

用requests库的get()函数访问百度主页20次

import requests url = 'https://www.baidu.com' for i in range(20): response = requests.get(url) response.encoding = 'utf-8'#加编码方式,防止乱码 print(f"第{i+1}次访问") print(f'Response status: {response.status_code}') print(f'Text content length: {len(response.text)}') print(f'Content length: {len(response.content)}') print(response.text)
输出结果

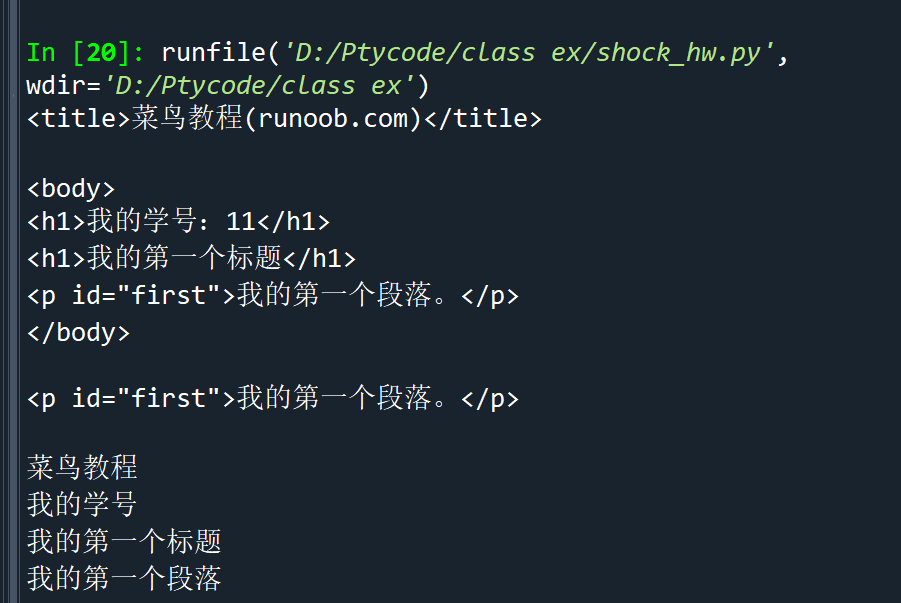
创建html文件(文件名:test1.html,路径:D:\前端学习\其他练习\test1.html)
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的学号:11</h1> <h1>我的第一个标题</h1> <p id="first">我的第一个段落。</p> </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> </tr> </table> </html>
代码
import re from bs4 import BeautifulSoup import requests with open('D:\\前端学习\\其他练习\\test1.html', 'r', encoding='utf-8') as file: r = file.read() demo = BeautifulSoup(r,'html.parser') print(demo.title) print("") print(demo.body) print("") # 获取id为"first"的标签对象 first_tag = demo.find(id="first") # 打印标签对象 print(first_tag) print("") # 使用正则表达式匹配只包含中文字符的文本 pattern = re.compile('[\u4e00-\u9fa5]+') result = pattern.findall(demo.get_text()) # 打印只包含中文字符的文本 for text in result: print(text)
输出结果
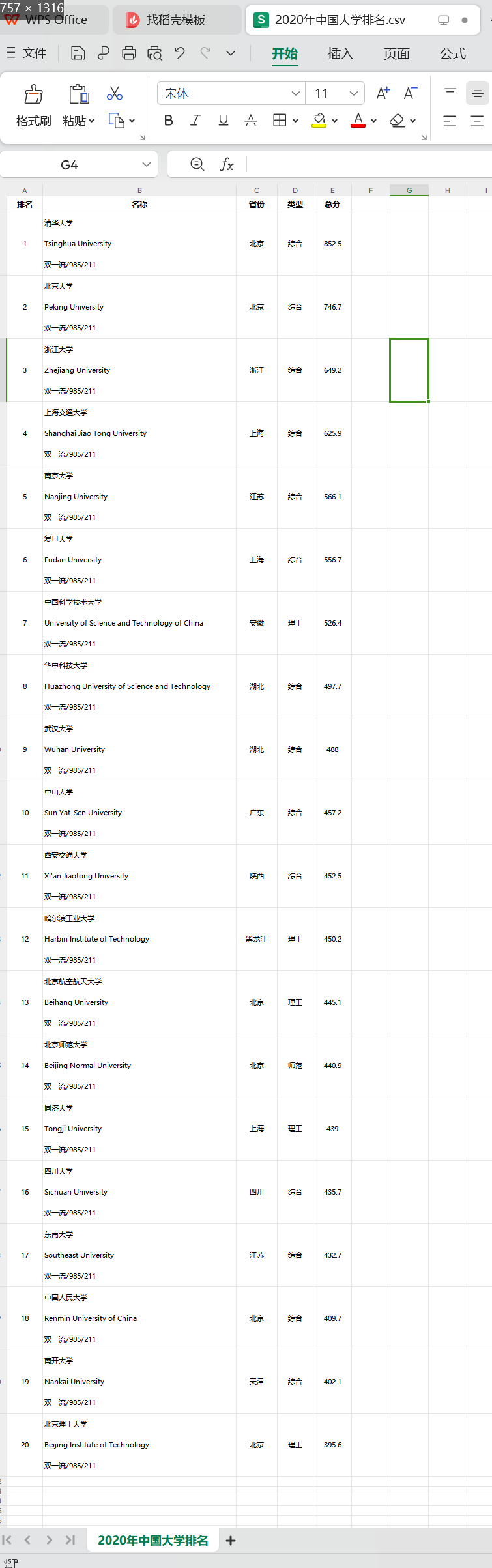
爬取2020年大学排名
import requests from bs4 import BeautifulSoup import bs4 import csv def getHTMLText(url): try: r=requests.get(url) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return '获取网页失败' def catchData(ulist,html): soup=BeautifulSoup(html,'html.parser') for tr in soup.find('tbody').children: if isinstance(tr,bs4.element.Tag): tds=tr('td') ulist.append([tds[0].text.strip(),tds[1].text.strip(),tds[2].text.strip(),tds[3].text.strip(),tds[4].text.strip()]) def writeList(ulist,num,year): f = open(year+'年中国大学排名.csv','w',encoding='gb2312',newline='') csv_writer = csv.writer(f) csv_writer.writerow(['排名','名称','省份','类型','总分']) for i in range(num): u=ulist[i] csv_writer.writerow([u[0],u[1],u[2],u[3],u[4]]) f.close() print(year+'年中国大学排名爬取成功') if __name__ == '__main__': year=2020 uinfo=[] url = 'https://www.shanghairanking.cn/rankings/bcur/'+str(year)+'11' html = getHTMLText(url) catchData(uinfo,html) writeList(uinfo,20,str(year))
输出结果




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!