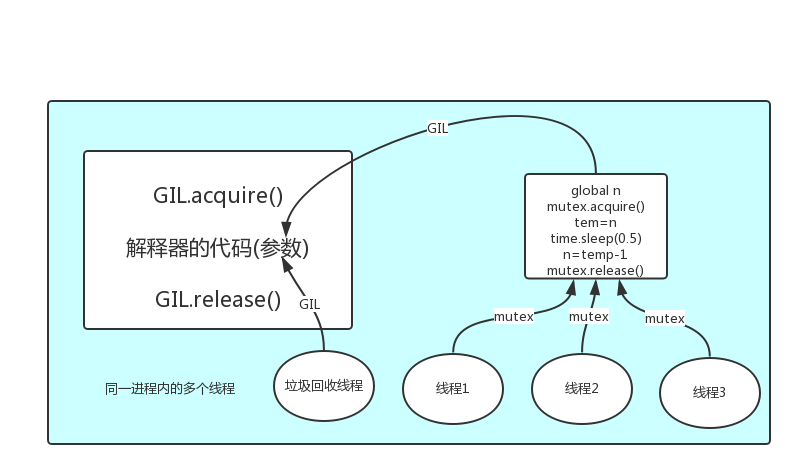
GIL 本质上就是一把互斥锁,将并发运行编程串行,以此来控制同一时间内共享的数据只能被一个任务锁修改,进而保证数据的安全
可以肯定的是,保护数据的安全,就应该加锁
'''
验证全局解释器锁
'''
import time
from threading import Thread,current_thread
n = 100
def task():
global n
n2 = n
# 全局解释器锁碰到 IO阻塞就切换cpu执行并解锁
time.sleep(1)
n = n2 - 1
print(n,current_thread().name)
for line in range(100):
t = Thread(target=task)
t.start()
GIL 与 Lock
为什么有了解释器的锁来保证同一时间只能有一个线程来执行,为什么还需要有线程的lock锁?
首先,我们要达成共识,锁的目的就是为了保护数据,同一时间只能有一个线程来修改共享的数据
然后,我们就可以得到结论:保护不同的数据我们需要加不同的锁
那么 GIL 与Lock是两把锁,保护的数据不一样,GIL是解释器里的,保护的是解释器级别的数据,比如垃圾回收的数据,Lock是保护用户自己开发的应用程序的数据,很明显GIL自己不负责这件事,只能用户自定义加锁处理,即Lock
当我们在没有IO的程序里面(纯计算)不加锁不会存在锁的错乱问题,因为GIL限制了同一时刻只能让一个线程执行,所以不用加锁
当我们在IO密集的程序里面,不加锁会导致数据安全问题,因为程序遇到IO cpu会切断使用权,让另一个线程执行,那么这时候另一个线程拿到的数据还是之前的一份,不是最新的,导致所有线程修改数据不是正确的,引起数据安全问题,所以这个时候加上线程锁来保证这个数据安全
多进程 VS 多线程
站在两个角度看问题
计算密集型:
单核:
开启进程:消耗资源大
开启线程:消耗资源小于进程
多核:
开启进程:并行执行,效率高
开启线程:并发执行,效率低
IO密集型:
单核:
开启进程:消耗资源大
开启线程:消耗资源小于进程
多核:
开启进程:并行执行,效率小于多线程,因为遇到IO会立即切换CPU的执行权限
开启线程:并发执行,效率高于多进程
# coding=utf-8
from multiprocessing import Process
from threading import Thread
import os
import time
# 计算密集型
def work1():
num = 0
for i in range(40000000):
num += 1
# IO密集型
def work2():
time.sleep(1)
if __name__ == '__main__':
# 测试计算密集型
start_time = time.time()
ls = []
for i in range(10):
# 测试多进程
p = Process(target=work1) # 程序执行时间为7.479427814483643
# 测试多线程
# p = Thread(target=work1) # 程序执行时间为28.56563377380371
ls.append(p)
p.start()
for l in ls:
l.join()
end_time = time.time()
print(f"程序执行时间为{end_time - start_time}")
# 测试计算密集型结论:
# 在计算较小数据时候使用多线程效率高
# 在计算较大数据时候使用多进程效率高
# 测试IO密集型
start_time = time.time()
ls = []
for i in range(10):
# 测试多进程
# p = Process(target=work2) # 程序执行时间为2.749157190322876
# 测试多线程
p = Thread(target=work2) # 程序执行时间为1.0130579471588135
ls.append(p)
p.start()
for l in ls:
l.join()
end_time = time.time()
print(f"程序执行时间为{end_time - start_time}")
# 测试IO密集型结论:
# 使用多线程效率要比使用多进程效率高
计算密集型情况下:
在计算较小数据时候使用多线程效率高
在计算较大数据时候使用多进程效率高
IO密集型情况下:
使用多线程效率要比使用多进程效率高
高效执行程序:
使用多线程和多进程
这里打个比方:
一个工人相当于cpu,工厂原材料就相当于线程。
此时计算相当于工人在干活,I/O阻塞相当于为工人干活提供所需原材料的过程,工人干活的过程中如果没有原材料了,则工人干活的过程需要停止,直到等待原材料的到来。
如果你的工厂干的大多数任务都要有准备原材料的过程(I/O密集型),那么你有再多的工人,意义也不大,还不如一个人,在等材料的过程中让工人去干别的活,
反过来讲,如果你的工厂原材料都齐全,那当然是工人越多,效率越高
结论:
对计算机来说:CPU越多越好,但是对于IO来说,再多的CPU也没用
对于程序来说:随着CPU的增多执行效率肯定会有所提高(不管提高多大,总会有所提高)
假设我们有四个任务需要处理,处理方式肯定是要玩出并发的效果,解决方案可以是:
方案一:开启四个进程
方案二:一个进程下,开启四个线程
结果:
单核:
若四个任务是计算密集型,方案一增加了创建进程时间,方案二远小于方案一,方案二胜
若四个任务是I/O密集型,方案一也增加了创建进程时间,且进程切换速度还不如线程,所以方 案二又胜
多核:
若四个任务是计算密集型,多核 开多个进程一起计算是并行计算,在线程中执行用不上多核, 那么方案一效率高,方案一胜
若四个任务是I/O密集型,再多的核也解决不了I/O问题,方案二胜
结论:
现在的计算机基本上都是多核,python对于计算密集型的程序来说,开多线程的效率并不能带来多 大性能的提升,甚至还不如串行,但是对于I/O密集型的程序来说,开多线程效率就明显提升
多线程用于I/O密集型:例如Socket、爬虫、Web
多进程用于计算密集型,如金融分析,数据分析
死锁现象
# coding=utf-8
from threading import Lock,Thread,current_thread
import time
mutex_a = Lock()
mutex_b = Lock()
class MyThread(Thread):
# 线程执行任务
def run(self):
self.work1()
self.work2()
def work1(self):
mutex_a.acquire()
print(f"{self.name} 抢到了锁a")
mutex_b.acquire()
print(f"{self.name} 抢到了锁b")
mutex_b.release()
print(f"{self.name} 释放了锁b")
mutex_a.release()
print(f"{self.name} 释放了锁a")
def work2(self):
mutex_b.acquire()
print(f"{self.name} 抢到了锁b")
# 模拟IO操作
time.sleep(1)
mutex_a.acquire()
print(f"{self.name} 抢到了锁a")
mutex_a.release()
print(f"{self.name} 释放了锁a")
mutex_b.release()
print(f"{self.name} 释放了锁b")
for i in range(2):
t = MyThread()
t.start()
Thread-1 抢到了锁a
Thread-1 抢到了锁b
Thread-1 释放了锁b
Thread-1 释放了锁a
Thread-1 抢到了锁b
Thread-2 抢到了锁a
.....卡主了
开启两个线程之后,每个线程会抢cpu执行,
第一个线程抢到了,执行work1,抢到锁a、b,释放a、b
再回来执行work2,抢到锁b,碰到有IO阻塞,切换线程执行
到第二个线程,可以抢到锁a,但是锁还在第一个线程手里拿着
锁b么有被释放,线程二拿不到锁b,于是卡主了
递归锁
解决死锁问题,需要用到递归锁
RLock:只有一把钥匙,可以提供多个线程去使用,每次使用会计数+1,只有计数为0 的时候 才能真正释放让另一个线程使用
可以理解为遇到IO操作之后,如果身上有这个递归锁,必须先把这个递归锁解开之后然后你再去做其他事情。
# coding=utf-8
from threading import Lock,Thread,current_thread,RLock
import time
# mutex_a = Lock()
# mutex_b = Lock()
mutex_a = mutex_b = RLock()
class MyThread(Thread):
# 线程执行任务
def run(self):
self.work1()
self.work2()
def work1(self):
mutex_a.acquire()
print(f"{self.name} 抢到了锁a")
mutex_b.acquire()
print(f"{self.name} 抢到了锁b")
mutex_b.release()
print(f"{self.name} 释放了锁b")
mutex_a.release()
print(f"{self.name} 释放了锁a")
def work2(self):
mutex_b.acquire()
print(f"{self.name} 抢到了锁b")
# 模拟IO操作
time.sleep(1)
mutex_a.acquire()
print(f"{self.name} 抢到了锁a")
mutex_a.release()
print(f"{self.name} 释放了锁a")
mutex_b.release()
print(f"{self.name} 释放了锁b")
for i in range(2):
t = MyThread()
t.start()
Thread-1 抢到了锁a
Thread-1 抢到了锁b
Thread-1 释放了锁b
Thread-1 释放了锁a
Thread-1 抢到了锁b
Thread-1 抢到了锁a
Thread-1 释放了锁a
Thread-1 释放了锁b
Thread-2 抢到了锁a
Thread-2 抢到了锁b
Thread-2 释放了锁b
Thread-2 释放了锁a
Thread-2 抢到了锁b
Thread-2 抢到了锁a
Thread-2 释放了锁a
Thread-2 释放了锁b
信号量
Semaphore
互斥锁:只有一把锁,只能一个人去使用
信号量:可以自定义锁的数量,提供多个人使用
# coding=utf-8
from threading import Semaphore,Lock
from threading import current_thread
from threading import Thread
import time
# 信号量:提供5个锁
sm = Semaphore(5)
# 互斥锁:提供一个锁
mutex = Lock()
def task():
sm.acquire()
print(f"子线程{current_thread().name}")
time.sleep(1)
sm.release()
if __name__ == '__main__':
for i in range(10):
t = Thread(target=task)
t.start()
# 五个五个执行
子线程Thread-1
子线程Thread-2
子线程Thread-3
子线程Thread-4
子线程Thread-5
子线程Thread-6
子线程Thread-7
子线程Thread-8
子线程Thread-9
子线程Thread-10
线程队列
FIFO:先进先出
LIFO:后进先出
优先级队列:根据参数中的数字字母排序,排在前面的优先级越高,优先取出
# coding=utf-8
import queue
from multiprocessing import Queue
# FIFO队列:先进先出
q = queue.Queue()
q.put(4)
q.put(2)
q.put(3)
print(q.get())
print(q.get())
# 4
# 2
# LIFO队列:后进先出
q = queue.LifoQueue()
q.put(1)
q.put(2)
q.put(3)
print(q.get())
print(q.get())
# 3
# 2
# 优先级队列
q = queue.PriorityQueue()
q.put(3)
q.put(2)
q.put(11)
print(q.get())
# 2

