
网卡软中断过高问题优化总结
问题
多核CPU游戏战斗服务器高峰期时会出现网络丢包, 发现CPU0软中断%si 过高,导致%id值过低触发告警
如下图,在线低峰期软中断%si 处理时间百分比高达20多,id值变低,服务器变卡和丢包,影响业务
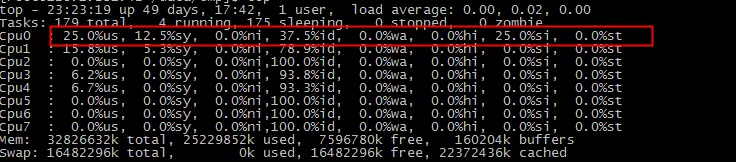
中断
什么是中断?
指接收来自硬件或者软件的信号发送给CPU和系统内核进行处理,发出这样的信号称为进行中断请求(IRQ)
中断又分为:
硬中断:外围硬件比如网卡发给CPU的信号
软中断:由硬中断处理后对操作系统内核发出信号的中断请求
查看中断情况即CPU都在哪些设备上干活
通过命令cat /proc/interrupts 查看系统中断信息,长下面这个样子的。
第一列是中断号,比如eth0对应的中断号是35,后面是每个cpu对应的中断次数。
CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU70: 127 0 0 0 0 0 0 0 IR-IO-APIC-edge timer7: 15 0 0 0 0 0 0 0 IR-IO-APIC-edge8: 182900 0 0 0 0 0 0 0 IR-IO-APIC-edge rtc09: 1 0 0 0 0 0 0 0 IR-IO-APIC-fasteoi acpi23: 18575 0 0 0 0 0 0 0 IR-IO-APIC-fasteoi ehci_hcd:usb124: 0 0 0 0 0 0 0 0 DMAR_MSI-edge dmar025: 132248 0 0 0 0 0 0 0 IR-HPET_MSI-edge hpet226: 0 0 0 0 0 0 0 0 IR-HPET_MSI-edge hpet327: 0 0 0 0 0 0 0 0 IR-HPET_MSI-edge hpet428: 0 0 0 0 0 0 0 0 IR-HPET_MSI-edge hpet529: 0 0 0 0 0 0 0 0 IR-HPET_MSI-edge hpet632: 0 0 0 0 0 0 0 0 IR-PCI-MSI-edge aerdrv33: 2735198364 0 0 0 0 0 0 0 IR-PCI-MSI-edge ahci34: 1 0 0 0 0 0 0 0 IR-PCI-MSI-edge eth035: 1157411688 0 0 0 0 0 0 0 IR-PCI-MSI-edge eth0-TxRx-036: 2199548159 0 0 0 0 0 0 0 IR-PCI-MSI-edge eth0-TxRx-137: 2210448541 0 0 0 0 0 0 0 IR-PCI-MSI-edge eth0-TxRx-238: 954381730 0 0 0 0 0 0 0 IR-PCI-MSI-edge eth0-TxRx-339: 3991435919 0 0 0 0 0 0 0 IR-PCI-MSI-edge eth0-TxRx-440: 2197207910 0 0 0 0 0 0 0 IR-PCI-MSI-edge eth0-TxRx-541: 2685654183 0 0 0 0 0 0 0 IR-PCI-MSI-edge eth0-TxRx-642: 2153260851 0 0 0 0 0 0 0 IR-PCI-MSI-edge eth0-TxRx-7NMI: 121456 40118 30875 24931 27000 26053 21459 19945 Non-maskable interruptsLOC: 3074687366 1216301963 1626527541 4049966581 4109422958 2708891166 1813301274 1373418058 Local timer interruptsSPU: 0 0 0 0 0 0 0 0 Spurious interruptsPMI: 121456 40118 30875 24931 27000 26053 21459 19945 Performance monitoring interruptsIWI: 0 0 0 0 0 0 0 0 IRQ work interruptsRES: 2454452061 1303706723 606598429 461072921 965186776 274559675 348785593 347963099 Rescheduling interruptsCAL: 216 682 679 680 583 683 667 668 Function call interruptsTLB: 19837873 5603975 5927817 4380569 12552909 11396903 7656446 6960058 TLB shootdownsTRM: 0 0 0 0 0 0 0 0 Thermal event interruptsTHR: 0 0 0 0 0 0 0 0 Threshold APIC interruptsMCE: 0 0 0 0 0 0 0 0 Machine check exceptionsMCP: 132236 132236 132236 132236 132236 132236 132236 132236 Machine check pollsERR: 15MIS: 0
CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7
35: 1157411688 0 0 0 0 0 0 0 IR-PCI-MSI-edge eth0-TxRx-0从上面可以看得到eth0的网卡中断次数最多,意味着中断请求都在CPU0上面处理,固然就会出现图1的情况
优化
Linux系统采用中断机制协同处理CPU与其他设备工作。网卡的中断默认由cpu0处理,在大量请求的网络环境下可能出现cpu0负载高,而其他cpu空闲。后来出现网卡多队列技术解决这个问题
RSS(Receive Side Scaling)是网卡的硬件特性,实现了多队列,可以将不同的中断次数分发到不同的CPU上。多队列网卡是一种技术,最初是用来解决网络IO QoS (quality of service)问题的,后来随着网络IO的带宽的不断提升,单核CPU不能完全处满足网卡的需求,通过多队列网卡驱动的支持,将各个队列通过中断绑定到不同的核上,以满足网卡的需求,同时也可以降低CPU0的负载,解决图1的问题
查看网卡是否支持队列,支持多少个队列
awk '$NF~/eth/{print $1,$NF}' /proc/interrupts37: eth0-TxRx-038: eth0-TxRx-139: eth0-TxRx-240: eth0-TxRx-341: eth0-TxRx-442: eth0-TxRx-543: eth0-TxRx-644: eth0-TxRx-7
以上网卡eth0为例支持队列,37-44是中断号, 一般现在主流网卡驱动都支持多队列,默认是7个队列
中断绑定
网卡支持了队列,意味着我们就可以绑定中断号与处理CPU之间的关系,
Linux系统默认使用irqbalance服务优化中断分配,它能自动收集数据,调度中断请求,但是它的分配调度机制极不均匀,不建议开启,为了了解中断绑定,我们把irqbalance服务关掉,手工调整绑定关系。
##相关配置文件:
/proc/irq/中断号/smp_affinity,中断IRQ_ID的CPU亲和配置文件,16进制
/proc/irq/中断号/smp_affinity_list,10进制,与smp_affinity相通,修改一个相应改变。
smp_affinity和smp_affinity_list修改其一即可,smp_affinity_list修改更方便
cat /proc/irq/37/smp_affinity01cat /proc/irq/38/smp_affinity_list01#上面表示01对应cpu0,可以直接修改绑定关系echo 0 > /proc/irq/37/smp_affinityecho 1 > /proc/irq/38/smp_affinityecho 2 > /proc/irq/39/smp_affinityecho 3 > /proc/irq/40/smp_affinityecho 4 > /proc/irq/41/smp_affinityecho 5 > /proc/irq/42/smp_affinityecho 6 > /proc/irq/43/smp_affinityecho 7 > /proc/irq/38/smp_affinitycat /proc/irq/37/smp_affinity_list0cat /proc/irq/38/smp_affinity_list1cat /proc/irq/39/smp_affinity_list2cat /proc/irq/40/smp_affinity_list3cat /proc/irq/41/smp_affinity_list4cat /proc/irq/42/smp_affinity_list5cat /proc/irq/43/smp_affinity_list6cat /proc/irq/44/smp_affinity_list7#此时中断号37、38对应的处理CPU为cpu1、cpu2,top命令查看%si是否均衡分摊到0-7核CPU
支持RSS的网卡,通过上面这种方法将不同的中断号绑定到每个CPU上实现了中断的分配。
RPS/RFS
虽然说RSS实现了中断的分配,但是如果队列数 < 机器总核数 并且CPU与中断号一一对应了,会出现软中断负载跑在0-7核上,其他核不处理软中断的情况,0-7核负载依然会很高。RSS需要硬件支持,在只支持单队列或多队列的环境中,RPS/RFS提供了软件的解决方案。
RPS(Receive Packet Steering)是基于RSS软件方式实现CPU均衡,接收包中断的优化,是把一个或多个rx队列的软中断分发到多个CPU核上,从而达到全局负载均衡的目的。
RFS(Receive Flow Steering)是RPS的扩展,由于RPS只是单纯的把数据包均衡到不同的CPU上,此时如果应用程序所在CPU和中断处理的CPU不在同一个核,将会对CPU Cache影响很大,RFS的作用就是将应用程序和软中断处理分配到同一个CPU
配置RPS
一个十六进制 f 表示四个CPU核,那么均衡到32核即ffffffff,经研究测试,最大只支持32核调度分配
rps_cpus='ffffffff'for rxdir in /sys/class/net/eth0/queues/rx-*doecho $rps_cpus >$rxdir/rps_cpusdone
配置RFS
RFS扩展了RPS的性能以增加CPU缓存命中率,减少网络延迟,默认是禁用的
/proc/sys/net/core/rps_sock_flow_entries
这个值依赖于系统期望的活跃连接数,注意是同一时间活跃的连接数,这个连接数正常来说会大大小于系统能承载的最大连接数,因为大部分连接不会同时活跃。推荐值是 32768
/sys/class/net/device/queues/rx-queue/rps_flow_cnt
将 device 改为想要配置的网络设备名称(例如,eth0),将 rx-queue 改为想要配置的接收队列名称(例如,rx-0)。
将此文件的值设为 rps_sock_flow_entries 除以 N,其中 N 是设备中接收队列的数量。例如,如果 rps_flow_entries 设为 32768,并且有 16 个配置接收队列,那么 rps_flow_cnt 就应设为 2048。对于单一队列的设备,rps_flow_cnt 的值和 rps_sock_flow_entries 的值是一样的
ls /sys/class/net/eth0/queues/rx-*|grep queues|wc -l8rps_flow_cnt=32768/8=4096echo 32768 >/proc/sys/net/core/rps_sock_flow_entriesfor rxdir in /sys/class/net/eth0/queues/rx-*doecho $rps_cpus >$rxdir/rps_cpusecho $rps_flow_cnt >$rxdir/rps_flow_cntdoneecho 32768 >/proc/sys/net/core/rps_sock_flow_entries
效果
RSS+RPS+RFS 优化过后可以看到软中断已均分到每个CPU上,%id值均匀,现在看已经是比较充分地利用多核CPU了,不用太担心单核出现高负载告警的问题。


